$海康威视(SZ002415)$ 再也不用怕老美了,华为周五推出人工智能芯片了,性能超谷歌和NVIDIA。
华为8月23日在深圳举办专场活动,发布Asend 910 AI处理器和MindSpore开源计算框架。此次活发布会由华为轮值董事长徐直军主讲,首席战略架构师党文栓、芯片和硬件战略Fellow艾伟、云BU EI产品部总经理贾永利参与Q&A环节,级别相当高。
结合公开资料,Ascend 910应该就是华为自研的“昇腾910”处理器,在本周一开幕的行业顶级会议HotChips上,华为曾简要介绍了Asend 910的部分细节。

会上PPT显示,Asend 910基于达芬奇(Da Vinci)核心架构,采用7nm增强版EUV工艺打造,单Die内建32颗达芬奇核心,半精度高达256TFOPs,功耗350W。Ascend 910 的运算密度超越了竞品NVIDIA Tesla V100和谷歌TPU v3,华为还设计了拥有2048个节点的AI运算服务器,整体性能多达512 Peta Flops(2048 x 256)。
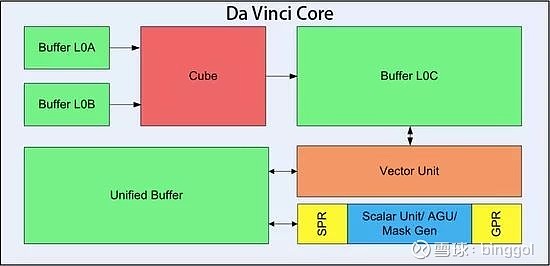
另据华为官方微信,达芬奇主要由核心的3D Cube、Vector向量计算单元、Scalar标量计算单元等组成,3D Cube针对矩阵运算做加速,大幅提升单位功耗下的AI算力,每个AI Core可以在一个时钟周期内实现4096个MAC操作。同时,Buffer L0A、L0B、L0C则用于存储输入矩阵和输出矩阵数据,负责向Cube计算单元输送数据和存放计算结果。