
如果企业最看重价格,大可选择API调取完全免费的开源大模型。但要真正落地应用,开发者需有部署、调优、算力等工程化能力,对于绝大部分企业,尤其中小企业来说,无疑是一道较大的门槛。
©️懂财帝出品 · 作者|嘉逸
因为价格战,文学作品、1元成了AI大模型行业的通用单位。
只需花1元钱,就能让字节的豆包大模型生成3本《三国演义》,让阿里云通义千问生成2本《埃隆·马斯克传》,至于百度文心一言,想生成多少本就多少本。
在最烧钱的行业爆发价格战,意味着厂商进一步加速商业化。但厂商不打无准备的战,降价的前提,是技术改进带来的降本增效。
而且,性能最强大的大模型不在降价范围之内。
厂商精明,企业也不笨。面对价格战,企业愿意试用,但要掏钱买单,企业看的还是大模型的质量。
现阶段,谁都没有护城河,比价格低也许是厂商能想到的唯一办法。当然,价格不会是用户决策的决定因素。
01|“免费”背后的玄机
天下没有免费的午餐,各厂商降价或免费开放的大模型,更多只是“开胃小菜”,主菜仍要用户买单。
5月6日,量化私募巨头DeepSeek把旗下大模型DeepSeek-V2-32K的价格降到了输入1元/每百万tokens、输出2元/每百万tokens,性能号称对标GPT-4,价格仅为GPT-4的近1%,另白送开发者500万 tokens。
智谱AI第一个表示不服,在5月11日调整了入门级大模型GLM-3-Turbo-128K的价格,从5元/百万tokens降至1元/百万tokens;新注册用户获赠的免费tokens,由500万升至2500万。
小厂没掀起什么水花,等到大厂下场,这场价格战才算迎来高潮。
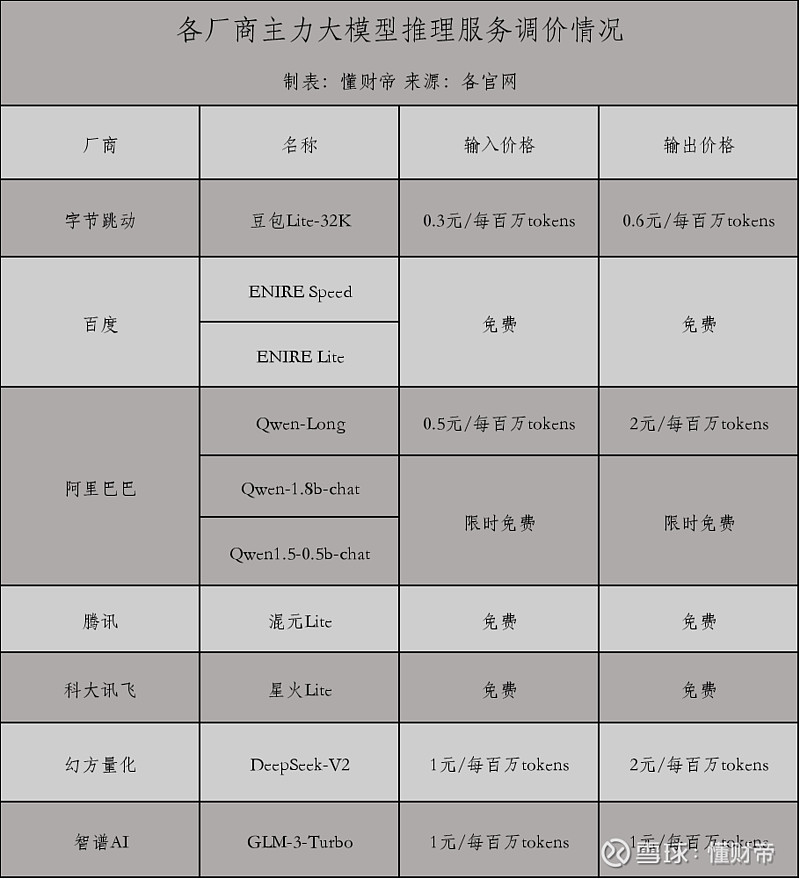
5月15日举行的火山引擎原动力大会上,发布了系列“白菜价”大模型,最便宜的豆包-lite-32K大模型输入价格仅需0.3元/百万tokens,输出价格为0.6元/百万tokens,并强调“自己最低”。
被“背刺”的同行坐不住了,5月21日阿里云通义千问9款模型降价,其中,号称对标GPT-4的主力模型Qwen-Long的输入价格从20元/百万tokens降至0.5元/百万tokens,降幅达97.5%,反将字节一局。
然而,Qwen-Long并不是阿里最强大的模型,性能更好的通义千问Max降价幅度为67%,Qwen1.5-32B、Qwen1.5-110B设定为限时免费。
阿里云宣布降价不到4小时,百度便官宣文心大模型两大主力模型ERNIE Speed和ERNIE Lite免费。这两款均属于轻量级模型,优点是响应速度快,但适用于精调,精调需要收费。
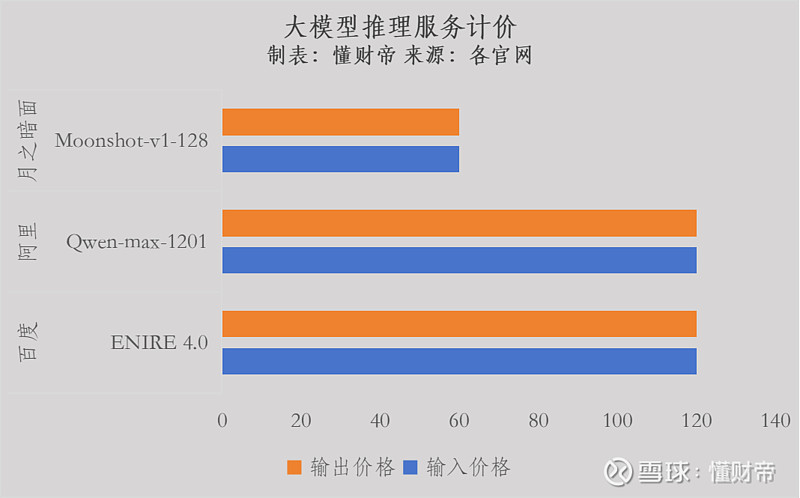
而百度最强大的文心一言4.0大模型价格不变,仅看绝对值,其定价位居业内前列,每百万tokens收费120元。
腾讯和科大讯飞也采取类似的策略跟进,轻量级模型免费,高性能模型降价。
5月22日,腾讯云把主力大模型混元lite的价格,从8元/百万tokens调整为免费,并给新用户提供10万tokens文本生成的免费体验额度。支持上下文32K的混元-standard和混元-pro大模型,打了个6.9折,输入价格和输出价格调整为6.9元/百万tokens。
科大讯飞的星火lite同样免费,但上下文仅支持8K,性能难以在实际的生产环境中运行。
面壁智能推出“不降价,0元不限量”活动,原因是其大模型本身免费开源,且部署在端侧,利用终端设备算力,无需调用云端API,算力成本远低于同行。
《明朝那些事儿》里有句经典台词:要么不做,要么做绝。但大模型价格战表面看似热闹,实则隐藏着诸多算盘。
底层通用大模型多采用开放API接口的形式,按实际消耗或调用的tokens量计费,厂商根据问答内容的特征、模型算力消耗等因素,一般会把定价分为输入、输出价格。
而厂商能从企业用户赚到的钱,远不止API接口调用费。如果企业从厂商购买了大模型服务,要经过部署、精调、评估、数据管理、插件调用等诸多环节,每个环节都会产生相应的费用。
可以说,这场价格战的逻辑是先让企业免费上车,尝鲜体验高端服务,进而引流到其他收费项目,或者跳转到更高端的服务项目。
厂商卷低价,更意在云服务。和大模型尴尬的商业化处境不同,国内的云市场经过多年的发展,已有较明确的盈利模式。通过大模型的“让利”,与云服务捆绑销售,结果很可能是共赢。
这也解释了,为何DeepSeek、智谱降价,大厂都没什么反应,火山引擎一降价,大厂就忙着反击。正是因为火山引擎具备云服务能力,动了阿里云、百度智能云在云计算领域的蛋糕。
例如,阿里云在大模型降价的第二天,便推出了上云优惠套餐,首次推出5亿元算力补贴,为200余款云产品制定折扣价等,其中就包括大模型训练与推理的相关产品。
相比之下,缺乏云服务的初创公司“按兵不动”。百川智能、Minimax、月之暗面、零一万物等明星初创公司均维持原价。
整体来看,目前降价或免费的大模型只是少数。毕竟,整个2023年,国内企业发布的大模型数量超过130个。
02|是信心满满还是底气不足?
虽说字节在“挑事”,但这场价格战,其实很大程度是被美国的OpenAI“逼”出来。
追赶美国,向来是国内头部大模型玩家们的目标和共识。以OpenAI为标准,国内公司先是成功地追平了ChatGPT3.5,然后正逐渐缩小与ChatGPT4.0的差距。
OpenAI创始人奥特曼曾许下承诺,要每三个月降价一次,他也确实在兑现诺言。2023年初以来,OpenAI已4次降价,而且在不断迭代技术。
最新发布的GPT-4o性能比GPT-4 Turbo出色得多,速度快2倍,价格却减半,甚至有免费额度,和国内价格战的招数类似。
在OpenAI技术持续绝对领先、频繁降价的压力下,国内大模型公司决定放手一搏。但厂商并不盲目应战,大模型推理成本的大幅下降,是各家竞争的最大信心来源。
李彦宏曾公开表示,与一年前相比,文心大模型的推理性能提升了105倍,推理成本则降到了原来的1%。
天风证券近期发布的研报指出,受益于AI对云驱动影响和文心大模型系列推理成本显著降低,叠加轻量模型相较开源模型优势,百度云业务额外收入增量重心由模型训练过渡到模型推理,推理成本显著降低带来的增量反哺云业务。
火山引擎总裁谭待也提到,将用混合专家架构(MoE)、分布式推理等技术手段优化推理成本,节省算力耗费,“用亏损换收入是不可持续的,所以我们从来不走这条路”。
阿里云通过构建弹性的AI算力调度系统,结合百炼分布式推理,提升了引擎效率,有效降低了边际成本。
在一定程度上,这场价格战也暴露出大厂的高度焦虑感。众所周知,同质化严重是国内大模型行业的通病,各家性能趋同,谁也拿不出杀手锏。
即使百度和阿里领先,但与其他厂商的技术差异性并没有拉开足够的距离,市场也持这样的看法。体现在B端企业用户规模方面,百度10万,阿里9万,相差不大。
卷参数规模便是典型的例子。只要一家厂商推出百亿参数的大模型,很快市场就会涌现一堆同级别的产品,不久就会出现更大参数的大模型。
卷完参数规模,厂商就卷长文本处理能力。之前,凭借处理200万字的长文本推理能力,月之暗面公司的Kimi Chat引爆市场,融资规模随之水涨船高。
Kimi的优势没维持多久,就被阿里、百度等大厂抹平,百度升级至200万—500万字之间,阿里通义千问更是祭出1000万字长文本的大招。
03|商业化大冒险
“今天企业在使用AI的时候,并不是成本驱动的。”这是阿里巴巴原副总裁贾扬清引用过一位国际顶级咨询公司CIO的话,也是业内的普遍观点。
零一万物创始人李开复和百川智能创始人王小川均反对价格战,认为成本并不是客户选择大模型的唯一因素,性能优势是关键,还要把市场、安全、需求等方面纳入综合考虑。
“对需要最好模型的客户来说,购买100万个tokens的资源包,支付几元和支付十几元,差别不大。”李开复直言。
显然,如果企业最看重价格,大可选择API调取完全免费的开源大模型。但要真正落地应用,开发者需有部署、调优、算力等工程化能力,对于绝大部分企业,尤其中小企业来说,无疑是一道较大的门槛。
这也是为什么国内很多大模型开源这么久,依然没有大规模落地B端的重要原因。企业自己没搞清楚大模型到底有什么用、怎么用,大模型厂商也未能很好地帮助企业弄懂这一点。

在业内,模型效果、推理成本、落地难度被称为AI三要素,为企业选择大模型的三大标准。其中,模型效果是首选因素,也最难实现,因为质量好的数据,比算力还昂贵。
B端对数据的专业性要求非常高,各行业各有应用场景,甚至同一行业的不同企业都有差异化明显的应用场景。而目前各家大模型主要是通用大模型,数据与行业场景不匹配,自然无法让企业买单。
因此从商业策略角度看,大模型厂商竞相降价或免费,本质是一场数据之争,希望以此吸引更多的开发者和企业,收集到更多行业场景数据。
价格战的另一个直接影响是,或将激活AI应用市场,形成良性的生态。大模型热潮一年多以来,大模型的参数纪录不断被刷新,效果持续得到改善,应用端却鲜有惊艳产品。
过去tokens费用较高,应用开发者不太愿意承担创新风险。现在tokens白拿,开发应用的试错成本势必有所下降。
火山引擎总裁谭待认为,早在去年下半年,各家就开始卷应用,今年一个很大的变化在于行业大模型能力大幅提升,做应用这件事变得很重要。
除了降价,火山引擎也展示了其商业化路径,通过打造众多爆款AI应用产品,来覆盖行业需求,获得更丰富的数据。字节推出了AI应用开发平台“扣子”、互动娱乐应用“猫箱”、AI创作工具“即梦”等产品,嵌入抖音、飞书、巨量引擎等50余个业务。
这表明,虽然大模型商业化仍然很难,但方向已经变得清晰。有人会疑惑,大模型的价格战是否来得太早?其实不然。
由于迁移成本非常大,大模型的用户粘性很高。多家使用百度文心4.0大模型的公司表示,即使有更便宜的大模型可供选择,也不会轻易更换。一则该大模型已足够强大,二来在前期调试阶段付出了很多精力,再重来一遍,时间、人力、资金等各项成本都太高。
这也意味着,厂商能抢到的企业,基本是新客,难以从别的厂商“夺食”。越早吸引到用户,越有优势。
对于不想降价的大模型创业公司,也无法完全置身事外。大模型烧钱,融资规模却在降温。
据研究机构CB Insights发布的《2023年人工智能(AI)行业现状报告》,2023年中国AI领域投融资数量约为232笔,同比下降38%;融资总额约为20亿美元,同比下降70%。
李开复称自己做大模型,十年不会套现,其他投资者未必有这样的耐心,创业公司肯定要找到赚钱办法。
Kimi爆火以后,出现高峰期算力不足。近期,Kimi尝试测试付费打赏功能,想通过卖算力保障来赚钱。
在商业化面前,大厂和小厂分别走上了不同的冒险征途,最先挖到“金矿”的,一定是装备最强的那家。
说明:数据源于公开披露,不构成任何投资建议,投资有风险,入市需谨慎。
—END—
「点赞」「在看」与 「分享」,你对作者最大的支持。
