(欢迎从上篇文章的精装房回到毛坯)
Ayar Labs CEO昨天在OFC上的采访:
如果想最终改变计算行业,就需要实现电IO 到光学 IO的巨大的提升。我们目前的代工厂是Global Foundry和Intel,GF负责制造,Intel负责封装。去年我们出货了几万颗,未来的目标是每月几千万支的产能(注意是远期目标)。我们每个chiplet产品包括1个supernova激光器+光 IO芯片TeraPHY。目前计算卡间的电IO到了单通道800Gb,而我们的光IO是每个chiplet实现4Tb,如果客户使用8个chiplet就是32Tb/s(4TB,也就是目前NVlink的2倍多,感觉是在和电IO赛跑,毕竟博通已经展示了serdes的roadmap也在加速,1年1迭代)。且我们路线图未来是要从单chiplet 4Tb继续翻倍到8、16、32Tb/s。此外电缆的缺点就是距离限制,而我们光IO实现了10-100米直接光纤连接,也就是机柜内,甚至数据中心内机柜间。而且赋予了架构设计的更大灵活性,比如计算模组和存储模组之间的距离可以放的更远,过去必须在2米内,有了光IO可以更灵活更远距离的走线分布。关于光IO的应用,会在2026年kicking up(起步),28年之前会看到“huge step大进步”。关于竞争,我们相比于对手是遥遥领先,目前是唯一一个实现了小规模量产和出货的,已经是商品ready状态。
OFC后Marvel上涨,citi花旗评论:
使用铜缆还是光缆的讨论一直困扰着MRVL和COHR(原来美股也一样...)然而,OFC上的反馈大多数对光学供应商们更为积极。我们将Marvell放进“30天催化剂观察名单”,这个报告引来了大量投资者反馈,3月8日季报电话会后,投资者普遍悲观,主要源于企业网络/运营商等非AI业务疲软,以及GTC期间对如NVLink Switch等基于铜缆进而对光学的担忧,股票表现不佳,这让MRVL相对于AI同行的估值有18%的折扣。但目前GTC和OFC的举办,加上即将具备的4月11日的AI day,可能会是股价催化剂。此外,我们在OFC总结中指出,光学DSP价值量稳定,没有大规模使用LPO/CPO的迹象。我们预计Marvell将在AI投资者日讨论预计到2027年将达到400亿美元的定制ASIC市场空间,并讨论包括AWS Trainium 2(5nm)/基于Arm的CPU在内的定制ASIC的上量。尤其值得注意的是,像NVDA、AVGO和AMD都在各自的AI日前后有所上涨,MRVL在最近回调之后,可能也有类似的上涨动力。
对Coherent(Finisar)的评论:与MRVL在OFC第一天发表的评论类似,COHR估计,上周在GTC上宣布的新的NVLink Switch并没有改变架构,GPU到GPU的连接一直是铜缆,而光学连接则是将GPU连接到交换层。NVDA的业务发展副总裁Craig Thompson指出,Grace-Blackwell将使用铜缆进行扩展(GPU到GPU的连接),并使用光学技术扩展到最多32,000个GPU(444个机架)。这表明每个GPU的光学带宽将增加一倍,从H100 GPUs的400G增加到GB200的800G。这些评论让我们感到安心,因为尽管有铜缆的创新,AI集群内的光学内容似乎保持不变。COHR重申其800G的销售额在12月季度增长了100%以上,达到1亿美元。管理层预计即使1.6T产品在2024年下半年上市,其800G光学产品仍将继续增长。COHR预计到2024年下半年,销售额将增长3倍,达到4.5亿美元。


对康宁的评论:康宁管理层指出,尽管英伟达新的铜背板技术中增加了铜缆含量,但这并不影响光纤含量,因为预计短距离GPU到GPU的连接仍将使用铜缆,而光纤将主导到交换机架的长距离连接。
MS对OFC的总结:
对800G/1.6T的需求保持乐观,LITE指出到2028年IDC光学市场约有160亿美元市场空间(约30%的复合年增长率)。短期内上行空间围绕800G(LITE指出2Q24光模块市场收入的75%来自800G,COHR表示1.6T的时间表应该很快预计在2H24/1H25开始发货。更远距离如ZR,竞争加剧,客户寻求降低成本(降低50%到90%不等)


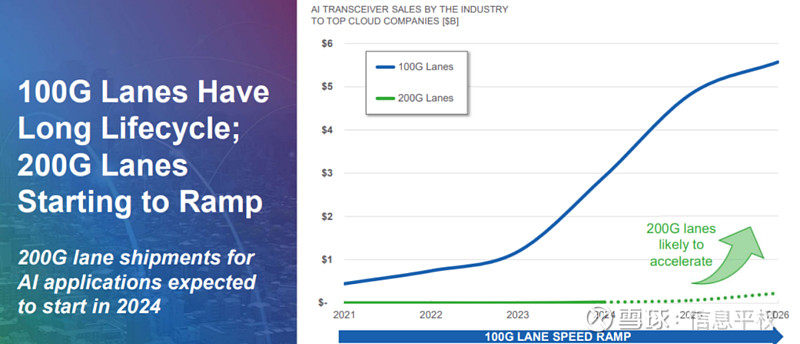
随着数据中心的速度和带宽需求随着AI增加,架构未来的方向是光学和电子更紧密地结合。虽然CPO可能是最佳的长期解决方案,但在包装、可靠性和可行性方面仍存在挑战,需要在未来几年内解决。因此,多数厂商认为某种形式的LPO将是中间过程。然而,思科等也指出LPO存在互操作性上的挑战,像LRO这样的半解决方案的可能性。
思科在OFC上的分析对话,其中对硅光的经济价值思考:
光通信的一个经济模型,影响了我们的决策,也影响了我们的很多投资,那就是交换机的端口成本与光学成本之间的关系。在10G时,光学成本约占整个BOM成本的 10%,而端口+ASIC成本约占 90%。到了100G,这一比例接近 50%,原因是ASIC所提供的带宽容量capacity已经大大提高。我15 年前来到思科,当时我们的交换机是40G带宽容量,如今我们单个ASIC就提供50T带宽。从 40G到 50T的扩展,极大地节省了端口的单位比特成本。但光学成本的下降速度没有那么快,因为光学不仅仅是硅,还有各种元器件、分立器件、DSP 、激光器,这是一个复杂得多的组件。其结果是,光学元件在总成本中所占比例越来越大。因此在100G时,光学元件约占成本的 50%,而在 400G和 800G时,光学元件接近总成本的 70%。这影响了我们对光学投资的思考。因此在过去十年时间里,我们进行了一系列收购,尤其是硅光,比如Acacia,当然我们意识到可能会蚕食一部分光学业务,在经济上对客户来说是一个很好的答案,它简化了网络。
最后是贾扬清大佬的新采访,受益匪浅(from腾讯科技):
AI计算与“云计算”有很大的不同,云计算主要服务于互联网时代的需求,关注资源的池化和虚拟化,在这种虚拟环境下把利用率做上去,或者说超卖。互联网的主要需求是处理各种网页、图片、视频等,分发给用户,让“数据流转(Moving Data Around)起来。云服务关注数据处理的弹性,和便捷性。AI计算更关注以下几点:一般训练会“独占”物理机,除了简单的例如建立虚拟网络并且转发包之外,并没有太强的虚拟化需求。需要很高性能和带宽的存储和网络。例如,网络经常需要几百 G 以上的 RDMA 带宽连接。因为机器本身的故障率并不高,没有过度复杂的调度和机器级别的容灾。今天的AI计算 ,性能和规模是第一位的,传统云服务能力是第二位的。
英伟达的Super POD,与最早的高性能计算机HPC非常相似,长的也很像(这一点最近感受越来越深刻)这就意味着,我们又从“数据流转”的需求,回归到了“巨量运算”的需求。
通用大模型性能固然很出色,但是在实际应用中,使用中小型开源模型,并用特定数据微调,最终达到的效果可能更好。成本:一台GPU服务器就可以提供支撑的7B、13B模型通过微调,性价比可能比直接使用闭源大模型高10倍以上。在北美,很多企业都是先用闭源大模型来做实验(比如OpenAI的模型)。实验规模大概在几百个million(百万token),成本大概为几千美元。一旦数据飞轮运转起来,再把已有数据存下来,用较小的开源模型微调自己的模型。现在这已经变成了相对比较标准的模式。半年之前我非常强烈地相信开源模型能非常迅速追赶上闭源模型,然而半年之后,我认为开源模型和闭源模型之间会继续保持一个非常合理的差距

个人认为英伟达在接下来的3~5年当中,依然还会是AI硬件提供商中绝对的领头羊,它的市场占有率不会低于80%。但今天需要写最底层的模型的人越来越少,越来越多的需求是微调开源模型。能够跑Llama、能够跑 Mistral,就能满足大概80%的需求。
去年硬件需求的突然暴涨,整个供应链都没反应过来,等待时间很长。最近我们观察到的一个现象是供应链没有那么紧张了,我个人判断有一部分以前因为焦虑而提前囤货的供应商,觉得现在要开始收回成本了。之前供不应求的紧张状态会逐渐变好,但是也不会变成愁卖的状态。
(文中citi ms报告已上传知识星球)
