
一说到计算机视觉,大多数人第一时间联想到的便是“人脸识别”、“自动驾驶“、道路检测”等跟我们日常生活息息相关的关键词。而在2024年的5月末,微软在GitHub上面上传了这样一个计算机视觉的项目,完全不包含这些关键词,却吸引来了无数人围观,短短两天时间就冲到了700颗星。
这个项目就是Pytorch-Wildlife。项目成立的初衷是因为人类活动导致全球生物多样性急剧下降,对野生动物种群的全面监控变得尤为迫切。
可是想要完全利用人力,来对某一种群或者某一块栖息地进行24小时监控,这显然是不现实的。不仅仅是因为成本过于高昂,而是人类肉眼很难完整观察清楚一些行动迅敏的动物,这就会导致没有办法准确记录物种以及栖息地情况。于是在这个大背景下,Pytorch-Wildlife诞生了。
PyTorch-Wildlife是一个用于创建、修改和共享强大 AI 保护模型的平台。这些模型可用于各种应用,包括相机陷阱图像(当检测到动物经过时进行拍照)、俯视图像、水下图像以及生物声学。通俗来讲,项目是利用数据集和深度学习架构来实现保护野生动物的目的。
项目的原理其实并不复杂。首先,利用了Megadetector v5进行对象检测,这是一个预先训练好的模型,用以过滤掉空图像或含有非动物对象(如人类和车辆)的图像。

图:亚马逊丛林的动物
Megadetector是基于Yolov5检测模型架构,专门为动物检测设计的深度学习模型。能够处理来自不同地区和生态系统的大约300万张动物图像。
接下来,对所拍摄的视频和图像进行采集,把采集得到的数据喂给Megadetector v5进行识别筛选。其中,对于视频数据,每段视频按30fps的帧率被拆分成图像帧,如果原视频帧率低于30fps,则使用原始帧率。这种取舍可以平衡模型的运行效率以及识别精准度。
针对检测到的动物对象,Pytorch-Wildlife会将它们裁剪并调整至256x256像素的尺寸,并根据图像级别的标注为每个裁剪图像分配标签。
大多数深度学习模型,尤其是卷积神经网络(CNN),它对输入的素材是有严格规范的。256x256其实是一个常见的选择,因为它既能保持一定的图像细节,又不会使计算负担过大。
在裁剪之后,利用Pytorch-Wildlife的分类微调模块,采用ResNet-50作为基础模型架构,进行动物的识别训练。训练设置包括60个训练周期,批量大小为128,采用随机梯度下降优化器,并设定学习率在每20个周期后衰减。
以往来看,开发者需要对模型进行微调,模型才能够更好地理解和区分特定的动物类别,提高在实际野生动物监测任务中的识别准确率。而Pytorch-Wildlife框架提供的微调模块则简化了这一过程,使得即使是没有深厚技术背景的研究人员,也能利用先进的深度学习技术进行动物识别模型的定制化训练。
Pytorch-Wildlife团队准备两份案例,第一个是在亚马逊丛林中检测动物。
亚马逊雨林是世界上最大的热带雨林,是地球上生物多样性最丰富的地区之一。亚马逊雨林里的动物数量是非常惊人的,已知的动物种类超过了10万种,这包括鸟类、哺乳动物、爬行动物、两栖动物以及其他无脊椎动物等。但是这个数字仅仅是已记录和描述的物种,现代学者普遍认为,还有成千上万甚至是数百万种动物物种尚未被发现和描述。由于亚马逊雨林的广阔和复杂性,新的物种仍在不断被发现,因此确切的动物种类数量是一个不断变化且难以精确统计的数字。
Pytorch-Wildlife使用了一个包含41904张图像的数据集,这些图像覆盖了36个已标记的动物属,其中33569张用于训练,8335张用于验证。
在亚马逊雨林项目中,模型实现了92%的识别准确率,针对90%的数据集在98%的置信度阈值下正确预测。这意味着,大部分动物图像能够被准确分类,只有少量需要人工审核。
除了亚马逊丛林的案例外,Pytorch-Wlidlife还有一个在加拉帕戈斯群岛的项目。这个项目的背景非常独特,虽然加拉帕戈斯群岛的动物种类也很多,然而这个脆弱的生态系统正面临外来入侵物种的重大威胁,这些物种可能改变本地物种的种群动态并导致它们灭绝。
Pytorch-Wlidlife检测到,一些负鼠通过船只、陆地等手段,正在入侵加拉帕戈斯群岛的生态。对本地生物构成了竞争压力,因此连续的监测和管理对于维持生态平衡至关重要。
项目中使用的数据集包含491471段视频,这些视频被标记为“负鼠”或“非负鼠”。数据集被划分为训练集和验证集,分别包含343053段和148418段视频。
经过验证,Pytorch-Wildlife平台训练的模型针对入侵的负鼠识别达到了98%的准确率。比如下面两张图,由于是夜间拍摄的缘故,即便是人的肉眼也很难第一时间分清两种动物。第一张图片是当地的食蚁兽,第二张是外来入侵物种负鼠。

图:食蚁兽

图:负鼠
这部片接下来要怎么拍?
Pytorch-Wildlife在监控和识别上初步取得了成功,不过这对于保护生态平衡上来说显然还是远远不够的。未来Pytorch-Wildlife将会连接LILA:BC数据集,进一步提高对物种识别的能力。
LILA数据集指的是亚历山大图书馆的标注信息库:生物与保护(Labeled Information Library of Alexandria:Biology and Conservation),这是一个专注于生物学和野生动物保护领域的数据集库,提供了多样化的开放数据资源,用于促进野生动植物的监测、保护生物学研究以及生态系统的管理。
LILA数据集包含大量经过标注的信息,比如图片、视频和其他类型的数据,这些数据有助于科学家和保护工作者利用机器学习和深度学习技术来识别和跟踪野生动物,评估生物多样性。此外,通过使用LILA进行与训练,还能够监测生态系统的健康状况。
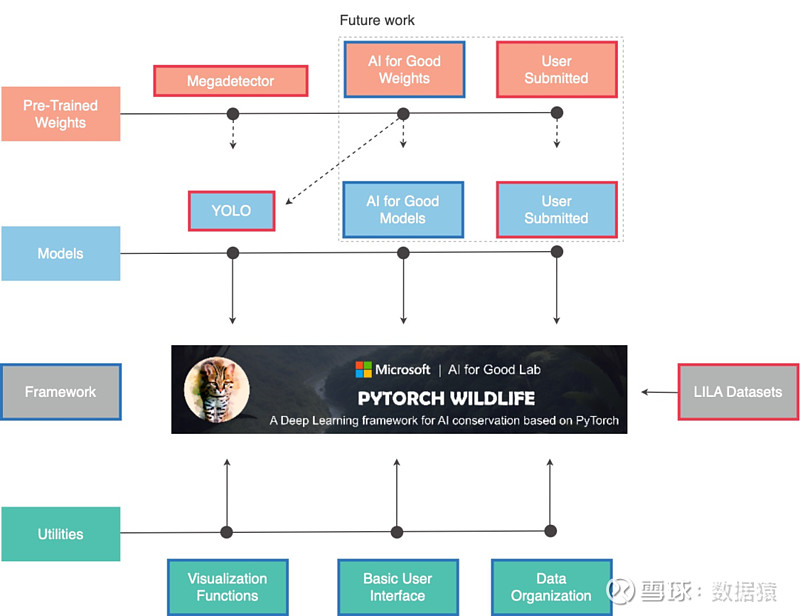
图:Pytorch-Wildlife未来的规划图
数据猿也体验了一下Megadetector的实力。识别模型选择Megadetector v5,检测模型选择的是亚马逊丛林。可以明显看出,只要是亚马逊丛林中出现的动物,Megadetector都能很好的识别出来。
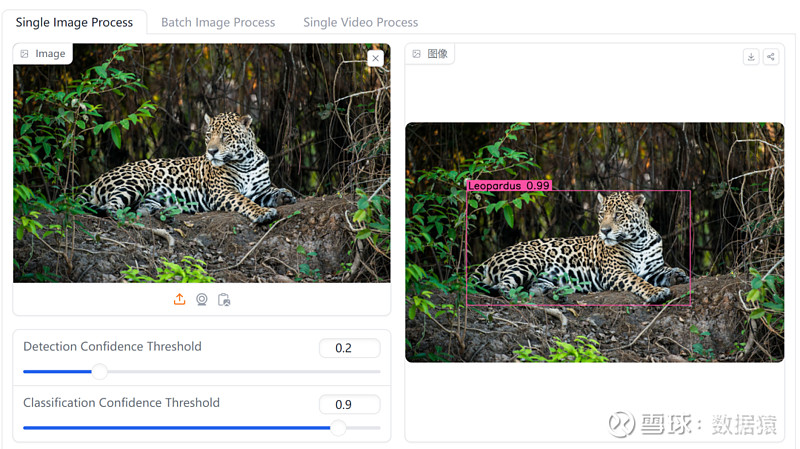
图:亚马逊丛林中的豹子
不过像是数据猿LOGO这种卡通动物形象,即便把识别阈值拉满,Megadetector也没有办法识别出来。相反,如果是真实的动物,Megadetector只需要很低的阈值就能识别。
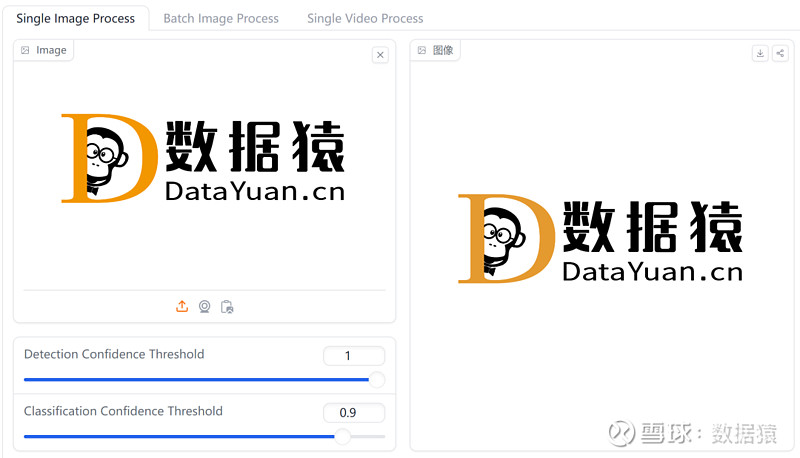
图:Megadetector无法识别卡通动物形象
根据开发团队的介绍,Megadetector的最新版本,也就是Megadetector v6即将上线,识别率远超v5版本,同时消耗的计算资源更低。目前,使用Megadetector v5检测一张图片耗时约为20秒,而v6版本将会让耗时小于15秒。
另外Megadetector v6还会支持更多的低预算设备,这是因为在亚马逊丛林等地,温热潮湿的生态环境会使得拍摄设备损坏率提高,没办法长期维持成本高昂的拍摄设备。然而成本较低的拍摄设备会导致拍摄画面的分辨率低下,帧数低下等等,对Megadetector的识别作业起到非常负面的影响。
在未来,Pytorch-Wildlife会支持更多种类的识别方式,比如鸟瞰图、水下拍摄。这何尝不是一种新的云养殖野生动物的方法?
AI For Good
Pytorch-Wildlife属于典型的AI For Good项目,这个概念由微软提出,不过与其说是概念,更像是一种倡议。它是指在推动人工智能技术的发展与应用,以解决全球性的社会、环境和经济挑战,促进可持续发展。这一理念鼓励科研人员、企业、政府、非政府组织以及社会各界合作,利用人工智能的力量创造正面影响,确保技术进步惠及全人类和地球生态。
不一定非得是动物,其他类似的方式都可以算是AI For Good。例如,通过机器学习算法监测森林砍伐、海洋污染、气候变化和生物多样性减少,以及开发智能系统优化资源利用和能源管理。
事实上,Pytorch-Wildlife的核心,Megadetector,几乎没有办法复刻任何的商业途径。但这个项目依然拥有足够高的关注度,说明人们关注AI,使用AI技术,眼里并不是只有它的商业化能力,而是如何去使用AI,来建设赖以生存的家园。当然了,也有一部分人是冲着这个项目可以免费看真正的野生动物去的。
国内也有不少AI公司着手于类似的项目,比如百度的“绿色伙伴计划”,通过AI来减少碳排放。根据记录,百度地图“低碳计划”全年累计访问量超过 4000 万人次,累计可减少碳排放量超 3800 吨。
还有腾讯的“自然风险评估”,应用AI调优技术,腾讯2023年当年减少用电量约5000兆瓦时,避免碳排放2851.5吨。