书接上回【美股软件系列①:Snowflake(深度长文还原最真实的Snowflake产品使用体验)】,#snowflake# 通过推出存算分离、高度灵活拓展的云原生数据仓库,吊打了一众传统数仓企业,并且以极致丝滑的用户使用体验吊打了三大云厂商的云端数据库产品。

然而Snowflake的数据仓库业务却有一个在如今大数据时代下越发突显的短板——不擅长处理非结构化数据。
什么是非结构化数据?
直接上对比表格:

总的来说,Snowflake擅长的、使用SQL调用查询的数据仓库,存储的就是结构化数据,而除了结构化数据以外的其他各种图片、视频等文件形式的数据都称为非结构化数据。非结构化数据往往不仅处理而直接储存在企业的数据湖(Data lake)中。
随着机器学习、深度学习、大语言模型学习需求的爆发,企业对于非结构化数据的处理需求也进入了爆发式的增长阶段。

因此,如何调整自身产品,以适应非结构数据处理、充分且高效利用企业数据,帮助企业基于自身业务数据训练和部署大语言模型的能力,对于Snowflake在现阶段以及未来的增长空间而言至关重要。
接下来,就让我们进入正题,从Snowflake最近发布的新产品Snowpark和Cortex,看看他的发展战略、产品特色以及和竞品的比较。

首先,要明确当前企业端部署大模型到底在什么阶段?
虽然国内外各家企业都时不时报出一些大模型落地、提升企业运营效率等类似的新闻,但是真的实际去看企业内部的现状,包括和各种CTO的访谈,我们必须承认一点:AI大模型目前的发展大部分还在训练和实验阶段,真正进入一定体量的推理和商业化上线的时代还未到来。否则,#英伟达# 的股价也不是在800-900元上下波动了,而突破1000元,直奔2000元去了。
因此在这样一个以训练和实验性的现阶段,核心的workload还集中在传统AI/ML工作流中将图、文、影、音混杂的散落在各地的非结构化数据(以及实时生成的流式数据)高效解析成向量化数据的阶段。
Snowflake因此也推出了针对这一阶段的非结构化资料存储产品Unistore。可惜的是,Unistore原先的设计方式并不是完全针对AI和ML的需求来服务的,且面对Databricks等一众从诞生之日就针对非结构化数据处理的数据湖产品的竞争,Snowflake在这一阶段提升市占率的过程非常吃力,占不到便宜。
而后,Snowflake又紧接着推出了Snowpark ML API,同样也是针对大模型工作流的训练阶段,但却也只是被当做抓取数据的用途就太片面了,而训练模型的人很少会纯用Snowpark ML,大家都以五大模型公司的产品为主(后面我们简称五朵金花,即Open AI的GPT,Anthropic的Claude家族,Meta的Llama系列,谷歌的Gemini和欧洲新秀Mistral AI)。
Snowpark虽然有汇入其他模型的功能,但它的主要目的是为了衔接AI/ML工作流程的后段,发挥模型版本管理的价值,在工作流的前段,即训练模型阶段,起不了太大的帮助。
说到这里,我们细聊一下Snowpark的模型管理功能。整体上其实规划得很不错,延续了Snowflake产品的易用性,可以实现管理AI模型实体、模型名称+版本+训练数据+性能指标等metadata相关的参数、排程和部署设定、批次执行推论等全套的运维功能。
但由于我们前文所讨论的,Snowflake现阶段的产品在大模型训练工作的前段表现偏弱,而AI大模型行业整体的发展也还没大量进入后段,因此整个Snowpark的产品使用量也没起来,增速也在快速放缓,这也是Snowflake进军AI一直被华尔街所诟病的一点:
“公司CFO在去年12月初提过Snowpark run rate达到了7000万美金,但在上个业绩会上却表示FY24财年全年Snowpark仅贡献3500万美金的收入,即4Q QoQ增速已经由2Q的70%,3Q的47%放缓至仅30%出头”

而已经研发完成,现在正在preview阶段,尚未正式GA开卖的Snowpark Container Service容器服务,也是AI/ML模型工作流程的偏后段的产品,虽然有爆发潜力,但若单独看这个子产品其实是没有太大竞争差异化优势的,而且前段如果没抢到客户,从工作流的后段再去争取也的确是一件更加难上加难的事儿。
以Snowpark打造data apps大数据应用开发者的环境,包含各种现成的大数据软体框架/可重用程式码/流程可以组合套用,既可以开发传统资料仓储的应用,也能作AI/ML的开发,这样的策略定位没错,也能延伸SNOW现有的客户基础与产品优势,但是它毕竟不是一个从Day 1就完全针对AI/ML专案来服务的产品。因此SNOW很短的时间就弄出来了Snowflake Cortex新产品,一个对应AI/ML完整工作流程,整个模型生命周期,全价值链的管理方案,还提供云端托管+无伺服器执行的服务,更像一个机器学习的生态系。
相较于Snowpark产品是以AI apps开发者的视角,随著AI发展的时间演进,沿途迭代开发,加上各种需要的功能元件,Cortex产品则是以AI/ML模型管理者的视角,从上层往下,一次规划好所有工作流程必要的功能模块,然后开始打造。
技术功能如果Snowpark产品家族里已经有的就直接复制进来,需要强化平行处理能力以因应搜寻,推论等大量需求的,就使用NVDA相关软体框架去开发,甚至直接套用NVDA已经包裹好,将芯片与检索,推论相关软体打包的系统模块。整个Cortex研发进度比预期快,目前有邀请部分客户私下预览试用,六月就会正式商业公开GA发布。
接下来,让我们从AI/ML工作流程与模型生命周期前段,简介Cortex产品
(1)模型的数据整合管理:
Cortex提供AL/ML所需海量多样数据的选,抓,整,洗,存,取的功能,并准备好数据提供训练、推论、甚至模型持续改善使用。
AI初期火起来,把各种杂乱图文影音,以嵌入技术解析成为向量的资料库(RAG),然后再作搜寻,排序等,Cortex也支援了,功能规划甚至更完整。向量的储存,目录索引,查询,检索,Cortex都能作。用户可以编写相似度计算的SQL查询,在Snowflake表里面执行向量搜索,比如找最相近的,或相似度排序比较,甚至根据这个查询结果来作检索。这些向量查、找、搜、排的成果也可以整合到旧有大数据工作者的分析洞察图形介面去,方便他们延伸工作 (应该是用了去年6月并购来的Streamlit产品去实现的)。这些向量数据也被整理好,可立刻被主流的AI/ML模型或软体框架拿去整合取用。一直说向量类产品受惠的投资论述都是新红海,功能无差别,甚至SNOW原本大数据云平台的处理效能就比较强,再加上Cortex与NVDA合作后,实施了相关软体框架,能做GPU加速,平行处理效能大增,也许大规模的向量查、找、搜、排,跑起来会比那些先推出的业者还更快。
PS:新产品Snowflake Cortex虽然基本覆盖原有Snowpark里面大部分的AI相关功能,但由于Cortex定位更偏重模型生命周期的管理,因此在模型数据整理的部分,仍然把某些特定功能留在Snowpark里面。比如Spark Connector,可以连接任何以开源Spark技术为本,data lake形式存储的非结构化数据,相当于针对Databricks的Delta Lake产品;再比如Kafka connector,可以连接任何开源Kafka技术(数据流处理)将数据流接入Snowpark,从而实现将最新即时数据进行处理和分析,相当于针对CFLT的核心产品。
(2)模型的训练与验证的支援:
SNOW传统上不是专门训练大模型的计算平台,新产品Cortex也没打算和五朵金花大模型和三大云去直接竞争这件事,而是在功能层面作补强增值,在合作层面深化结盟。
功能层面Cortex更强调模型生命周期的管理,它能管控模型每个版本所对应的训练数据集,追踪模型的验证结果,模型的性能指标记录与比较。原先Snowpark ML就有的模型管理功能,应该全部都被Cortex覆盖了。甚至某些场景, 比如模型很小只有1百万个参数,或只要微调,纳入多几个G而已的新训练资料,Cortex还可以整合外部的云计算资源,比如去呼叫无伺服器的应用计算云服务AWS Lambda,从Cortex把数据丢过去跑小模型或微调的模型,计算后的结果再整合回来Cortex原本纳管的各种细项之下。
合作层面,原有的Snowpark ML可以汇入外部模型,作模型管理。然而可汇入的对象,Amazon Sagemaker,Azure Machine Learning几乎是同样要专注做模型管理的竞争对手,Hugging Face虽然是自然语言处理的平台为主,但是相关的模型管理它也能做,因此汇入外部训练好的模型,在Snowpark产品里,实际可行性并不高。SNOW的合作策略应该要特别争取开源的四大模型才合理,尤其是性能排在前二的Mistral AI,在23年底,它还是五大模型公司里唯一没受到微软,脸书、亚马逊、谷歌这4个巨头所直控或投资的业者。
Snowflake果然在三月与Mistral签订复数年合作协议,和微软,未上市独角兽Databricks一样,都参与了A轮的融资。Cortex在模型管理上也会Mistral Large, Mistral 7B, Mistral 8X7B这些模型做整合。而擅长处理非结构化数据,大数据云平台产品以资料湖为主打,而非资料仓储的Databricks, 在AI初期实质受惠程度比SNOW多,它今年以来和Mistral的合作也比较高调,看来Databricks MLflow可以直接管理Mistral所有模型的实体,metadata相关参数,使用到的数据,排程和部署的执行。而Cortex产品与Mistral的合作,在模型管理与云端部署上是超越Databricks的,可能因为SNOW的客户基础更为雄厚,Mistral可以快速大量接触到财星2000大的客户,产品技术整合的主观意愿更强。目前Mistral模型合作的云端部署5家伙伴是三大云+ NVIDIA + Snowflake,新发布的Mistral Large模型甚至只有微软Azure和Snowflake两家。
补充阅读
Snowflake Cortex supporting LLM: Mistral AI (Mistral Large, Mistral 8x7B, Mistral 7B), Google (Gemma-7b) and Meta (Llama2 70B). All of these foundation LLMs are accessible via the complete function, which just like any other Snowflake Cortex function can run on a table with multiple rows without any manual orchestration or LLM throughput management.
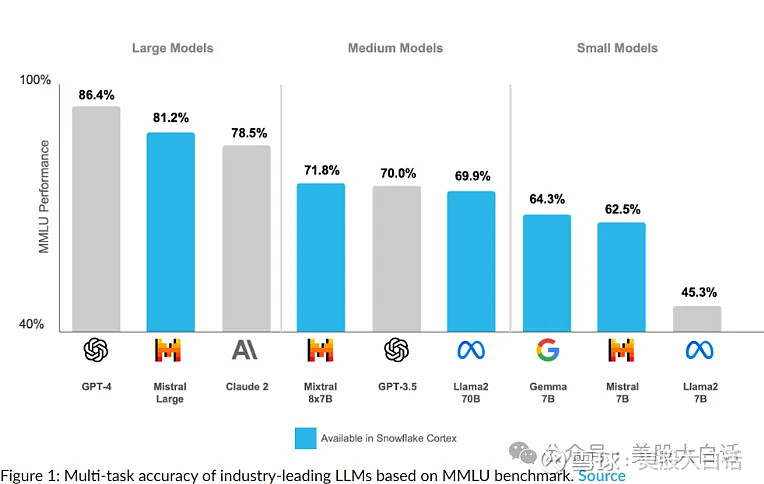
Easy and Secure RAG to LLM Inference with Snowflake Cortex
Snowflake Partners with Mistral AI to Bring Industry-Leading Language Models to Enterprises Through Snowflake Cortex
SNOW在Q4季报后被认为的AI产品短板,都是在AI/ML工作流程与模型生命周期的前2个阶段。SNOW很快的拿出了对策,从产品功能规划与研发,合作伙伴战略结盟的角度,可以说弥补上了。然而市场情绪似乎还停留之前的状态,是还没消化完这些补强进展?还是对SNOW在AI/ML工作流程与模型生命周期的后段,能不能有更大的发挥无法确定?
随著AI的行业发展,训练模型蓬勃,接下来会有大量的模型与应用,进入推论和上线商转。也就是会有更多场景进入了AI/ML工作流程与模型生命周期的后段,主要有三块:
(3)模型的部署与扩展,
(4)协作与治理
(5)监控与维护
这三块强调的是平台的管理功能与系统效能,现有大数据云平台与云端基础建设所运行的规模与绩效卓著,才会被认可未来有能力执行AI/ML的大量推论,上线商转。这也是为何只有三朵云和SNOW这少数几家业者,会被AI世界里地位比较高的模型与芯片的龙头公司,挑选为合作对象。
(3)模型的部署,扩展,上线做大量推论
Cortex在AI/ML工作流程的前2个阶段几乎覆盖掉原本Snowpark里面所有AI相关的功能,但是在模型部署的阶段,SNOW则是呈现了Snowflake Cortex和Snowpark Container Service容器服务,两种不同的选择给企业客户。
Snowpark容器服务
Snowpark容器服务把训练好的模型程式码,还有针对SNOW平台优化过的调度/排程/效能/安控等环境配置参数项目,像一个瓶子一样包装起来,轻易的丢去不同的节点和区域去部署,依照任务性质来选择CPU或GPU,来执行推论。
比较合适用Snowpark容器服务来部署的场景是,企业客户在AI应用程序开发过程中,模型有部分使用到一些企业内部原有的,可重用的程式码库library再去客制化调整,或采用了SNOW不支援的外部软体框架再去叠加开发,这样可以用Snowpark容器,包起来快速部署。这对于SNOW已经有庞大客户基础,而且客户们新做出来的AI应用很可能结合了过往的大数据服务和应用程式码会很有帮助。
另外的场景就是,企业客户已经有许多个Mistral Large, Mistral 7B训练好的模型,Snowpark容器服务也可以把每个外部模型的程式码给容器化装进一个瓶子内,整合到企业客户现有运行SNOW平台的工作流程里,借重它处理的效能来执行大量的推论工作。
SNOW在AI/ML工作流程,模型生命周期前2个阶段因为一些先天的劣势而没有争取到那么多的客户把AI任务丢进来,现在出了Snowpark容器服务这招,以犀利便捷的功能+平台处理效能等优势特点切入,在行业发展来到即将有更多训练好的模型进入部署+推论的阶段,把任务争取过来,从竞争策略和产品功能来看都非常正确。
另外一个考量,五大模型公司现在和谷歌、脸书、微软、亚马逊这四家科技巨头的合纵连横,越来越有阵营壁垒分明的趋势,而且技术上一旦该模型与某科技巨头所控的云计算做了深度合作,由于基础设施与平台的一些技术配置跟著优化,其实要转换移植到其他的云去重跑一次模型数据的选,抓,整,洗,存,取,训练与验证模型,费力耗时,坑坑卡卡会很多。SNOW现在只有和Mistral达到战略协议层次的打通,脸书主导的Llamas只支援到2,Gemini状态不明只有文件上轻描淡写说可以,因此产品面有容器服务这招,让现有客户使用其他几家主流模型的,也可以部署过来。SNOW是一家主要靠工作负载按量跳表收钱创收的公司,争取模型部署到SNOW的平台上,后面才有机会发挥。
Snowflake Cortex
前面看到Snowpark容器服务的部署,可破解许多SNOW遇到的艰难场景,但是如果企业客户是一般的标准情况,重视的是模型的各种管理功能,扩展性,运行效能,那么Cortex依然会涵盖了大部分AI/ML在部署,推论,上线商转的需求场景。
一般的标准情况指的是,模型训练才刚开始且跟随主要机器学习软体框架(如Tensor,PyTorch,XGboost,MLflow等)来进行,模型也是以Phython语言开发,会使用到现有SNOW平台已经在跑的分析结果、整理好的资料表格、清洗过的数据,并以SQL来作资料检索的情况。
模型数据的选,抓,整,洗,存,取,模训练与验证,都透过Cortex管理。当模型开始跑推论时,以无伺服器的云服务方式进行,从Cortex启动模型程式码,抓要用的数据丢给SNOW现有平台,Cortex内部的计算资源去跑,甚至也可以呼叫外部AWS上的无伺服器的应用计算云服务Lambda去跑。推论结果完成再整合回来Cortex里面进行后续分析或其他动作。
计算资源会根据任务性质作分配,比如消费者某期间内所有品项的购物金额总和,这种逐项加总,循序计算的任务,丢给CPU跑。比如根据消费者特征和过往行为的各种因子,作多个矩阵计算来推测未来回购的机率,这样需要大量平行处理的就丢给已经软体加速优化过的GPU去跑。由于AI/ML大部分的推论任务都是需要高速平行运算的,企业客户会选择Cortex除了管理,也很期待效能,因此,NVDA的软硬体技术在Cortex的整合实现就很重要。
去年8月SNOW就跟NVDA订了1000片H100的GPU卡, 是B2B SaaS里面很少这么早买这么多的。它不是为了在实验室作研究,而是要打造Cortex商用级的无伺服器AI推论服务,提供云端托管。在战略合作协议的层次高度,而非仅仅采购GPU板卡而已的关系之下,Cortex使用到NVDA的软体技术或系统产品大致包含了CUDA,NeMo,TensorRT,Triton推论专用伺服器芯片。SNOW利用了NVDA提供的CUDA软体工具包,里面的工具和一些可重用代码库,再开发H100平行处理加速的软体,让Cortex的整体计算效能提升。
上线商转以后的检索与搜寻需求,性能要求绝对比自己关起门来训练的时候高得多,SNOW利用了NVDA提供的NeMo软体框架,开发了自然语言对话处理以及检索相关数据的功能,功能看似差异不大,但NeMo优化过的H100跑检索效能强得多。而且外部的模型目前在硬体上几乎都是用H100在训练,因此Cortex整合外部模型程式码进来得时候,以Nemo写的检索跑的通,也更快。
Cortex在模型推论和部署的执行上,使用TensorRT软体开发工具包作开发,它包含了比如精度校正,多层融合等等,类神经网路的软体优化技术,可以提升深度学习模型在跑推论的效率,让H100的反应时间更快,资源使用更少。
SNOW在深度学习,类神经网路等软体优化技术的研发人才,必然没办法短时间要承载那么大Cortex推论的开发工作,以及潜在众多客户一旦采用后暴增的技术支援。NVDA把H100的GPU硬体和自家研发人员已经用TensorRT软体优化好的各种推论任务软体,打包成一个半成品的系统,经过验证测试可以让客户快速导入。Cortex就有套用这样的产品,Triton推论专用伺服器芯片,开发进度更快,之后要对企业客户做技术支援,应该操作介面也会比较简单。
NVDA这些用于Cortex的软硬体技术或产品,也同样用在了Snowpark 容器服务里。
Mistral 7B这种70亿参数等级的大模型,甚至Mistral 8X7B还需要多个模型一起跑,有用到现有SNOW大数据平台的分析结果、表格、数据,也有外部或者新拉进来的数据,推论的任务甚至有些是即时性很高的预测,这种繁复大规模的情况,Cortex的管理功能,结合无伺服器应用服务的架构,NVDA的效能加持,在模型部署与推论的优势就会有差异化。
Cortex以无伺服器的应用服务方式跑AI应用并做云端托管的另一个好处是,许多企业客户不见得能买到足够的H100硬体来做模型训练推论、开发AI。Cortex方案就能帮助它们启动。
(4)协作与治理
AI/ML模型部署上线后,接触真实世界不断流动的海量多样数据,大量执行推论的工作。AI应用商转所使用到的数据,资安隐私管控、治理方式与权限、共享机制、协同作业;整个体系的管理功能,Cortex都有提供,也可和原有SNOW大数据云平台整合在一起,作单一平台管理。
(5) 监控与维护
AI/ML模型部署上线后,需要持续监控它是否性能退化和资料偏移。Cortex可提供系统监控工具,也可以系统集成到其他的视觉化系统监控平台来监控性能(类似OPEN AI GPT计算跑在微软Azure云上,它们有整合DataDog的系统监控,让IT人员可以在现有的DataDog系统监控平台就可以观测到模型的运转性能)。常见的维护作业,比如加上新资料重新训练模型,无缝免停机升版,也都支援。
对于企业B2B SaaS公司而言,现有功能的营收来源无论是工作负载,数据用量,还是模组订阅,要能真正被AI应用给带动,也会发生在(4)与(5)这两个阶段。
Snowflake Cortex涵盖整个AI/ML工作流程与模型生命周期,从模型数据的选,抓,整,洗,存,取,到模型训练、验证、部署,扩展,推论、协作、治理、监控、维护,提供完整的管理功能,经NVDA深度优化的平行运算效能,以无伺服器的应用服务方式跑AI应用,并做云端托管。这样看来,很像是一套AI版的AWS体系。
从AI/ML工作的本质,大数据领域的发展方向, 如何才能对企业客户提供价值,这几个角度来看,SNOW 不得不往这个方向走。有别于其他商用B2B SaaS会以开发一些上层的AI应用为主(如文件的AI解析),大数据类的公司必须处理AI新衍生的下层的数据基础建设工作,也就会和三朵云出现竞争。事实上,Databricks也在开发类似Cortex的管理方案,但是在AI/ML工作流程的后段,它的地位就反过来,变得比较弱了。
目前五大模型虽然大致上都声称公平,技术都支援三朵云,但类似Snowflake Cortex这样整套管理方案的伙伴,也渐渐壁垒分明:
GPT和微软Azure深度绑定。
亚马逊投资Anthropic较多后,AWS也成为Claude3模型主要云端部署与管理的方案。
Gemini是谷歌把开源Gemma商业化的自家版本,自然而然会在自家云GCP上做所有的事。
脸书开发但开源的Llamas目前还要再观察它的策略,初步来看是微软Azure的支援较多,但AWS也有技术整合,Snowflake Cortex也和它有打通。脸书的功利风格很有可能未来会改变云端伙伴的策略。
因此,SNOW和Mistral与NVDA的合作就更显得珍贵。拉到Mistral模型当队友,至少五大里面有一大,会跟SNOW深度优化与功能整合。
Snow & NVDA:
NVDA对其他科技巨头而言,只会有GPU硬体这个层次的合作,不可能太深度的用NVDA软体,或者它包裹的特定任务,半成品的解决方案,以免让NVDA的AI企业平台渗透进来,主导它们的相关软体与应用,科技巨头都会自家的。SNOW相对科技巨头而言没那么强势,更需要NVDA这些AI软体技术的支援,但是客户基础与大数据平台的成绩又足够大,让Cortex可以藉著NVDA的技术加持,成为一套AI版的云计算基础设施。这样也就能让NVDA后续很多AI企业平台的各种软硬体产品,藉著这个云端托管服务来推出去。NVDA不想只做个卖芯片的,SNOW才有机缘做个AI版的云平台。
SNOW & AWS:
那SNOW会不会与AWS关系出现恶化呢?应该不至于。目前SNOW的营收八成的来源都是分析用途的资料仓储(计算),但资料存储在AWS S3,双方已经建立起共生的生态。Cortex作云端托管,里面许多的功能,比如无伺服器的计算服务,推测也是采用AWS来实践,因此也是延伸原本的共生模式,有钱大家一起赚。另外亚马逊在与Anthropic的Claude深度合作后,必然就会少掉Mistral这块的商机。有了Snowflake Cortex去补这块,反而得利。
总结来说,Snowflake Cortex产品的布局其实是深谋远虑的。当然Cortex也有规划一些上层的应用,比如Copilot助手,Document AI智能文件解析,不过这都是小配菜了。我们期待六月初Snowday正式发表新产品后再写更细的评价。
现在市场对于Snowflake的预期已经调整得非常低了,但事实上从上周微软和谷歌云收入的业绩已经看到了Cloud optimization趋缓的证据,这对于Snowflake来说无疑是一个重大利好。外加我们以上对于SNOW新AI产品的布局分析,这个时点上,无论如何,我们都不应该更悲观了。
最近业绩有点多,这篇长文也拖了些时间,之后的更新会努力提速的,也欢迎大家私信我你们感兴趣的、想了解学习、希望看我写写的美股公司。
下期预告
聊聊Snowflake头疼的竞争对手Databricks
欢迎关注、收藏、点赞、转发~