要点概览
我们研究了GPU在不同数值表示、内存容量、带宽以及互连带宽方面的计算性能,使用的数据集包括2010年到2023年常用于机器学习实验的47个ML加速器(GPU和其他AI芯片),以及2006年到2021年的1948个GPU。主要发现如下:
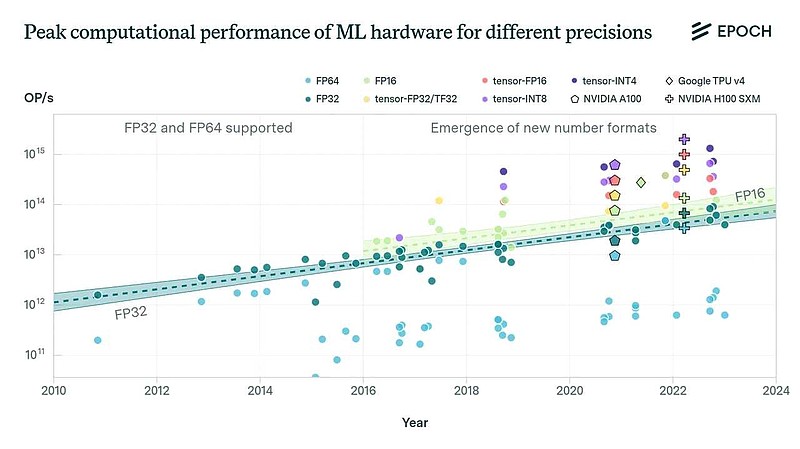
1. 与传统32位浮点数(FP32)相比,低精度数字格式如16位浮点数(FP16)和8位整数(INT8)等与专用张量核心单元相结合,可以为机器学习工作负载带来显著的性能提升。例如,尽管使用的数据量有限,但我们估计tensor-FP16比FP32的速度快约10倍。
2. 鉴于用于SOTA ML模型训练和推理的大型硬件集群的整体性能取决于计算性能以外的因素,所以我们研究了内存容量、内存带宽和互连,发现:
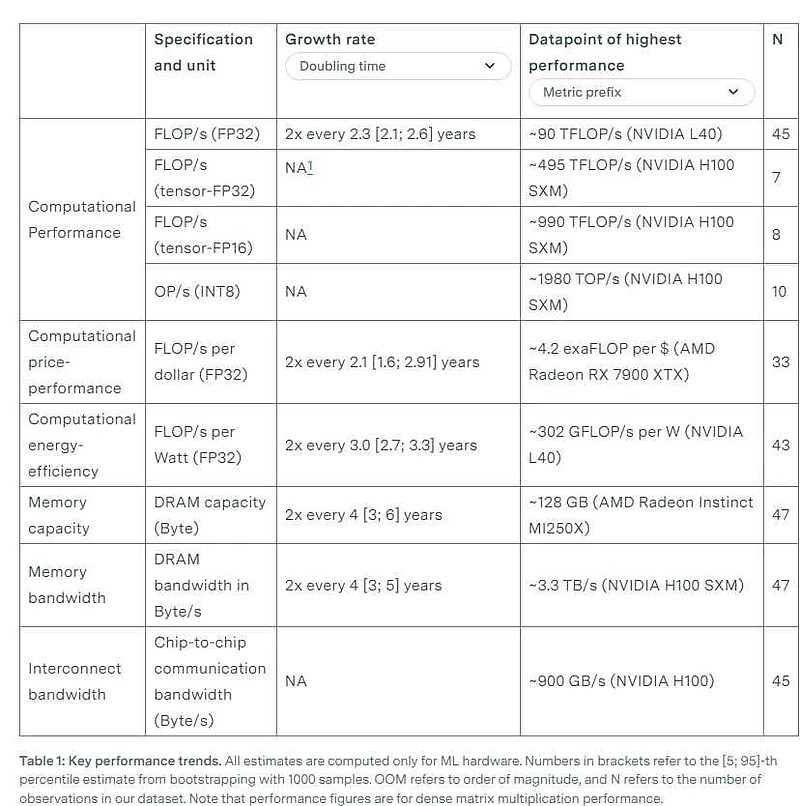
内存容量每4年翻一番,内存带宽每4.1年翻一番。它们的增长速度比计算性能慢(计算性能每2.3年翻一番)。这是一个常见发现,通常被称为内存墙(memory wall)。
最新的ML硬件通常配备专有的芯片间互连协议(英伟达的NVLink或谷歌TPU的ICI),与PCI Express(PCIe)相比,这些协议在芯片之间提供了更高的通信带宽。例如,H100上的NVLink支持的带宽是PCIe 5.0的7倍。
3. 分析中发现的关键硬件性能指标及其改进速度包括:ML和通用GPU的计算性能(以FLOP/s计)都是每2.3年翻一番;ML GPU的计算性价比(以每美元FLOP计)每2.1年翻一番,通用GPU每2.5年翻一番;ML GPU的能效(以每瓦特FLOP/s计)每3.0年翻一番,通用GPU每2.7年翻一番。