什么才是正确的AI创业创新姿势?
答案好像不是做大模型的。吃过见过,和王兴一起创立了万亿美团帝国的王慧文,大模型创业弄了一半,抑郁了,早早就退出了人工智能内卷,他或许提前看到了什么终局?
王慧文的退出,并没有像他高调宣布进军大模型一样,引起什么产业波澜和反思。大家只是感叹有钱人看来只是表面快乐。
无论是大厂还是中小创业公司,大部分继续一股脑继续“造轮子”,做大模型开发。
对于人工智能产业,目前催生三个可见的赛道:
万亿级的是芯片公司,这是属于英伟达、AMD等超级公司的赛道,不属于任何一家中国企业。
千亿级潜力是开发大模型“造轮子”,OpenAI提供了大模型的思路,许多公司在OpenAI开源的基础上去模仿OpenAI开发自己的大模型。但是随着今年4月份OpenAI宣布不再开源,模仿者大部失去了方向,技术水平停留在ChatGPT 2.0左右阶段。
剩下的就是百亿级左右的赛道,各种搭建在大模型上的应用,把大模型作为底层技术,应用在各个领域,例如做各个产业的垂直模型,现在有在尝试医疗、法律、娱乐、绘画、数字人等等领域,目前大部分都处于试水阶段。
目前在中国,AI这条赛道上大家都喜欢抢着造轮子。根据中新财经统计,目前已有超90家中国科技公司发布AI大模型,而这个数字在今年4月份还仅为50多家,人工智能产业正在“百模大战”,目前没有任何盈利模式,非常卷,
然而,造轮子这条赛道,在昨天大概率将被扎克伯格的Meta发布的Llama 2给终结掉。
一、Meta放大招Llama 2,让“造轮子”大模型创业者们心头一凉
昨天,Meta宣布Llama 2激起整个人工智能产业震荡。Llama 2即扎克伯格创建的Meta(Facebook)旗下专门推出的商用开源大模型。据Meta官方介绍,Llama 2大语言模型系列是经过预训练和微调的生成式文本模型,其参数数量从70亿到700亿不等。
Llama 2其参数和实际测试已经达到ChatGPT-3.5左右水平,先不说中小创业公司,国内就算许多大厂,如文心一言、通义千问、360智脑都不能达到这个水平。
作为人工智能领域权威之一的机器学习科学家内森·兰伯特( Nathan Lambert )直言,Llama 2 性能是超过GPT-3的,对许多闭门造大模型的公司是个巨大的打击,这个模型(Llama 2)将满足大多数公司对更低成本和个性化的需求
Llama 2对于人工智能应用,就像手机APP开发之于安卓操作系统一样,其目的就是让应用层开发者们不用重复造轮子,直接用最低成本获得大模型的基础设施使用。
几个月前,Google曾公开表示,因为有开源社区,我们(Google和OpenAI)没有护城河。或许是美国巨头们已经想明白,大模型本身并不具备护城河,而是某个开源大模型上面形成的应用生态将是最大护城河。
这个生态看起来是美国巨头们蓄谋已久。作为Meta宣布的首批合作伙伴之一,亚马逊云科技宣布,客户可通过Amazon SageMaker JumpStart使用由Meta开发的Llama 2基础模型。
而OpenAI 的密切合作伙伴微软,这一次成了 Llama 2 的首要合作伙伴。在未来,任何个人开发者或者中小公司,都可以最低成本调用Llama 2。
猎豹CEO傅盛在第一时间转发了Llama 2的文章,并配文“这一下不知道多少公司笑醒在深夜,多少公司哭晕在厕所”。
朋友圈下面,前搜狗CEO、百川智能创始人王小川留言:哈哈哈。表示赞同。
而此前就说公开说“大模型本身没有价值”的金沙江创投合伙人朱啸虎则留言说:“都是笑醒吧,又可以take free ride”,意思是大家都可以用免费的“轮子”了——OpenAI已经不再开源,而Llama 2的出现拯救了大家。
傅盛随后在其视频里公开表示,Llama 2将会让大模型白菜价、平民化,像自己这样做人工智能应用落地的才是正确的方向。
《量子连线》采访了一些在看人工智能项目的投资人,他们都表示目前已经不会再投“国产大模型”。业内许多人已经达成共识,大模型就是一堆代码,如果没有落地产业生态,意义不大。
目前看来,大模型需要生态,以及大规模资金投入,这也不是一般中小创业公司和投资机构能长期承担的,美国方面有科技媒体透露Llama 2目前保守估计训练成本高达2500万美金。而整合亚马逊云,微软等生态更是不可想象的资源。
百度高管吴甜曾在几天前表示,真正从底层做起来的大模型成本非常高,国内大模型终局将只有几家能活下来。
只是想不到终局来得如此只快速。
二、搞基础设施是浪费资源,硅谷创业者反而比较清醒。
王小川曾在4月份说中国大模型比美国技术落后了3年,而百度方面则认为没有那么大差距,为此双发还打了嘴仗。
也许是监管和中美环境,让中国大厂们,甚至创业者心存侥幸,觉得还可以有几年的发展空间,还能在基础设施上努努力。但是随着监管规则的落地,以及硅谷大模型基础设施的逐渐成型,再做轮子已经没有任何意义。
其实在硅谷,大部分中小创业公司并没有在重复造轮子,他们早已经开始研究人工智能应用方向。例如最近兴起的AI Agent概念——AI工具能够自主工作和反馈,感知所处工作环境并作出反应,通过自主决策和行动完成某些任务,还能通过学习、反思进行迭代。整个过程几乎不依赖人类的指令和监督。
大模型,在未来更多将是像云一样的基础设施,需要的企业或者用户直接进行采购和调用。
一些接受采访的软件开发者对《量子连线》表示,调用大模型非常简单并且成本不高,一些开发者在今天已经开始测试调用 Llama 2。
甚至一些把自己的微信聊天接入了。之前他们需要使用一些类ChatGPT的开源软件,现在直接使用 Llama 2,有了 Llama 2 这样的开源大模型,自研的意义更小了。
傅盛预言,未来几个月,大模型开发者将面临大规模裁员。
ChatGPT 可能也会死的很惨,meta 开源了大模型以后,谷歌也上阵了,openAi的人都回谷歌了。
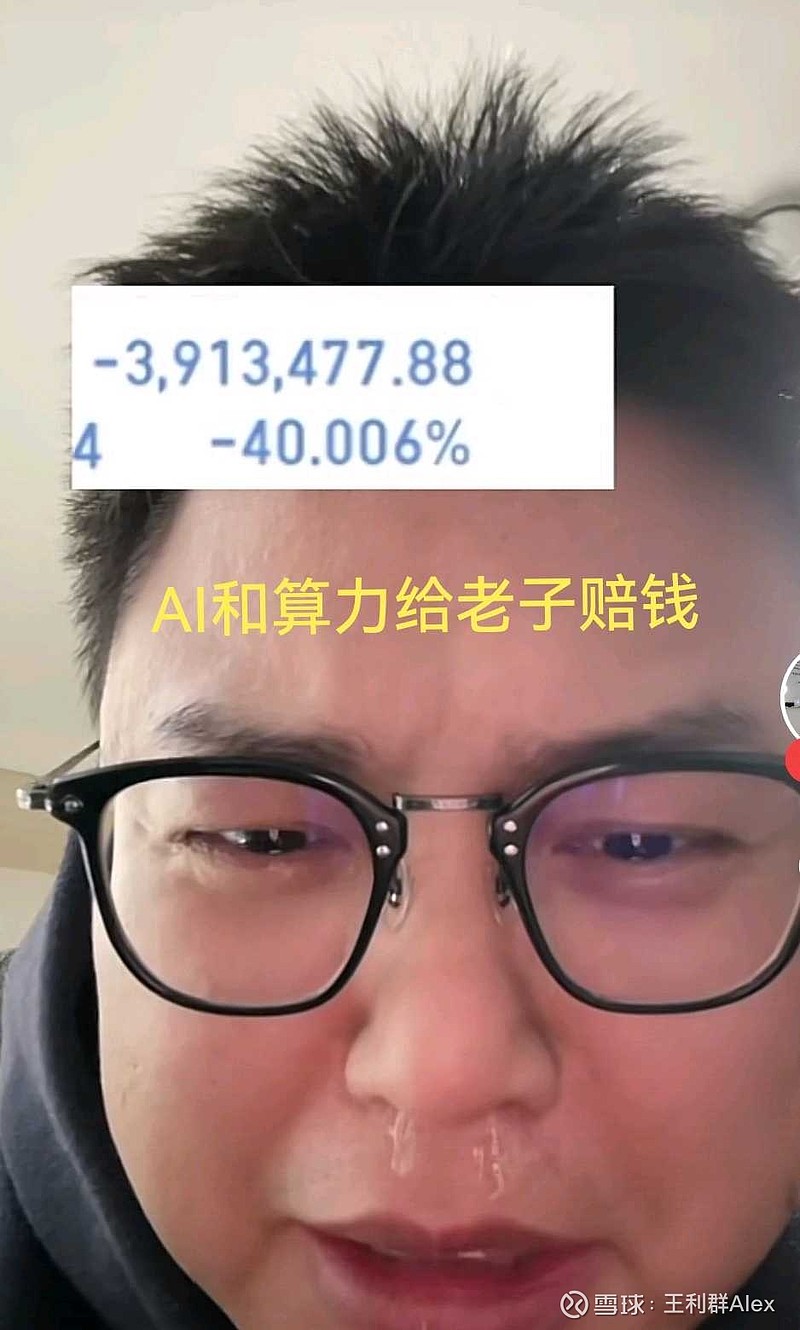
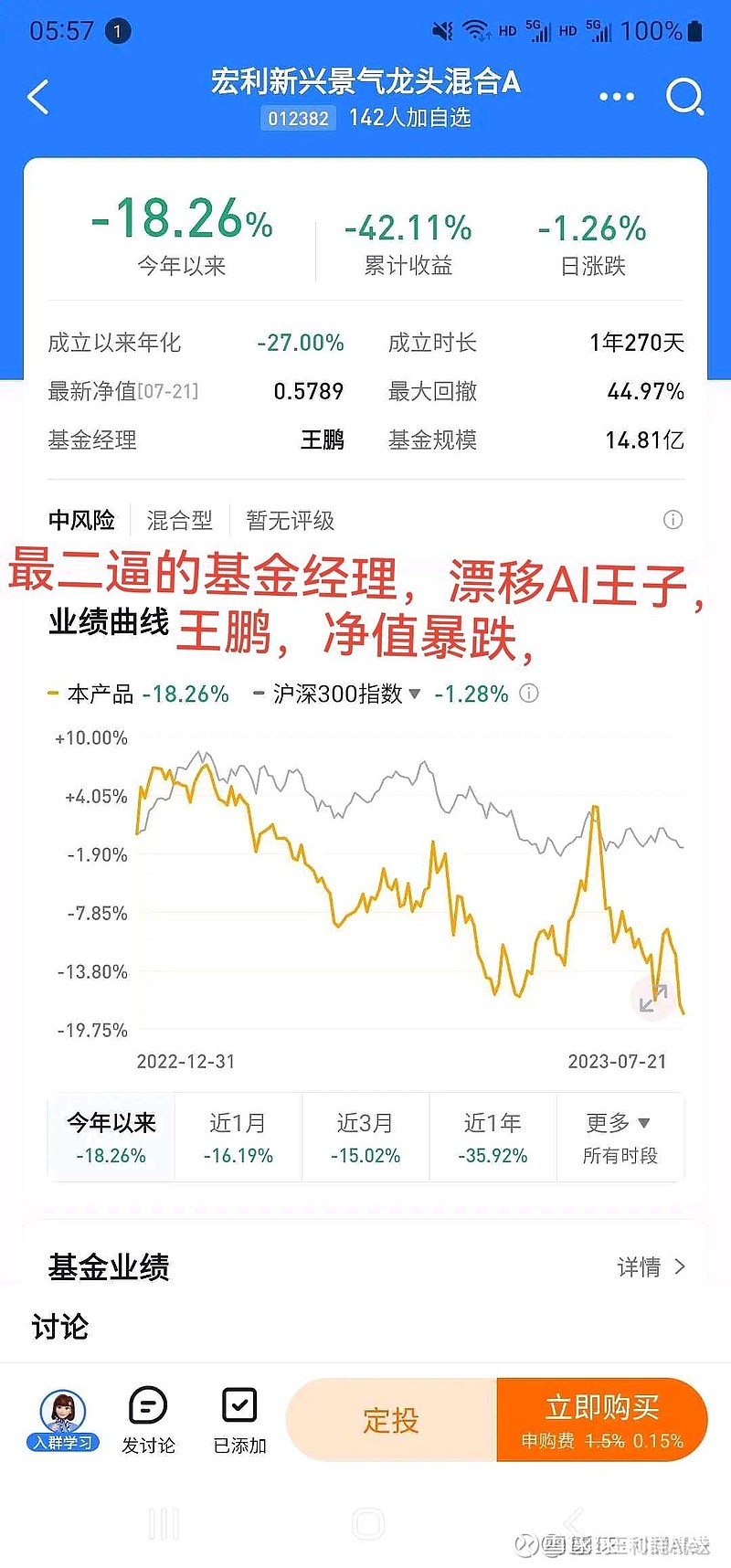
鸡狗们不知道拿什么吹牛了,所谓的算力都是伪需求,而且循环不需要 AI 芯片,就是慢一点而已,一样用。CPO,算力,芯片,AI服务器基本上判死刑了。
而对于阿里云,百度这些All in大模型的大厂来说,Llama 2也将给他们造成巨大的压力,如果相同的价格,为什么开发者不去用价格更便宜,性能更好的大模型呢?
【阿里大动作 ,投资5年后清仓式减持了AI巨头商汤,今年股价跌幅近23%】
【AI泡沫巨大,美机构预测英伟达未来会下跌50%以上】
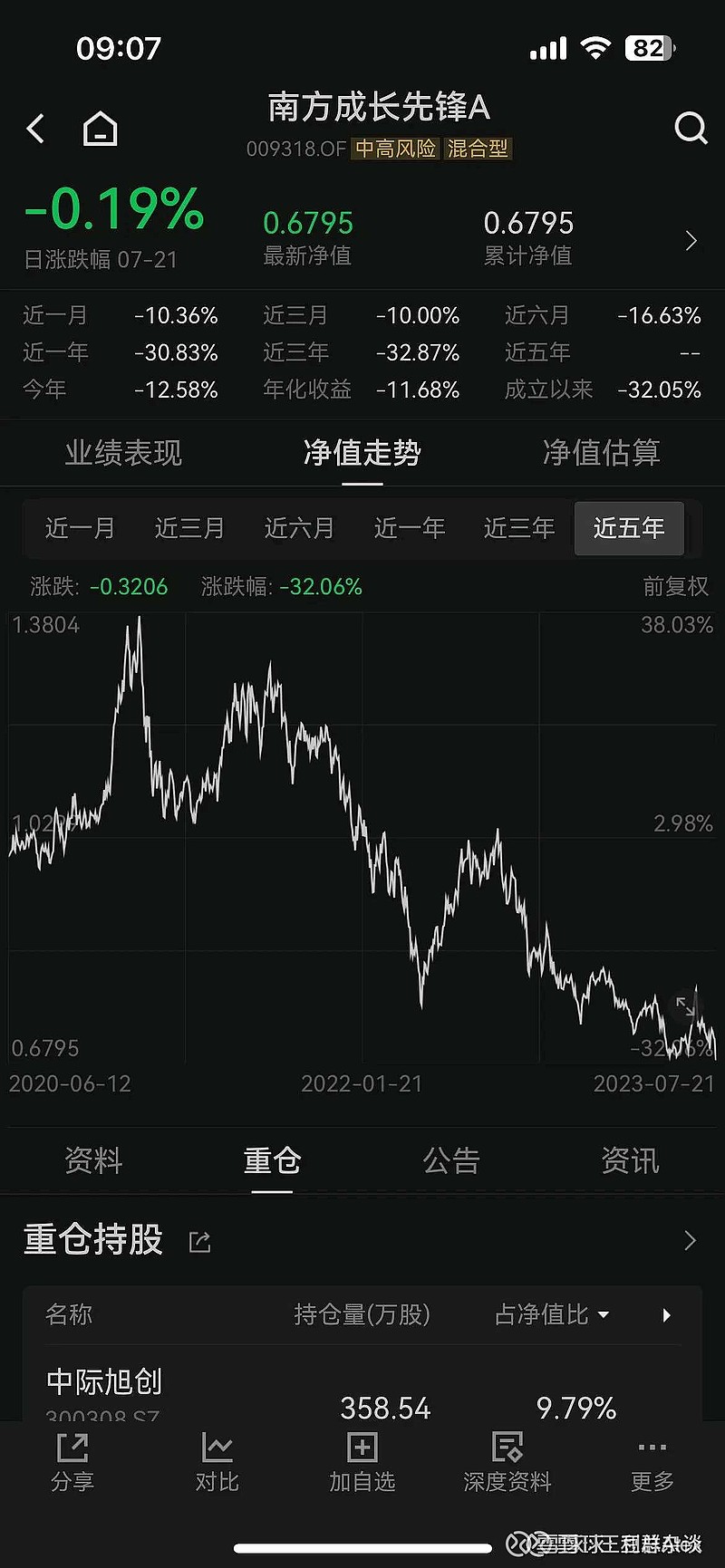
$浪潮信息(SZ000977)$$三六零(SH601360)$$中际旭创(SZ300308)$