1.如何把获取到的json数据转换成dataframe
果然还是基础薄弱哈哈,就这一个小问题折腾了几个小时。最后一个函数就搞定了。
集思录拿到的数据长这样:
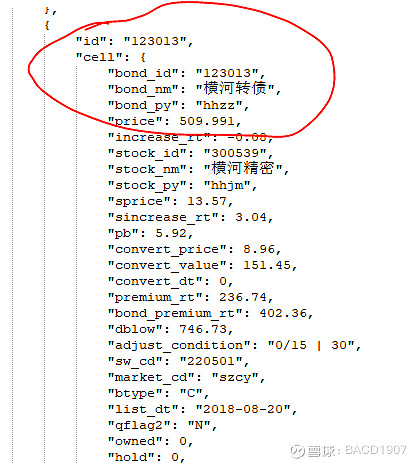
注意红圈那里,这个数据是个json,想要直接转换成dataframe,相当于要提取key字段作为列名,然后把所有的value字段作为每一行的内容。
折腾了半天没搞定,最后搜到一个链接:
里面提到:
pandas中有一个牛逼的内置功能叫 .json_normalize。
pandas的文中提到:将半结构化JSON数据规范化为平面表。
试了一下果然好使,就是找到的过程比较曲折。
—————————
2023.4.2
写了点代码又遇到了一堆坑。
今天主要想解决过滤掉未上市转债的问题,思路是遍历dataframe,然后如果成交量字段为0,就过滤掉,这样可能会过滤掉一些停牌的转债。
想了想找到一个字段'price_tips',这个还没上市的话,值就是待上市。
另外对集思录可转债key的一些理解。
volume是成交量,svloume是正股成交量,正股相关的都会在前面加个s,不知道是啥的缩写。
今天遇到的坑主要是删除行,就是判断出这是未上市转债,然后想从dataframe里面把这行删掉。
搜了一下方法很简单,df.drop就行,但是这函数用法很多,教程乱七八糟,试了半天,发现可用的是:
df.drop(index=1)
这个表示删掉行索引为1的行,但是这里有坑需要注意。如果直接这么使用,需要进行赋值,也就是df = df.drop(index=1),因为默认是结果在返回值里面,不修改源数据。
如果不赋值,就需要加个inplace参数。
df.drop(df.index[0], inplace=True) # 删除第一行
就是因为这个坑折腾了老半天。
然后,还有坑。
刚开始本来尝试过df = df.drop(index=1)这种用法,理论上也删除成功了。
但是当时观察输出的新dataframe,发现总行数是一样的,就觉得没生效,实际上是生效了的,但是因为没有重置索引,所以看到最后一行的index还是一样的。
——————————-
2023.4.3
又写了一会,各种坑,就是想排个序,写了半天都不对。
这是对的,使用列标签为rank的列的值进行排序:
df = df.sort_values(by="rank", axis=0, ascending=True)
之前试了
df = df.sort_values(by=df['rank'], axis=0, ascending=True)
就不行,报错raise KeyError(key)
奇奇怪怪的,查了也没查到,现在想一想应该是说那个df['rank']不能作为一个key来使用吧,相当于把df['rank']这里面的值,拿去当列标签找,找不到。
这报错报的真抽象。
———————-
2023.4.9
今天想获取一下强赎数据。
就想着改一下之前获取集思录转债的代码拿来用。
用F12看了一下数据包,差不多,就是页面名称差一点。
这个改了一下。然后负载也有一点差距,少了几个字段,改了一下应该也好了。
然后获取了好多次,打印出来的都是个response 200,就是下面这段代码。
res_redeem = requests.get(url_redeem, headers=header, cookies=cookies, data=data_redeem)
print(res_redeem)
然后一直以为是数据包组的有问题,试了几次还是不行,就去搜了下,发现不少人遇到了同样的问题。
最后这个大佬回答的比较靠谱:
……网页信息在requests.get(xxxx).text里。
好好看requests的文档。
get返回的是一个response对象,里面有各种变量,你需要的是其中叫text的那一个。你直接print这个response对象的结果完全取决于开发者对__repr__或者__str__的重写情况。
是打印的问题,打印text就可以了。
———————————-
2023.12.7
今天刚好有时间,想修改一下告警,之前的虽然能跑,但是看到那一堆告警太难受了。
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead
基本上都是这个告警,意思就是我类似C语言的二级索引用法不好,需要换成.loc。
AI的解释:
是由于Pandas在执行赋值操作时,可能会产生一个DataFrame的副本,而不是直接在原始DataFrame上进行修改。当警告出现时,它提醒你可能存在一个副本,而不是在原始DataFrame上进行修改。
当你尝试将df_actual['当前持仓'][j]的值赋给df_result.loc[i, 'amount']时,如果amount列在df_result中不存在,Pandas会尝试创建一个新的列并将值赋给该列。然而,由于某种原因,Pandas可能会认为这是一个副本而不是原始DataFrame,因此会发出这个警告。
也就是需要把二级索引换成df.loc,这个倒是好换,很快就换完了。但是还有个很难受的地方,就是有一行代码,我新增了一个列,然后赋值给这个列,这里改为df.loc也没用,还是报这个错误,如果换成已有的列就没事,搞不懂为啥。