Cuda是什么?
英伟达在2006年推出了CUDA(Compute Unified Device Architecture,统一计算结构),CUDA处于软件层面,作用是帮助使用者直接访问 GPU 的虚拟指令集和并行计算元素,以执行计算内核(kernel)。其原理可以理解为:GPU有更多的核数,如i9-13900处理器性能核数为8,总线程(thread)数32。

显卡内部,有三级结构:网格(grid)、块(block)、线程(thread)。每个显卡只有很少的网格,一个核函数目前只能运行在一个网格中,而一个网格里有多个块,每个块包含了若干线程。
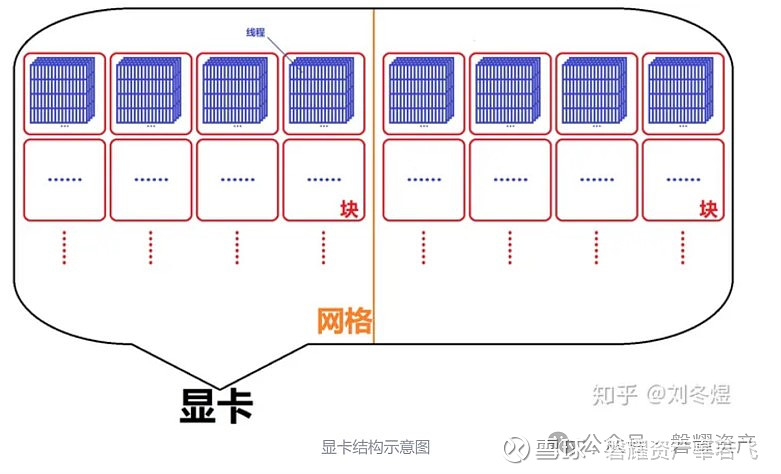
与CPU相比,英伟达Geforce RTX 4070拥有5888个CUDA cores,对应46个多元处理器(Multiprocessors),每个多元处理器可以运行多个CUDA Block,具体取决于CUDA块所需的资源,每个CUDA Block可以运行最多1024个线程,每个线程都可以进行独立计算。而每个内核在一个设备上执行,CUDA 则可以支持同时在一个设备上运行多个内核,因此使用GPU以及CUDA可以快速加速运算过程。

CUDA生态及优势究竟在哪?
不同领域厂商的开发框架需求是不同的,例如汽车厂商需要车辆物理仿真,车辆感知和决策,而生物科技厂商需要不同蛋白质特性分析,不同细胞分割,需求是多样的。数据读取,模型形态,训练标签,训练方式,结果展示方式都是不同的,而在产业AI化发展期间,这些需求一定程度上对于下层是不通用的,没有统一的标准。
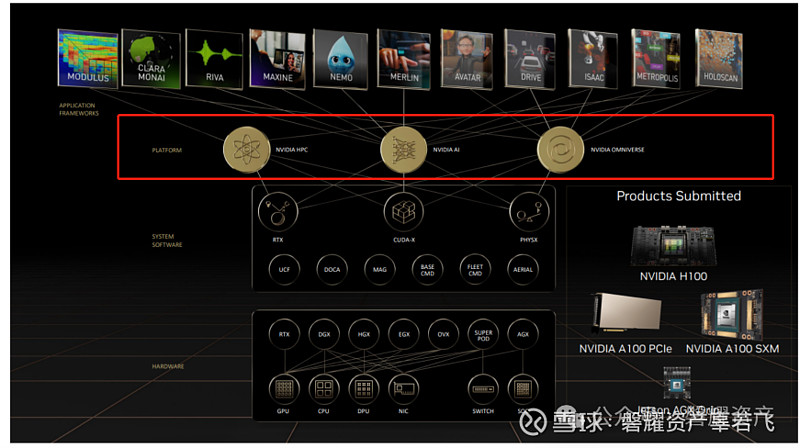
另一方面,在同一个领域不同厂商之间,例如,奔驰和奥迪并不需要在通用的pytorch或者tensorflow开发框架上进行自己的软件车载控制开发,nv已经将一些自动驾驶所需要的功能例如场景生产和模拟,加入应用框架,意味着不同的汽车公司不用从最原始的通用平台开始搭建自己的软件,否则会导致性能不一致,导致各种divergent需求传导到nv端。另一方面,nv为了细化需求,为不同厂商也开源了部分代码或者API,使他们可以定制自己的需求,为此Nvidia打造了14种应用程序框架。
应用程序框架:

软件平台:
软件平台代表了整个生态的业务方向。为软件栈提供封装集成平台。
HPC,高性能计算
AI,人工智能
Omniverse,3D协作和模拟
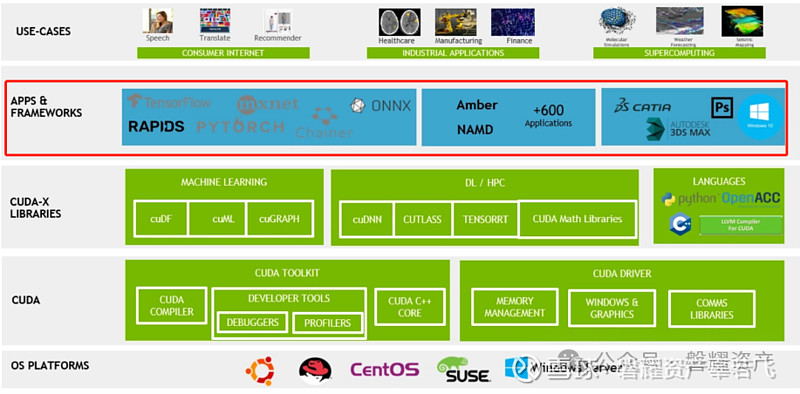
这一部分是CUDA环境的核心部分,也是芯片厂商需要与软件平台及框架相互配合的部分,也是为什么NV的先发优势可以大幅领先友商AMD ROCm的核心因素,算子库一部分是芯片厂商自己针对硬件实现优化后的算子。比如CUDA 中的 cUDNN 和 cuBLAS(具体使用的算子库将在下节提到),他们与特定的硬件有深度绑定和深度优化。结合框架层面,当英伟达推出一个新的硬件时,他能够快速地将 CUDA 升级成新的版本,以适配新的硬件,比如推出了H100,可能会增加一些针对Transformer 特定算子的硬件单元,整个算子库需要做调整,对 H100 的算法进行优化或增加新算法,用户在框架上看不到这些变化。问题是框架层能否快速兼容新的硬件,比如Pytorch,PyTorch 和英伟达,PyTorch最初做出来时就是在 N卡上实现的。所以对 N 卡的支持最积极、最及时。但对于 ROCm,2023 年下半年AMD 发布了 M1300,ROCm 已经更新到 6.0.0 和 6.0.1,但 PyTorch 只适配到了 ROCm 的5.4.2,连 5.6.0 都没有。而且算子库、数据库与软件栈有关联关系,导致框架无法及时适配最新的软件栈或算法数据,所以ROCm 在这方面存在较大的风险。AMD 最新的 790 卡在 PyTorch的 2.0或2.1 上不能用,而且无论是AMD 还是PVTorch 官方,都没有提供一个兼容最新版本的PyTorch 安装包。
NV与其生态中的软件平台厂商是相辅相成的,目前 PyTorch 只会适配 N 卡,和 N 卡适配的积极性和及时性是最高的。对包含 AMD 的其他厂家都不是这么积极。PyTorch 官方不会主动适配 A 卡,需要 AMD 等芯片厂商主动去适配PyTorch 最新的版本或者 TensorFlow 最新的版本。当新出硬件或者 PyTorch 新发布的版本,如果变动比较大,芯片厂商主动要去适配 PyTorch。至于能不能在他的官方发布版本里面体现,也取决于公司的实力。
Libraries(库):
许多库都拥有标准的应用程序接口(API),因此只需修改极少的代码即可实现加速。
程序库为多种领域的应用中的函数提供高质量的实现方式。
CUDA各类的函数库是CUDA软件框架层面的底层,也是核心,NV在硬件与软件均花费了大量的时间打造,才出现了现在所看到的CUDA。CUDA目前拥有针对多种领域的数据库,比如其中CUDA-X是包括人工智能和高性能计算在内的各个应用领域中的函数库、工具和技术的集合。CUDA-X拥有包括数学数据库、平行算法、图形与视频数据库、计算光刻以及深度学习等领域,用户可以获得不断扩展的算法集的高度优化实现。


ROCm的前世今生
ROCm并不是AMD的第一次尝试,早在2008年为了应对CUDA,AMD推出了其旗下的“Close to Metal”计划,但并没有在市场拥有太大的反响,随后又在2014年HAS(Heterogeneous System Architecture),但此架构由于在行业中并没有被广泛使用,一直处于停滞状态。最后,AMD在2016年推出了现在的ROCm,一个Linux系统上的 GPU 计算开源平台。ROCm提供了编译器、库和HIP编程语言等工具。HIP被设计为一个 "可移植性平台",一个CUDA的复制体,允许开发人员以最小的改动移植他们的 CUDA 代码。
CUDA vs ROCm
性能与用户体验方面: 相较于CUDA,ROCm的起步较晚,再加上AMD的研发实力也不如英伟达强劲,所以软件栈的丰富度和好用程度相比英伟达的CUDA来说要差很多。并且AMD芯片本身的迭代速度和算力,与英伟达的迭代速度和架构变化发展相比也有不小差距。这一系列因素导致无论是AMD还是国内做GPU 的芯片厂商,想用ROCm开源软件栈兼容CUDA方案去做AI技术软件栈都很困难。
总体来说,应该有的东西ROCm基本上都已经有了,比如软件生态中的硬件、AI 软件栈、驱动、运行时间模型、加速库、开发环境和工具包,不过相对来说使用人群较少,导致没有那么好用。国内做Android手机操作系统的厂商,尤其是像华为的鸿蒙OS,其实2010年Android操作系统刚推出时也非常难用,现在这么好用是因为在使用中不断发现问题,并持续进行优化,类似于这样一个过程。
ROCm没有踩在合适的时间点,相对落后于CUDA,再加上AMD对ROCm卡的支持欠缺。所以目前使用AMD这套来进行AI模型的训练和推理并不是特别好的选择。
从这个角度来看,训练和推理的计算复杂度不同。ROCm 和 CUDA 在使用的层面还存在不小差距。比如在 PyTorch 上训练一个模型或者用PyTorch 构建一个模型结构,发现他不能满足要求,想把他迁移到其他框架中进行训练,对于CUDA 生态来说,有很多工具和方法可以实现模型在不同框架间的迁移。
而 PyTorch 训练好的模型,需要落地做推理,CUDA 也有很多丰富的工具和组件,即之前提到的 AI 软件栈组件,可以帮助开发者在 N 卡上或国内其他专门做推理的芯片厂商的卡上运行模型推理,CUDA 都有相应的工具来实现。而 ROCm 对于目前主流的深度学习框架来说确实存在一定差距和代沟,在 PyTorch、TensorFlow 有适配 ROCm 的工具,但在一些小众的深度学习框架,像 MSI 以及百度、飞桨 PaddlePaddle 等都没有。这导致高校或者公司在一些比较小众的场景时,没有使用 PVTorch,使用了 MSI、百度、飞奖PaddlePaddle 等小众学习框架,这时如果用ROCm 做训练或做云端、边缘端甚至终端的推理,无形中就增加了很多门槛,甚至完全不可用。所以从生态的角度来讲,ROCm 还是有不少的工作要做。
架构方面:在 2014 到 2015 年的时候,N卡做AI的人工智能的高性能计算也是 Pascal 架构,在这之后,他针对 AI 领域做了专门的架构设计。当然也可以全部在图形图像的处理显卡上面运行,这也没有问题。因为 N 卡本身积累的时间比较长,但是 A 卡没有这样做,是因为他一直在做图形图像处理 GPU 部分,再加上图形图像处理在芯片的设计上面有很多的硬是为了做图形渲染而设计,并不是为了做 Al 通用计算去设计的,导致他做通用计算并不是那么理想。
第二个是 ROCm 本身推出时间不长,也没有大量用户使用和反馈,导致 ROCm 前些年并没有特别积极推动。最近这几年 ROCm 才开始去做,所以目前并没有全产品系工作支持。从难易程度来讲,对于 AMD 来说还是存在挑战,因为过去的芯片架构一直在变,英伟达和 AMD 都推出了一系列的架构,所以从技术角度来讲,兼容性是一个比较难的问题。
比如在 MIO 中写了一个人工智能的算子库,不一定能在比较早的老芯片上运行,这是比较难的兼容问题。所以如果要做,就需要对 ROCm 整个框架做一些调整,或者对过去的产品做一些梳理,抽象出一个类似于 PTS 的虚拟指令集,来实现产品的兼容性,这样才能更好地适配不同的产品系列,这部分还是有一些阻碍的。
但从ROCm与CUDA编程的角度来讲,迁移成本比较低,因为 HIP 本身是模仿的 CUDA 的API 去实现,所以他们的 API 的接口和参数大部分相同。对于用户来说,无论是在 CUDA 上面写,还是在 HIP 上面写,或者说 CUDA 写好了迁移到 HIP 上,都相对容易一些。
未来展望
NV:未来从CNN迁移到Transformer架构对CUDA的影响有限,CNN (图像卷积神经网络) 是在做 CV (图像处理) 领域的最优选择,无论是从性能,还是从内存占用、准确性、精度这几个角度来讲,CNN 在图像领域目前还是无法被替代。目前一些科研机构和企业,也在研究利用 Transformer,将这个新的 AI 技术推广到图像识别领域但距离能够商用还是有一些差距,Transformer 在一些特定的领域,像 NLP 自然语言处理这种带有持续性问题,是最优的模型。图像的持续关联相对更弱一些,但是有一些领域会有持续关联的问题,用 Transformer 会更好一些。
从 CUDA 的角度来讲,Transformer 影响不是很大,反而对 CUDA 有利好。首先CUDA 的并行计算本身就比较适合矩阵乘。英伟达的硬件设计能力比较强,像 H100 的 Hpper 架构就实现了针对 Transformer 的矩阵乘的硬件计算单元,而不只是 Tensor Core,变相加强了Transformer 出来之后他的芯片能力。
相比于国内的地平线、寒武纪、华为等,更多是在 CNN 或者 RNN 模型里面抽象出基础算子去做向量或者矩阵乘的计算单元,因为芯片的架构不一样,寒武纪更多走的是电子的架构,直接在芯片里面设计矩阵乘和计算单元,但是编程的通用性和指令的完备性相对于 GPU 来说比较差,所以在某些特定的领域,像做归一化、池化、激光激活的全连接,他的计算能力就比 N 卡差。所以对 CUDA 的影响不大,反而有利好,但是对于 AI 计算的芯片架构,会有新的挑战。
英伟达可能在3 年前甚至5年前就已经发现这个趋势了,英伟达目前生产一代,设计一代、预研一代,2024 年可能已经在做 2026 年、2027 年的芯片预研,所以英伟达会充分地调研市场上可能出现的、新的 AI技术和框架。加上英伟达庞大的用户基数的反馈,所以其他公司想和英伟达拉近距离并不是那么容易。再加上英伟达的软件栈和研发能力,单纯看可能有利好,但是整体对比,不见得对其他芯片公司有利好。
结论
目前英伟达在人工智能领域的市场壁垒短时间内还是无法被撼动。再加上英伟达超强的研发能力和芯片设计能力,对于国内初创的芯片公司来讲,虽然是一个机会,但并不见得他们能够利用好这一次机会拉近和英伟达的距离。英伟达本身就已经是国际上最著名的公司,所以不管是高校还是企业,天然地就会选择 N 卡。从这个角度来讲,英伟达赶上了这一波风口浪潮,再加上CUDA 做并行计算的研发时间要早很多,就带来了这种无与伦比的优势。再者,多年来英伟达在这个方向上持续进行研发投入、高校和企业持续应用 CUDA,对其生态的发展都做出巨大贡献,导致目前无论是做训练还是做推理,CUDA 都是最优选择。
ROCm对比 CUDA,在架构方面与CUDA还有一定的差距,ROCm希望用兼容CUDA的方式快速弥补双方的差距,但毕竟 ROCm 是去兼容 CUDA,所以肯定会相对落后,不可能超越保持齐平都非常难,能和 CUDA 差一代已经是目前较好的情况之一。再加上英伟达超强的研发实力和CUDA 不开源的部分,比如有一些可能不兼容 PTS,而是针对特定版本特定芯片直接用底层的汇编去写,就无法实现兼容,这就导致不一定能直接拿过来就用,即使能用,性能也会较 N卡有比较大的波动、这是他不可避免的问题。长期来看,CUDA在AI与高性能计算方面的先发优势太大,ROCm若想弥补两者的差距还需要不少的努力。
因此CUDA生态的存在也造就了英伟达在AI领域当下的绝对霸主地位,而其他的厂商如若想要兼容乃至超越CUDA所带来的领先优势,所需要花费的代价将会巨大。因此我们也看好海外英伟达产业链在国内外带来的巨大的投资机会。
(完)
近期原创链接:
【磐耀周评】猪价旺季不旺已成定局,关注节后价格情况
【磐耀周评】市场震荡磨底 把握超跌弱周期和战略新兴板块
【磐耀周评】《网络游戏管理办法》后的游戏、AI、A股市场
【磐耀周评】浅谈创新药研发的基本流程
【磐耀周评】生猪产能去化有望加速
【磐耀周评】AI大语言模型公司简析:竞争格局、盈利模式与估值
【磐耀周评】医疗反腐不必恐慌,底部孕育大机会
【磐耀周评】A股历史上的政策底与市场底,以及当下的市场展望
【磐耀周评】政策底向市场底过渡 积极储备未来成长方向
【磐耀周评】存量之下,人工智能增量方向变得更加珍贵
【磐耀周评】关注存储器板块投资机会
【磐耀周评】关注特纸板块盈利修复
【磐耀周评】医药底部寻金系列——一次性手套
【磐耀周评】分歧之下人工智能行情将何去何从
【磐耀周评】市场即将迎来新一轮布局机会
【磐耀周评】关注IOT方向的布局机会
【磐耀周评】重视中药板块的投资机会
【磐耀周评】居民负债的稳定对经济中长期发展至关重要
【磐耀周评】一季度A股有望迎来普涨行情
磐耀资产2023致投资人的一封信
【磐耀周评】2023年展望
【磐耀周评】外需下滑,内需顶上
【磐耀周评】预期修复渐入尾声
【磐耀周评】消费调整原因以及后续投资展望
【磐耀周评】坚定信心 顺势而为
【磐耀周评】时代的投资方向之一——科创高端制造
备注:
如果您觉得本公众号内容对您有所启发
欢迎转发或转载
您的支持是我们工作最大的动力!
上海磐耀资产管理有限公司成立于2014年12月4日,于2015年3月成为中国基金业协会认定的私募投资基金管理人。公司总部位于中国上海,发行基金产品数量超过百只,是一家以股票多头为主的私募基金公司。凭借优秀的长期业绩表现,公司曾连续荣获中国证券报金牛奖、证券时报金长江奖、上海证券报金阳光奖、基金报英华奖以及多家机构的评选奖项。