核心观点
MI300在AI正面交锋英伟达,AMD能否复制16年CPU突围战的成功?
AMD曾在2016年通过Zen架构及领先制程计划,颠覆英特尔一家独大的局面,并开始蚕食其CPU市场份额。随后,AMD在2018年PC端制程首度弯道超车英特尔,市场份额加速提升;19年联手台积电,率先跃入7nm制程,在服务器端也实现制程超越,股价在20年超过英特尔,市值也在22年开始超越英特尔。23Q1 AMD重磅推出结合CPU+GPU架构的MI300正式进军AI训练端,对标英伟达Grace Hopper,通过规格及性能全面提升,重点发力数据中心的HPC及AI领域,试图重演16年CPU端突围成功。MI300将于下半年正式推出,管理层预计2024年将看到明显贡献。
MI300全方位追击英伟达Grace Hopper,但软件生态完善成破局关键
MI300结合AMD的Zen 4 CPU与CNDA 3 GPU,仿生人脑结构,顺应多模态模型发展趋势,制程跃入台积电5nm体系,与英伟达看齐,算力及能耗性能相较前代MI250X也显著提升。数据传输方面,MI300采用“统一内存架构”突破GPU与CPU之间的数据传输速度限制,类比英伟达NVLink技术,能满足未来AI训练和推理中,海量数据计算和传输的需求。价格方面,高性价比策略的延续将为其与英伟达的竞争中再添一码。然而,AMD的ROCm软件系统相较英伟达CUDA起步晚且生态圈较为单薄,或为其打破英伟达独大的一大障碍。
AI为第一战略重点,丰富产品矩阵深化竞争壁垒,微软会否助力一臂?
AMD管理层强调AI为目前的第一战略重点,公司正致力于构建更加多元的AI产品矩阵。目前发布的产品包括融合Ryzen AI以提高性能的Ryzen 7040系列CPU、自适应数据中心平台Versal AI、注重能耗性能的AMD Alveo V70 AI推理加速器,以及数据中心CPU第四代EPYC Genoa处理器(Genoa-X还未上市)。而即将上市的MI300将助阵其丰富的AI产品矩阵,欲在AI训练端攻城略地,跟英伟达正面交锋。另外,考虑到TCO、可控性及自身生态圈集成,云厂商自研芯片也为大势所趋。最近彭博报道微软跟 AMD 合作研发 AI 芯片,微软虽否认,但也说明了云厂商与芯片公司合作的可能性。
PC需求下行欲见底,管理层预计下半年市场将回暖
AMD 23Q1营收及利润虽超预期,但同比均下滑,主要鉴于PC出货量持续下行,公司控制出货量以消耗下游库存。虽然目前全球PC出货量底部还未出现,但管理层表示正致力于平衡出货量与需求,预计下半年PC和服务器市场将恢复,业务将录得增长。公司Q1推出了PC端亮眼产品组合:Ryzen 7000X3D通过3D V-Cache技术提高数据获取速率及缓存容量、笔记本电脑搭载7945HX CPU在电子设备测评中领先,而Ryzen 7040系列Phoenix CPU相关产品将在5月中下旬开始陆续上市。以上产品均基于Zen 4架构和台积电5nm制程。
第四代 EPYC 数据中心 CPU ,重磅升级发力云端
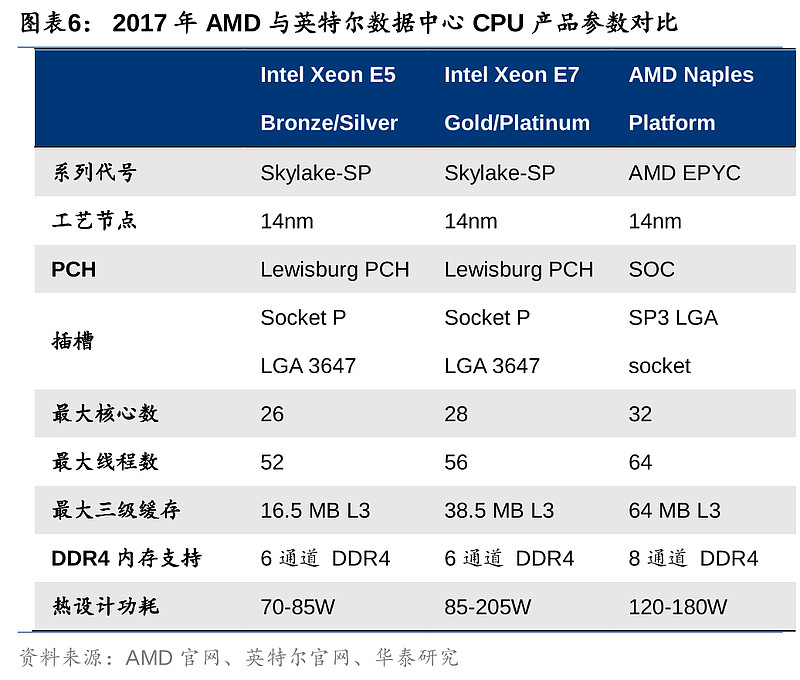
23Q1数据中心业务受限于宏观经济营收同比持平,但云巨头进一步扩大AMD产品部署,当季新增搭载28个项目。第四代EPYC CPU家族再添新成员,成为MI300之外下半年拉动数据中心营收增长的第二引擎。Bergamo基于台积电5nm制程,拥有多达128个内核,计划Q2末上市,公司预期其为下半年营收的重要贡献;Genoa-X对比同样采用3D V-Cache技术的第三代EPYC CPU Milan-X,在内存容量及带宽再上一层楼。AMD主要竞争对手英特尔23Q1同样推出数据中心CPU,但其均采用Intel 7制程,等同于台积电7nm制程,相较AMD仍然落后。
风险提示:新产品落地进度推迟、PC恢复和AI技术落地不及预期等。
正文
MI300正面交锋英伟达,能否复制16年CPU突围战的成功?
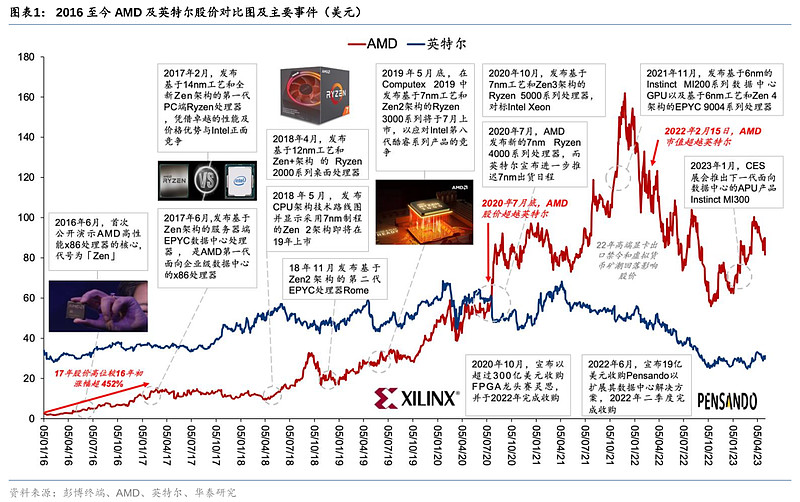
回顾CPU领域中AMD与英特尔自2016年开始的争锋历程,AMD曾凭借领先的制程,一举颠覆英特尔一家独大的局面,成为其CPU业务和股价的拐点。在2020年7月,AMD和英特尔的股价首次出现倒挂,而到了2022年2月15日,AMD的市值达1977.5亿美元,首度超越英特尔的市值。目前,AMD也试图在数据中心的AI应用,特别是训练端里,以新产品MI300跟英伟达正面交锋,到底AMD这次能否复制他们在CPU一役中的成功?
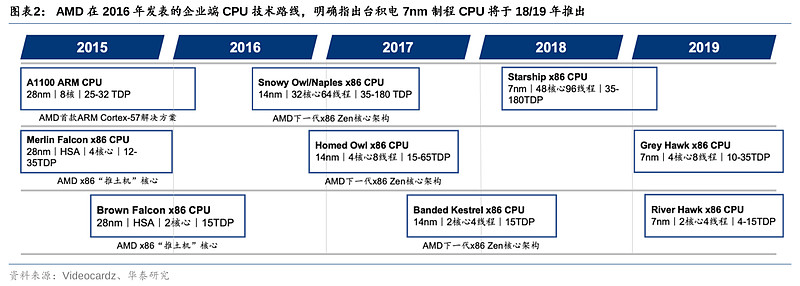
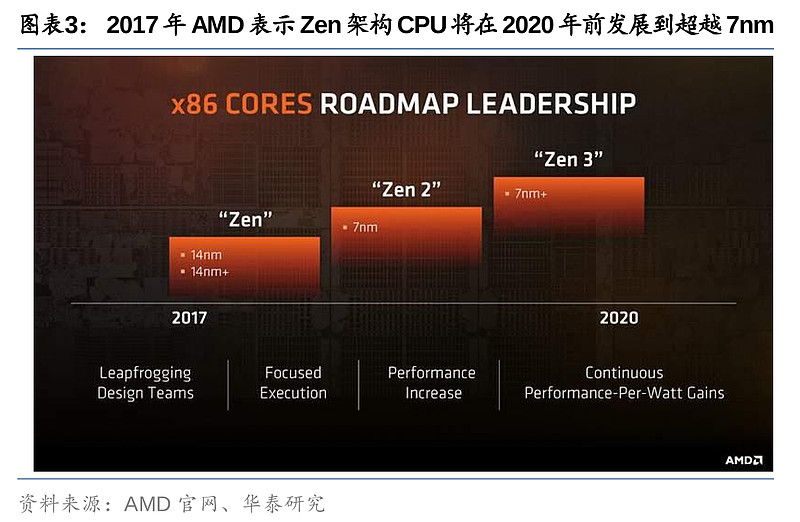
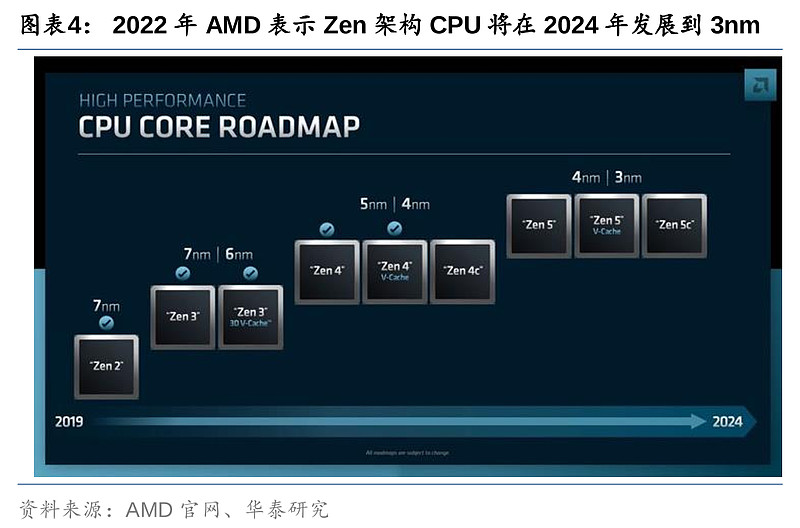
2016年上半年, AMD发布了企业端CPU 技术路线图,其中明确表示了制程上的突破,基于台积电7nm的CPU将于2018/19年推出。随后6月,AMD发表了Zen架构,涵盖PC端及服务器端CPU产品,并在2017年宣布以Zen架构重新整合其PC及服务器产品。在该Zen架构技术路线图中,AMD进一步明确了2018/19年将有7nm产品推出,2020年将向更先进制程迈进。反观彼时的英特尔,由于在制造更先进制程芯片的过程中遭遇技术困难,10nm芯片良率不佳,导致原定于2016年下半年的10nm(相当于台积电7nm)量产多翻推迟至19年下半年。目前,AMD的Zen架构已发展到台积电5nm制程,而2022年新版技术路线图进一步更新了其进入台积电3/4nm制程的计划。
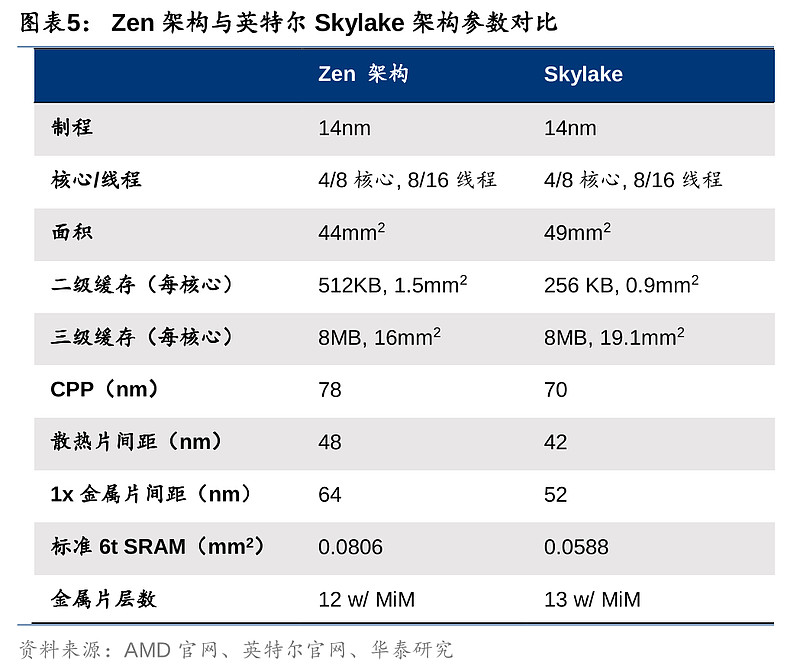
2016年6月,AMD宣布推出Zen x86-64微架构。对比彼时英特尔的Skylake架构,Zen的CPU部分面积较小,缓存空间有所提升,且散热片间距加宽,默认频率更高,功耗更低,价格也较低。随后在17年初上市,同样基于Zen架构的Ryzen 7系列PC端CPU,采用了14nm制程及8核16线程工艺,对标同为14nm制程的英特尔酷睿i7-6900K(基于16年6月推出的Broadwell-E升级架构)。从此时开始,AMD的PC端产品已逐渐逼近英特尔,而蚕食份额的趋势也初见苗头。服务器端方面,AMD于同年也推出了同样基于Zen架构的EPYC CPU产品,对标英特尔Xeon CPU(同为14nm制程)。EPYC凭借高性能表现及高能耗效率,也开始在数据中心的市场份额上攻城略地。
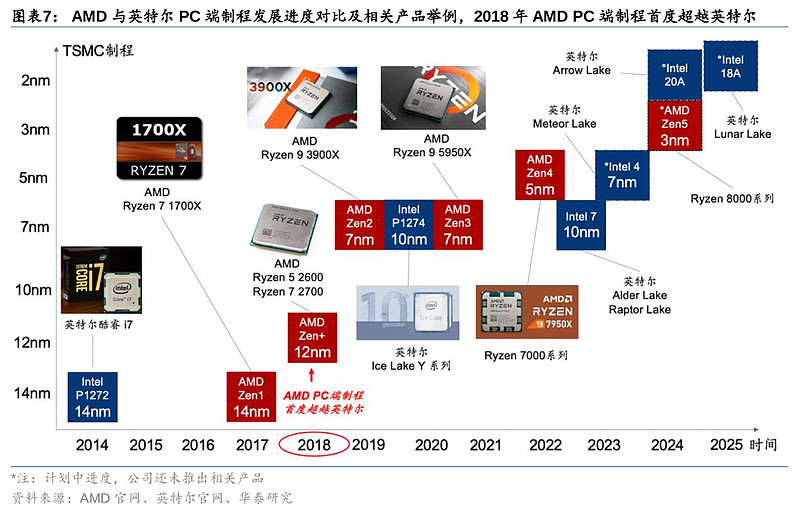
在英特尔正深陷良率等问题不断推迟10nm量产的同时,AMD联手台积电,在制程上不断取得突破,在PC及服务器端的制程上纷纷弯道超车英特尔,为市场份额的提升开了绿灯。 2018年,AMD推出了采用当时Global Foundry 12nm半节点制程的Zen+架构,并基于此推出PC端Ryzen 5 2600及Ryzen 7 2700 CPU,首度在制程上超越当时还是14 nm的英特尔,加速抢占英特尔的CPU市场份额。
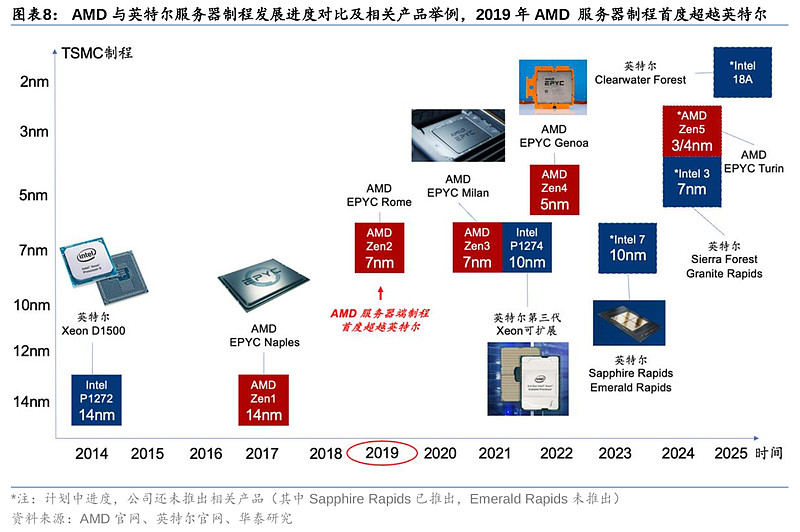
随后在2019年,AMD在PC和服务器端的制程均更上一层楼。AMD推出了基于台积电7nm制程(相当于Intel 10nm制程)的Zen 2架构,当中包括Ryzen 9系列的PC端CPU,以及EPYC Rome 服务器端CPU。Zen 2架构采用了Chiplet小芯片设计,通过CPU和IO核心分离,解决超多核心并行问题的同时也降低了生产成本,并达到降低延迟的效果。而在差不多时间里,英特尔的Ice Lake PC产品也终于上市量产,该产品采用了英特尔早在2015年发表的Intel 10nm制程。英特尔虽勉强追赶上AMD在PC端的制程进度,但在制程上的落后也并没有改善。
2020年7月底,英特尔宣布将推迟Intel 7nm(对标台积电5nm)制程至2022年以后。反观AMD在20Q2财报中PC端业务营收大涨45%,并进一步上调了全年营收预期。当月AMD股价大涨47%并首度超越英特尔的股价。同年10月,AMD宣布收购头部可编程逻辑器件(FPGA)生产商赛灵思(Xilinx),并于2022 Q1完成并表。对比英特尔在2015年收购了FPGA生产商(Altera),收购赛灵思能为AMD带来FGPA、可编程SoC及自适应计算加速平台产品,并将AMD的产品矩阵扩充至与英特尔看齐,为AMD数据中心及嵌入式业务如虎添翼。
2021年,AMD推出了基于台积电7nm制程的Zen 3架构,并推出了EPYC Milan 服务器CPU,对比姗姗来迟的英特尔,此时才推出采用Intel 10nm制程的第三代Xeon可扩展CPU。2022年,AMD基于台积电5nm制程的Ryzen 7000系列产品顺利量产,再次拉开与英特尔PC端制程的距离(当时英特尔仍处于Intel 7阶段,对标台积电7nm)。
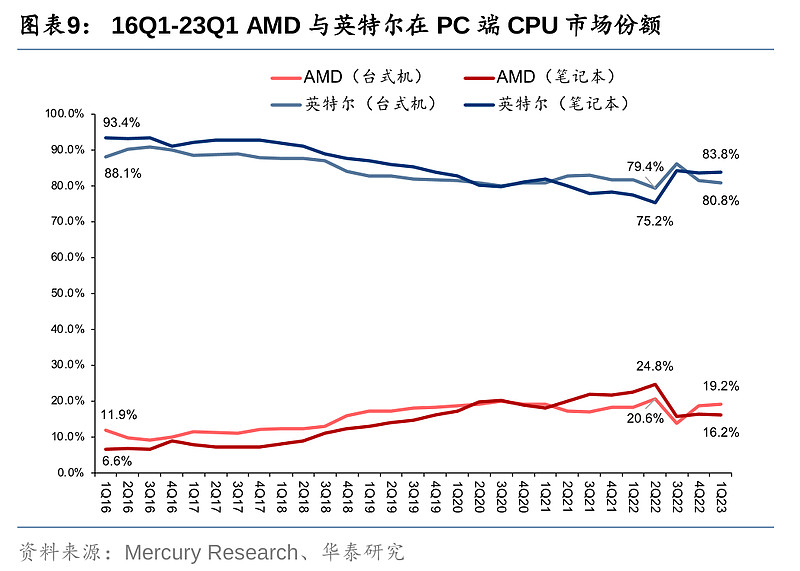
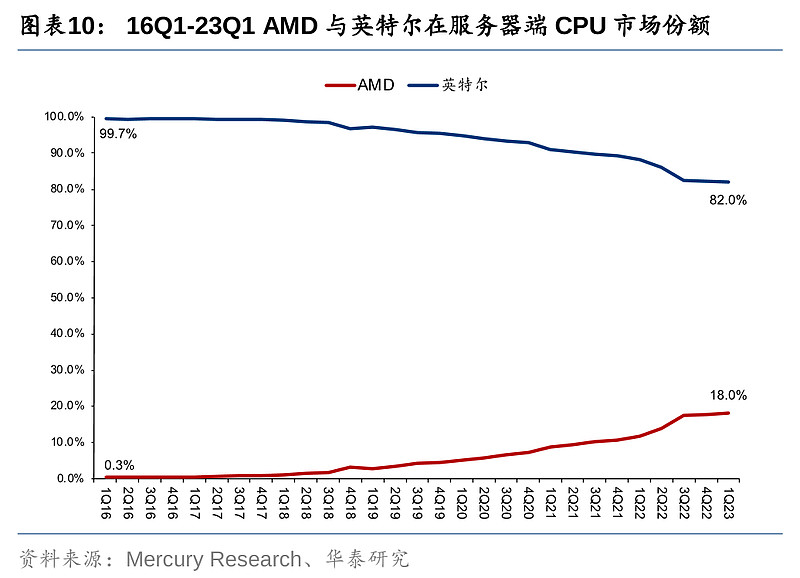
16Q1,AMD在台式机和笔记本的CPU份额仅为11.9%/6.6%。而Zen架构及相关产品推出后,AMD开始逐步蚕食英特尔的PC份额,并在18年制程反超英特尔后,份额提升加速。AMD的服务器CPU在16Q1份额仅为0.3%,市场基本被英特尔所垄断,但2017年EPYC推出后,服务器CPU的份额也开始一路上涨。至22Q2,AMD在PC端(台式机/笔记本)CPU份额分别攀升到20.6%/24.8%,为史上最高,但随后Q3出现回落。截止23Q1,AMD台式机/笔记本CPU份额为19.2%/16.2%,服务器端CPU市场份额为18.0%;英特尔台式机/笔记本CPU份额为80.8%/83.8%;服务器端CPU市场份额为82.0%。
AMD管理层在22Q3财报电话会表示,主要鉴于PC市场疲软,客户大幅调整供应链中的库存,导致该季度PC端营收同比由Q2的增长25%大幅降低至下滑40%。AMD的下游客户先前积累了较多AMD产品库存,因此在需求走弱后先消化额外库存,导致AMD的PC份额短暂下滑,但随后在Q4即开始恢复。另外,AMD在服务器端也受到宏观环境影响增速下调,在22Q3开始份额增长也放缓。
目前,AMD的MI300 CPU+GPU正准备进军AI训练市场,与英伟达Grace Hopper正面交锋。MI300或成为AMD与英伟达在AI竞争的拐点,能否重演2016年与英特尔在CPU角逐中的成功?AMD于CES 2023介绍了新一代Instinct MI300加速器,结合CPU与GPU,同时聚焦AI语言大模型训练端及推理端,对标英伟达Grace Hopper(Grace CPU + Hopper H100 GPU),一改过去AMD的GPU产品主要应用在图像处理及AI推理领域的局限。我们认为,MI300应该是除了谷歌的TPU之外,能与英伟达在AI训练端上匹敌的产品。MI300在规格及性能方面全面追击英伟达Grace Hopper,重点发力数据中心的HPC及AI领域。公司早前在22Q4财报电话会里提及,MI300已开始送样给重要客户,而正式推出将会在下半年,2024年将看到明显贡献。AMD的宿敌英特尔也不甘示弱,在2022年的ISC,英特尔公布了其结合x86 CPU与Xe GPU的Falcon Shores芯片组,该产品原定于2024年上市,但在2023年3月被公司宣布将推迟至2025年以后,具体架构信息暂未公布。
我们将从芯片架构和制程、算力、内存带宽、价格和软件生态对AMD MI300和英伟达Grace Hopper两者竞争优势展开对比:
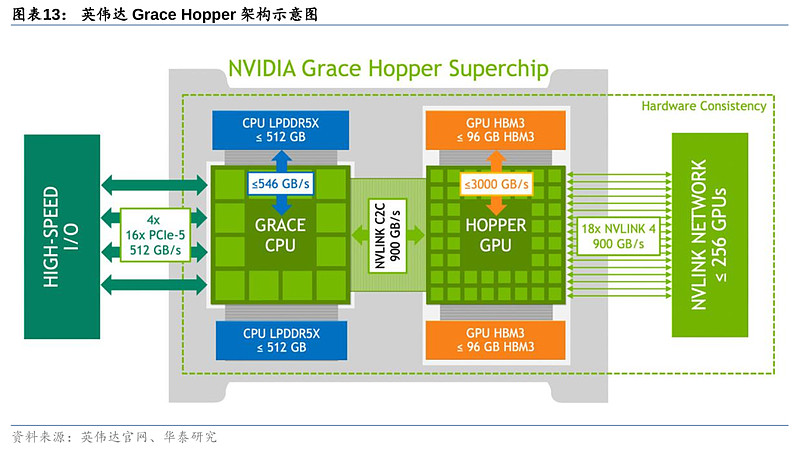
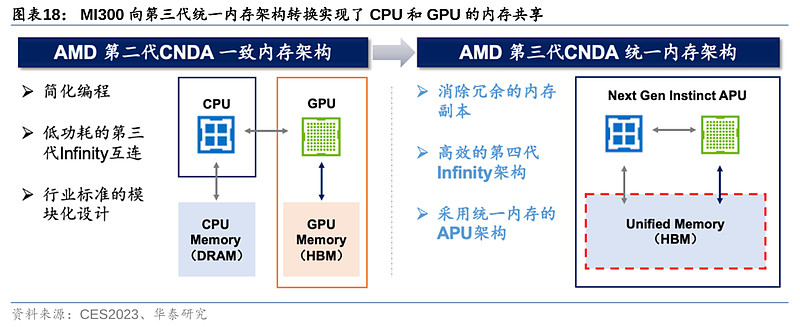
1)芯片架构:CPU+GPU仿生人脑结构,制程看齐英伟达。MI300是AMD首款结合了Zen 4 CPU与CNDA 3 GPU的产品,也是市场上首款“CPU+GPU+内存”一体化产品。MI300采用3D堆叠技术和Chiplet设计,配备了9个基于5nm制程的芯片组(据 PCgamers推测,包括3个CPU和6个GPU),置于4个基于6nm制程的芯片组之上。因此在制程上,MI300属台积电5nm,相较MI200系列的6nm实现了跃迁,并与英伟达Grace Hopper的4nm制程(属台积电5nm体系)看齐。MI300晶体管数量达到1460亿,多于英伟达H100的800亿,以及前代MI250X的582亿晶体管数量。CDNA 3架构是MI300的核心DNA,MI300配备了24个Zen 4数据中心CPU核心和128 GB HBM3内存,并以8192位宽总线配置运行。



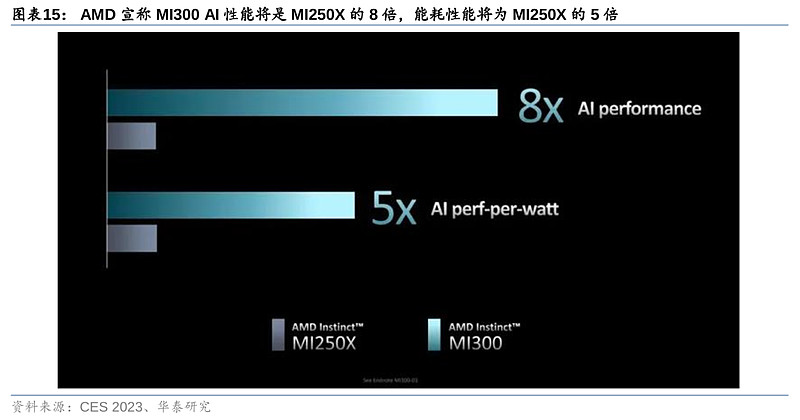
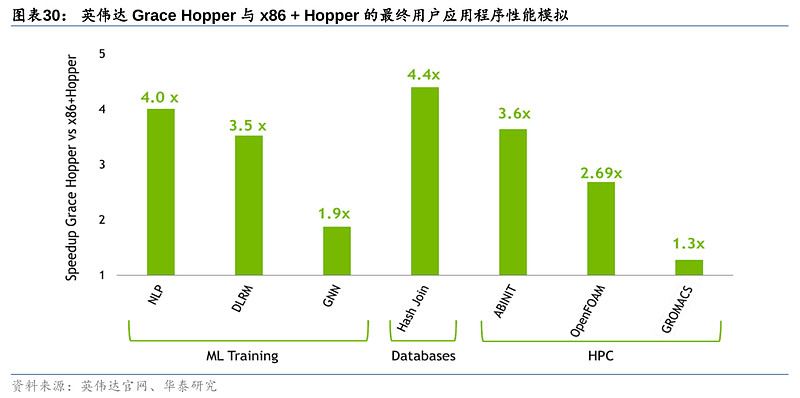
2)算力:MI300的性能逼近英伟达Grace Hopper。AMD上代MI250X(发布于2021年11月)FP32算力达47.9 TFLOPS,虽已超越英伟达A100的19.5TFLOPS(发布于2020年6月),但其发布时间在英伟达之后。AMD暂时未公布MI300与英伟达Grace Hopper在算力上的对比,但相较上一代的MI250X,MI300在AI上的算力(TFLOPS)预计能提升8倍,能耗性能(TFLOPS/watt)将优化5倍。因此,此次MI300的性能提升后有望逼近Grace Hopper水平。另外,Grace Hopper支持8位浮点精度,而MI250X仅支持16位及以上,但MI300或将在AI训练中支持4位和8位浮点精度,可进一步节省算力。
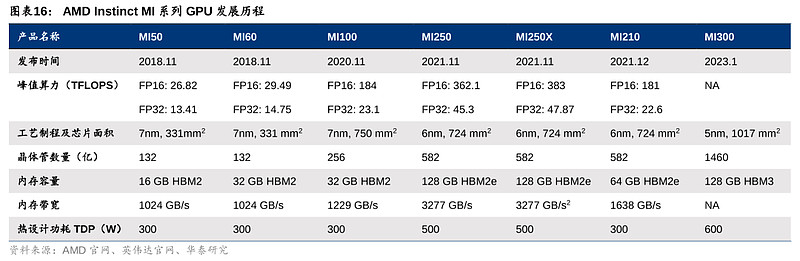
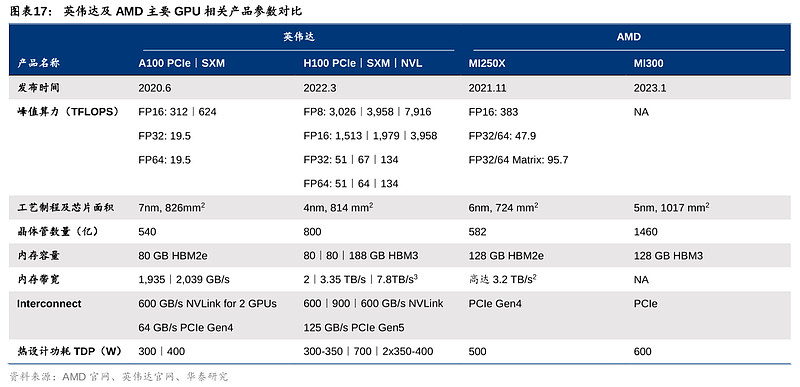
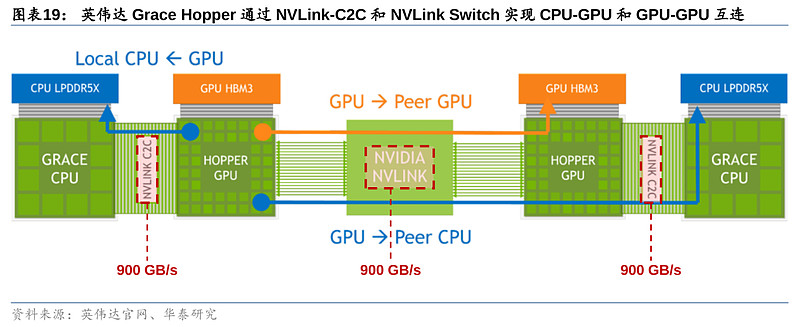
3)内存带宽:MI300通过“统一内存架构”(Unified Memory)便利GPU-CPU间数据传输,效果类比英伟达NVLink技术。MI300的3D Chiplet架构使其内部CPU和GPU可共享同一内存空间,针对相同数据同时展开计算,实现“zero-copy”(即CPU执行计算时无需先将数据从某处内存复制到另一个特定内存区域),便利单节点内GPU-CPU之间的数据传输,减少内存带宽的占用。而英伟达Grace Hopper则通过NVLink-C2C实现GPU-CPU高速互联,双方作为内存共享对等体可以直接访问对方的对应内存空间,支持900GB/s的互联速度。尽管AMD暂未公布MI300的传输带宽,但其创新的统一内存架构实现了GPU-CPU在物理意义上真正的内存统一。AMD虽未公布MI300 HBM的更多信息,但最新代HBM3内存带宽约为819GB/s,与英伟达NVLink C2C 900GB/s带宽相近。因此MI300内GPU-CPU的统一架构可绕过传统连接协议速度的障碍,突破GPU-CPU之间的数据传输速度限制,满足未来AI训练和推理中由模型大小和参数提升带来的海量数据计算和传输需要。但值得一提的是,英伟达Grace Hopper还通过NVLink Switch实现多达256个GPU的互联,支持高达150TB的高带宽内存访问,可有效解决GPU大规模并行运算中“单节点本地内存不足”的痛点,在内存带宽表现上或更胜一筹。
4)价格:高性价比策略或为AMD在与英伟达的竞争中再添一码。尽管AMD尚未公布MI300定价,管理层在FY23Q1财报电话会中表示数据中心产品将延续往日的高性价比定价风格,重点关注先把市场打开。成本效益乃云厂商的重中之重,加上单一依赖一个厂商也并非他们所愿。公司预计MI300将于今年底前推出,并将搭载于劳伦斯利弗莫尔国家实验室的百亿级超级计算机EI Capitan及其他大型云端客户AI模型中。

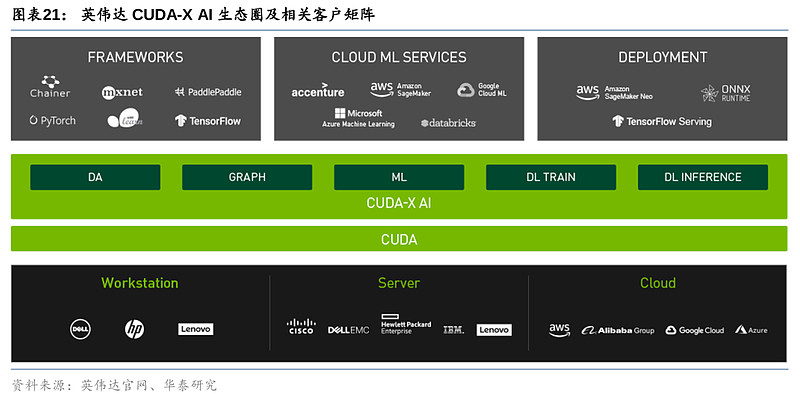
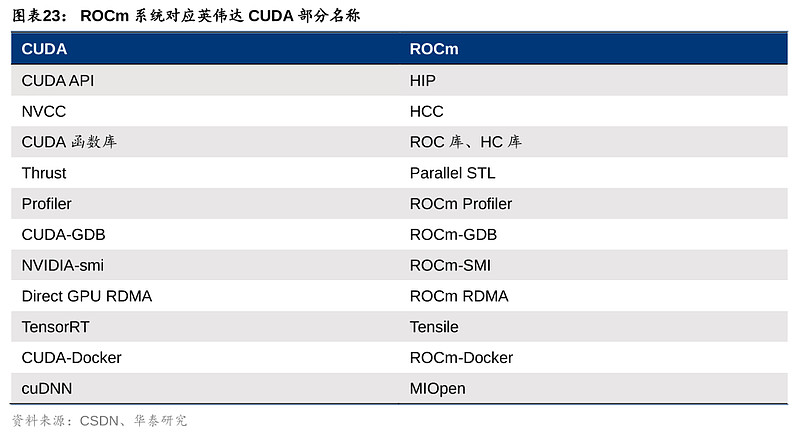
5)软件生态:对比英伟达的CUDA(Compute Unified Device Architecture)生态圈,AMD的ROCm(Radeon Open Compute Ecosystem)或是其打破英伟达独大局势的一大障碍。英伟达于2007年发布CUDA生态系统,开发人员可以通过CUDA部署GPU进行通用计算(GPGPU)。通过先发优势和长期耕耘,CUDA生态圈已较为成熟,为英伟达GPU开发、优化和部署多种行业应用提供了独特的护城河。AMD的ROCm发展目标是去建立可替代CUDA的生态。而ROCm于2016年4月发布,相比2007年发布的CUDA起步较晚。全球CUDA开发者2020年达200万,2023年已达400万,包括Adobe等大型企业客户,而ROCm的客户主要为研究机构,多应用于HPC。对任何一种计算平台和编程模型来说,软件开发人员、学术机构和其他开发者与其学习、磨合和建立生态圈都需要时间,更多的开发者意味着不断迭代的工具和更广泛的多行业应用,进一步为选择CUDA提供了更为充分的理由,正向循环、不断完善的生态也将进一步提高其用户粘性。
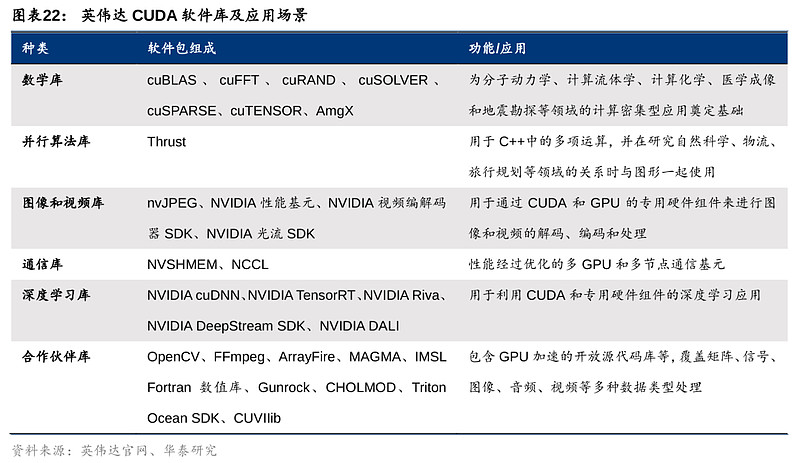
ROCm暂时或难以匹敌CUDA的主要原因包括:1)ROCm仅支持Instinct系列(即Radeon Pro系列)GPU的部分 SKUs,包括Radeon Pro W6800 和 Radeon Pro V620,近期方扩展至Radeon RX 6900 XT,Radeon RX 6600,以及已有9年历史的Radeon R9 Fury,而CUDA广泛支持英伟达多条产品线;2)CUDA1.0即支持Linux、Windows,而ROCm长期只支持Linux(甚至是特定的Linux内核版本),在今年4月刚刚宣布登录Windows,但仅支持Radeon Pro W6800,Radeon RX 6900 XT和Radeon RX 6600;3)英伟达拥有丰富的CUDA软件库,以便利开发者利用GPU构建新应用或加速现有应用,覆盖广泛终端应用场景,包括资源受限的物联网设备、自动驾驶及超级计算机等领域,而ROCm软件库则仅包括CUDA中的一些部分,例如部分数学函数、并行算法库Trust(ROCm中为Parallel STL)以及深度学习库中的cuDNN(ROCm中为MIOpen)。
针对这样的现状,AMD在丰富其软件生态也持续有积极动作。虽然目前仅有部分SKU支持Windows系统,但主流Radeon显卡用户可以开始试用过去仅专业显卡才能使用的AMD ROCm (5.6.0 Alpha)。23Q1公司宣布其ROCm系统融入PyTorch 2.0框架,目前TensorFlow和Caffe深度学习框架也已加入第五代ROCm。ROCm也能对应到CUDA的部分内容,例如ROCm的HIP对应CUDA API,只需要替换源码中的CUDA为HPI就可以完全移植。

AMD强调AI为公司第一战略重点定位,微软或入局助其一臂之力,塑造AI训练端竞争格局。AMD管理层在23Q1财报电话会中强调AI为目前公司第一战略重点,公司正致力于构建更加多元的 AI 整合产品矩阵,包括融合Ryzen AI的Ryzen 7040系列CPU、自适应数据中心平台Versal AI、 Alveo加速器、第四代 EPYC Genoa 处理器,以及目前公布即将上市的Instinct MI300。
Ryzen 7040处理器配备8颗Zen 4核心和AMD RDNA3显卡,内置的Ryzen AI每秒可完成高达12兆次AI运算,用于改善视频背景中的模糊、自动对焦及降噪功能。Versal AI Edge系列将协助开发者加速传感器系统和AI算法迭代,优化AI性能功耗比,包括自动驾驶、工业及医疗保健场景中的实时系统,以及航空航天与国防场景中的多任务负载等。AMD Alveo V70 AI推理加速器采用XDNA架构,峰值AI算力达400TOPS,而其TDP仅75W,且其兼容TensorFlow和PyTorch框架,适用于视频分析和自然语言处理应用。根据CES 2023中的展示,在智慧城市、智慧零售等应用中,Alveo V70的能效对比英伟达在2021年推出的T4推理加速器高逾70%(英伟达在今年的GTC里发布了新一代的L4推理加速器)。
另外,根据彭博社 5月4日的报道,微软将注资 AMD 并开展合作,推动其在 AI 处理器领域的发展。该报道称,目前合作研发的微软 AI 芯片名为“雅典娜”(Athena),旨在为 chatGPT等大型语言模型(LLM)的训练及推理提供英伟达芯片以外的替代方案。随后5月5日,微软发言人Frank Shaw表示AMD参与“雅典娜”项目的报道不实,但并未明确微软与AMD的合作关系。我们认为,大型云计算供应商拥有财力物力,面对较高的外购成本和较有限的灵活性,选择自己设计AI芯片也并非意外。微软与OpenAI的合作中应用到大量的英伟达芯片,而若与AMD开展战略合作,或将取代部分英伟达芯片的需求。
云厂商自研芯片为大势所趋,除微软外,谷歌及亚马逊等头部云厂商也在推进AI芯片自研进程。谷歌于2016年推出基于ASIC专用芯片的AI推理芯片Tensor Processing Unit (TPU),在2017年迅速发展到第二代并拥有AI训练功能,TPU目前已发展到第四代,并应用于PaLM等大语言模型的训练,但谷歌并没有发售TPU,仅通过Google Cloud Platform对外进行算力租赁服务。亚马逊则分别在2019和2020年推出AI模型推理端芯片Inferentia以及训练端芯片Trainium,并整合到其AWS中。云厂商推进芯片自研首先出于节约外采芯片成本、降低芯片能耗(ASIC基于专用性能耗更低)以削减TCO的考量。其次,公司推动自研芯片,自主可控。另外,芯片自研可集成公司本身拥有软件生态圈深化竞争壁垒,如谷歌的TPU即为其TensorFlow深度学习框架量身打造,在其中充分发挥其性能。


综上所述,AMD的MI300也许是谷歌TPU之外,最有潜力在AI训练端中与英伟达匹敌的芯片,但生态系统或是AMD打破英伟达独大局势的一大障碍?MI300在规格及性能上接近英伟达的Grace Hopper,其CPU+GPU架构更加符合人脑信息处理流程,并能顺应多模态模型发展趋势。MI300通过CPU与GPU统一内存的架构,跟英伟达NVLink的传输性能可比,并逐步攻克PCIe总线瓶颈限制数据传输速率的问题。然而,AMD对英伟达市场份额的挑战并非一蹴而就。一方面,英伟达GPU芯片的算力壁垒以及AI训练端的深入布局一时难以撼动,另一方面,AMD的软件生态也限制其与客户系统的融合及渗透应用场景。
人脑神经网络的运作模式始终是人工智能追求的终极形态
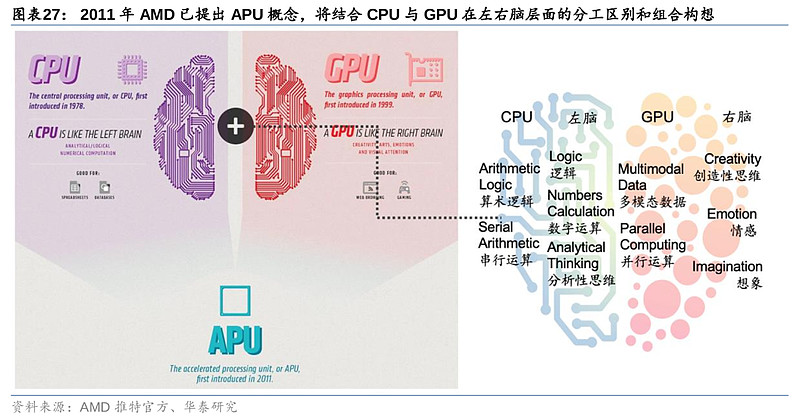
AMD对芯片与人类大脑的操作理解较为超前。早在2011年,AMD产品构想中就以CPU和GPU分别类比人类左右脑,并基于此提出了CPU+GPU的异构产品策略。类比人脑,AMD认为左脑更像CPU,负责对信息的逻辑处理,如串行运算、数字和算术、分析思维、理解、分类、整理等,而右脑更像GPU,负责并行计算、多模态、创造性思维和想象等。
人类大脑神经网络的运作模式,始终是人工智能追求的终极形态,因此,我们认为CPU+GPU的异构集成,对比人类可实现左右脑协同工作,整体调动神经网络,或将成为AI芯片的主流技术方向。目前AMD的MI300、英伟达的 Grace Hopper和英特尔的Falcon Shores在此均有布局。GPU的算力高,并针对并行计算,但须由CPU进行控制调用,发布指令。在AI训练端,CPU可负责控制及发出指令,指示GPU处理数据和完成复杂的浮点运算(如矩阵运算)。
在面对不同模态数据的推理时,我们认为,CPU与GPU的分工也各有不同,因此,同时部署CPU和GPU能提供最大的运算支撑。例如,在处理语音、语言和文本数据的推理时,AI模型需逐个识别目标文字,计算有序,因此或更适合使用擅长串行运算的CPU进行运算支持;但在处理图像、视频等数据的推理时(对比人类的操作,每一个像素是同时进入眼睛),需要大规模并行运算,或更适宜由GPU负责,例如英伟达L4 GPU可将AI视频性能提高120倍,据英伟达测试,L4与基于CPU的传统基础设施相比能源效率提高99%。
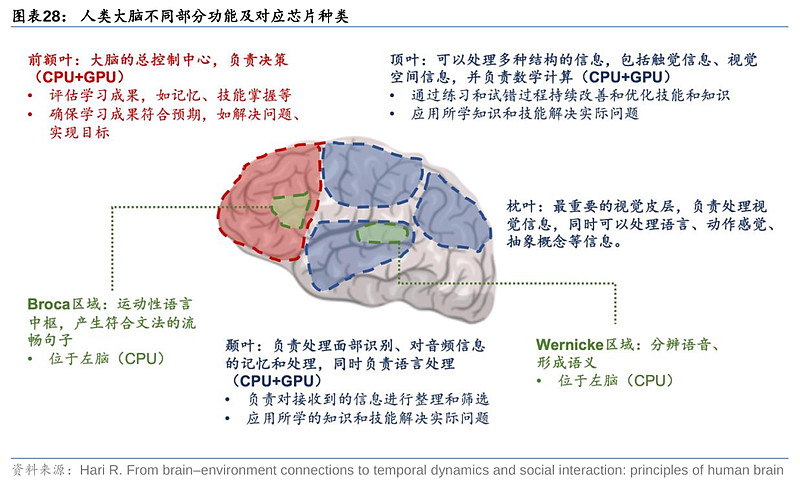
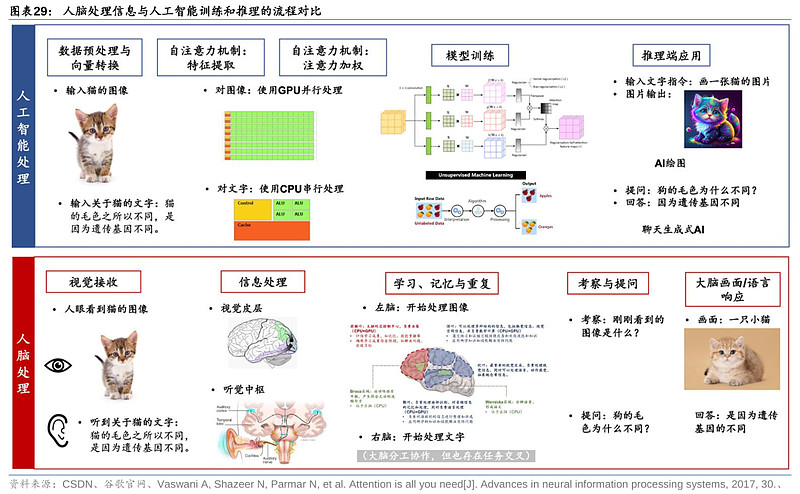
以Grace Hopper为例,可以具体观察CPU+GPU异构的优势所在。英伟达通过NVLink-C2C技术使CPU+GPU构成一个完整的系统,并实现内存相互访问,无需沿循“CPU-内存-主板-显存-GPU”基于主板PCIe的迂回路线,从而减少CPU计算损耗,并大幅提升功耗、延时和带宽。GPU在视频处理、图像渲染等方面的优势毋庸置疑,但并非所有工作负载都是单纯的GPU-bound,因此我们认为,其CPU部分或主要用于发出指令,以及在推理阶段处理,尤其是文本、音频等信息。
PC需求持续下行欲见底,发力云端AI欲与英伟达一决高下
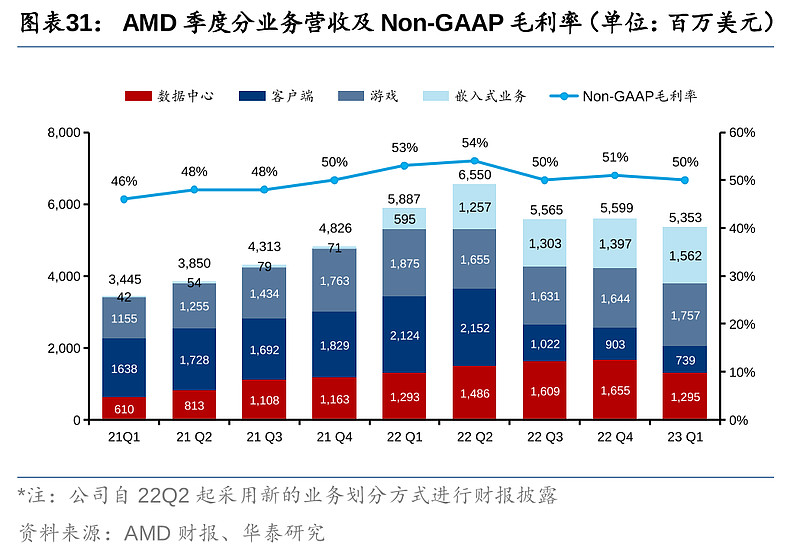
AMD营收及利润均超预期,但较低指引触发股价下跌。AMD 23Q1营收为53.53亿美元,同比下滑9%,non-GAAP EPS为0.60美元,同比下滑47%,均略超彭博一致预期的53.18亿美元和0.58美元,non-GAAP毛利率同比下降3pct至50%。公司指引二季度营收约为53亿美元,同比下降19%,但环比基本持平,其中客户端、数据中心,以及游戏业务营收同比将继续下滑,但嵌入式业务营收将增长;non-GAAP毛利率预计保持在50%水平。2023全年指引营收将会由数据中心和嵌入式业务的同比增长所拉动,而non-GAAP毛利率也将在下半年扩大。虽然Q1营收及利润表现均超市场预期,但二季度较悲观的营收指引导致盘后股价下跌6%。
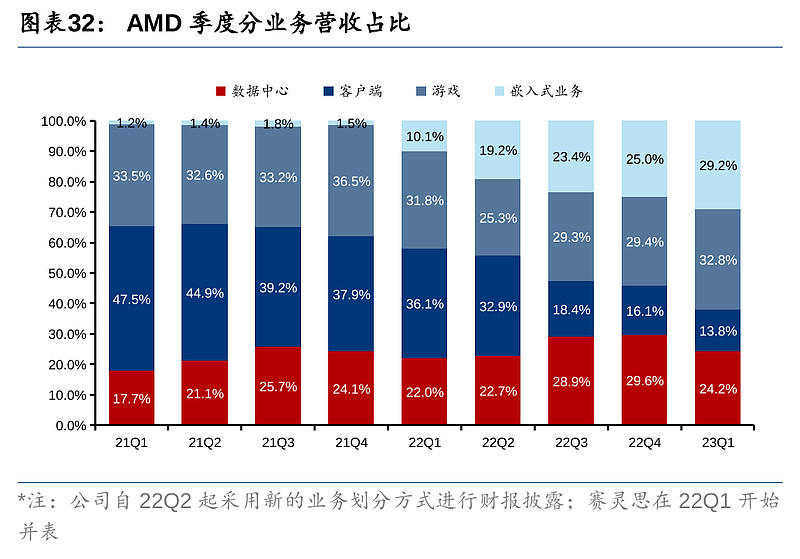
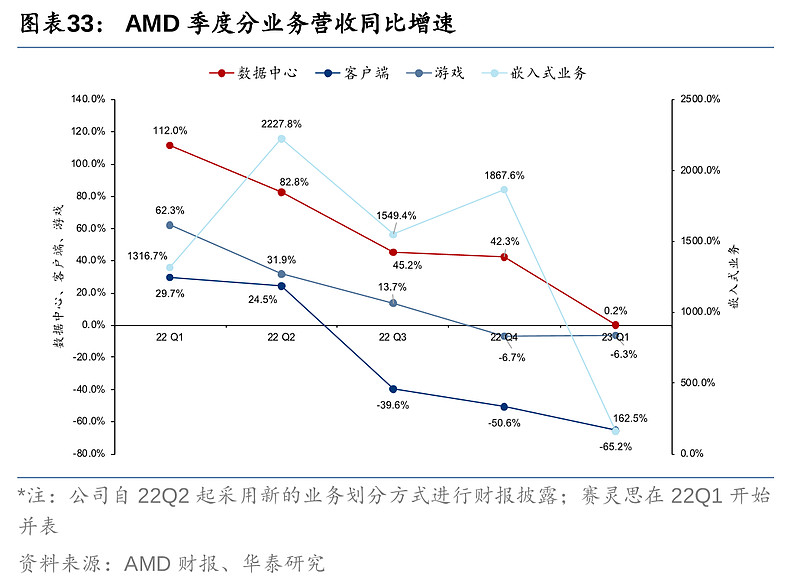
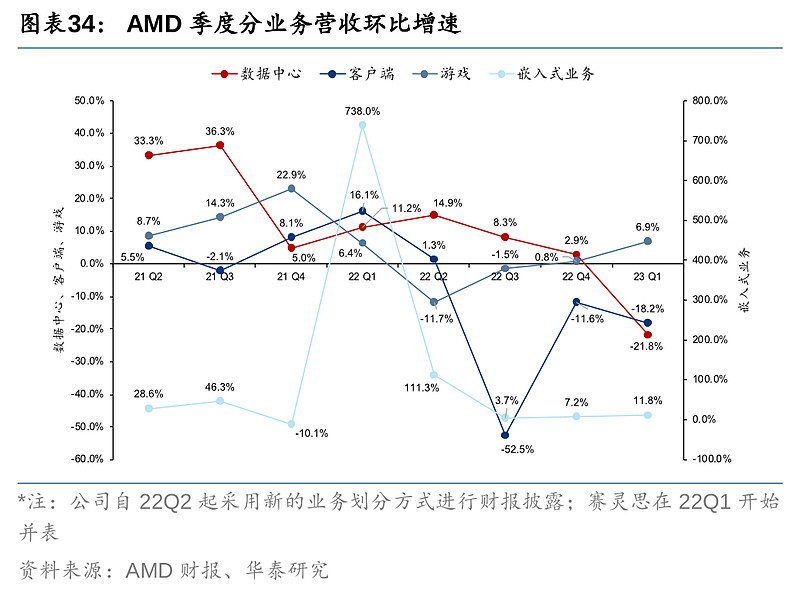
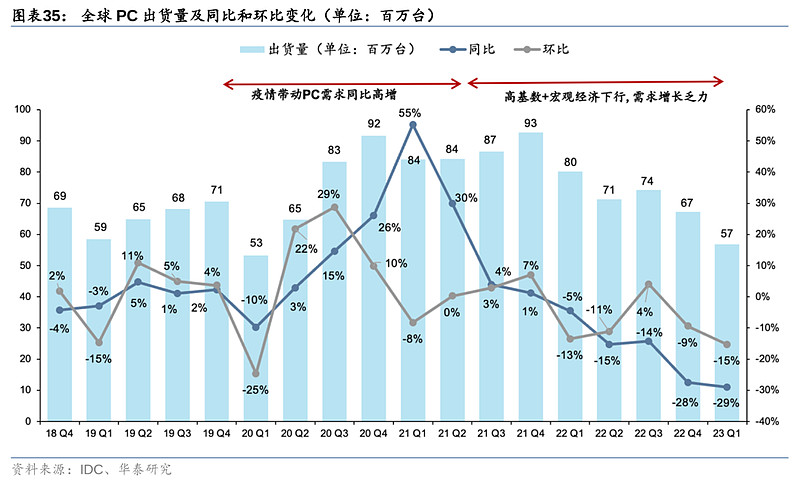
AMD 23Q1营收下滑主要鉴于PC出货量持续下行,公司控制出货量以消耗下游库存,导致客户端营收同比大幅下滑。Q1营收7.39亿美元,同比降幅达65.2%,对比一季度IDC数据,个人电脑Q1出货量同比下滑29%,行业的不景气也影响了主要竞争对手英特尔的相关PC业务,营收下滑36%。
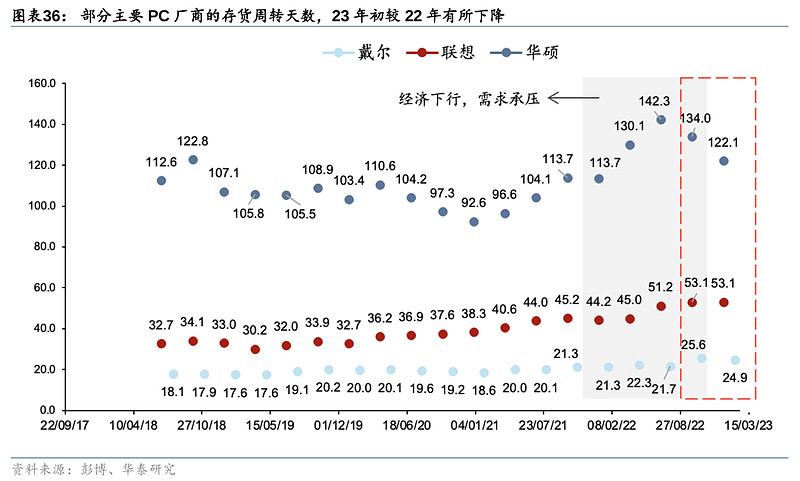
全球PC出货量的底部目前虽还未出现,但下半年有望迎来修复。AMD管理层预计今年整体PC销售将下跌10%,即约2.6亿部。竞争对手英特尔也表示,2023年全年PC出货量预计为2.7亿,未来将提高并稳定至每年3亿部。AMD也表示正致力于平衡出货量与需求,并认为二季度和下半年PC市场将回暖。彭博数据显示,2023年初戴尔、华硕、联想等主要PC厂商存货周转天数(24.87/122.10/53.11)相较22年下半年(25.56/133.96/53.13),可以看到一些厂商的存货周转天数虽已开始出现下降,但根据IDC数据,PC出货量环比依然下滑。
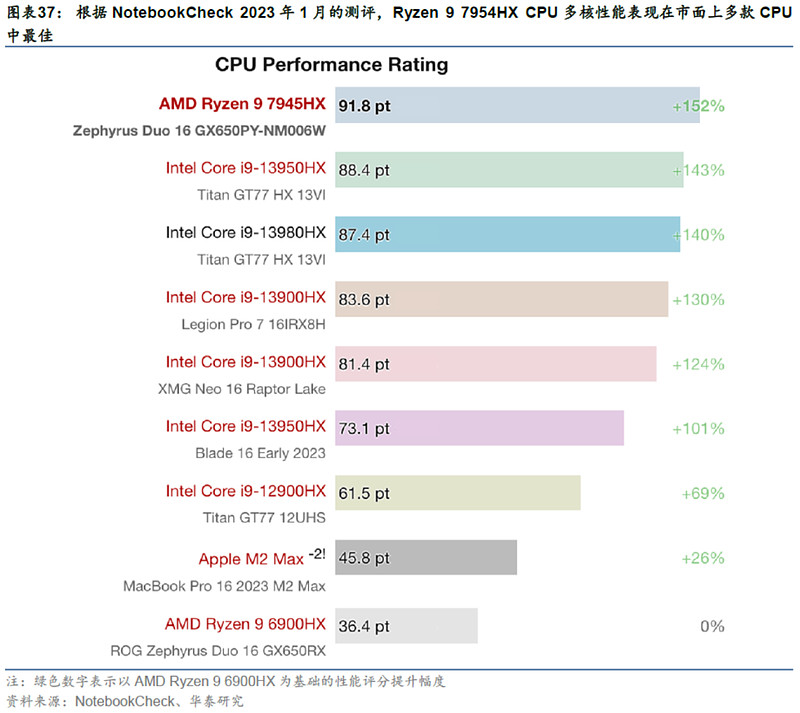
PC方面,AMD 23Q1推出Ryzen 7000X3D系列处理器(包括7950和7900),而7800也于4月初推出,配备AMD 3D V-Cache堆栈缓存技术,拥有更高的数据获取速率及缓存容量。移动设备方面,笔记本电脑系列AMD Ryzen 9的7945HX CPU在电子设备测评平台NotebookCheck中获CPU性能测试排名第一。另外,Ryzen 7040系列Phoenix CPU处理器已量产,相关笔记本产品将在5月中下旬开始陆续上市。以上产品均基于Zen 4 架构和台积电5 nm 制程。
AMD数据中心业务23Q1营收12.95亿美元,同比12.93亿美元基本持平。公司表示,二季度数据中心业务应录得增长,但也需取决于宏观环境。数据中心经营利润率11.4%,同比降幅达21.6pct,经营利润率下滑主要由于公司发力产品矩阵及研发费用投入。根据公司管理层,23Q1云巨头进一步扩大了AMD产品部署,微软Azure、谷歌云及甲骨文云等客户的28个新项目搭载了EPYC系列CPU处理器。截至目前,已公开的由AMD产品驱动的项目超过640个。
公司早前在22Q4财报电话会也表示,数据中心CPU第四代EPYC系列新产品Bergamo预计于Q2末上市,EPYC Genoa-X处理器也将于本年内上市,而公司也认为Bergamo将会成为下半年营收的重要贡献。Bergamo CPU基于台积电5nm制程工艺,采用Zen 4C架构,具有多达128个内核,针对吞吐量提升进行了优化。第四代EPYC家族的另一位新成员Genoa-X与前代EPYC中的Milan-X同样采用3D V-Cache技术,Milan-X基于Zen 3架构,最大缓存为768MB,而基于Zen 4架构的Genoa-X在同为95核心的情况下最大三级缓存超过1GB。另外,公司在今年一月发布的Instinct MI300 CPU+GPU剑指人工智能和高性能计算,该产品预计下半年开始放量,或可成为英伟达在AI训练端的有力竞争者。



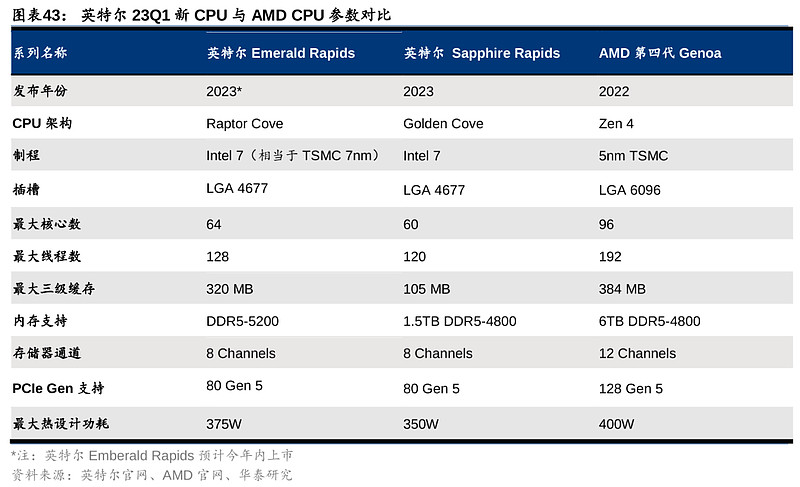
竞争格局方面,AMD在服务器CPU的主要竞争对手英特尔在23Q1推出了第四代可扩展Xeon CPU Sapphire Rapids,采用Intel 7制程(之前为10ESF,是基于英特尔之前的10nm),相当于台积电的7nm制程。但AMD第四代数据中心EPYC产品Genoa早在2022年11月推出,并基于台积电的5nm制程,单芯片核心数及线程数已达96和192;而Sapphire Rapids最大核心数为60,最大线程数为120,三级缓存为105MB,跟AMD Genoa的384MB差距也较大。另外,英特尔Q1也公布了第五代Xeon CPU Emerald Rapids,采用双层Chiplet结构,同样采用Intel 7制程,对比Sapphire Rapids有更多的核心数量以及更大的内存空间,英特尔预计其将于2023年Q4开始量产。但即使是进一步升级的Emerald Rapids,其制程、核心及线程数(64/128)、三级缓存容量(320MB)仍相对落后于AMD Genoa。

嵌入式业务23Q1的营收从去年的5.95亿美元激增至15.6亿美元,同比上涨163%,是AMD于22Q1收购赛灵思后首个完全并表可比的季度。赛灵思的产品包括FPGAs、Zynq系列可编程SoC、Versal自适应SoC以及Alveo自适应数据中心加速器,跟AMD的产品产生协调效应,如虎添翼。公司管理层表示,整合赛灵思的产品进行交叉销售拉动了公司在嵌入式市场销售的扩张。23Q1,AMD发布基于台积电5nm制程Zen 4架构的新一代EPYC 9000嵌入式处理器,以及基于台积电7nm制程Zen 3架构的Ryzen嵌入式5000系列CPU。目前,嵌入式和数据中心这两个to B业务贡献了AMD超过50%的营收。
游戏业务包括个人电脑提供图像处理器(显卡)以及为Sony PlayStation 5等游戏机提供芯片。23Q1营收为17.6亿美元,同比跌6%,低于去年的18.8 亿美元。公司管理层表示,在传统感恩和圣诞节假期后的高端游戏机需求仍然强劲,而半定制SoC营收同比录得两位数增长。

风险提示
新产品落地进度推迟:MI300、Bergamo等新产品的发售或受到市场需求波动、供应链扰动、技术挑战无法及时攻克等因素的影响,无法按照预期进度落地放量,使得营收提升不及预期。
PC出货量恢复不及预期:若全球PC需求及出货量持续下行,恢复不及预期,客户端及游戏业务营收跌幅可能会继续扩张。
AI技术落地和推进不及预期:AMD重点发力AI领域,发布MI300进军AI训练端,而若AI市场技术落地和推进受阻,AMD AI产品的需求及营收可能受到影响。
相关信息数据来自于相关公司的公开的客观信息,不代表对相关公司的研究覆盖和推荐。
文章来源:华泰证券