(声明:纯技术讨论,与股票无关)
今天聊了很多技术大佬,大脑超载...在HW云大佬的推荐下,考古了不少好东西,一是知乎夏core的一篇文章,一个是英伟达首席科学家Bill Dally的演讲(都强烈推荐),不仅对今天在思考的问题给出了答案,甚至描绘出了未来清晰的技术演进路径...
1. AI Factory 还是AI Cloud
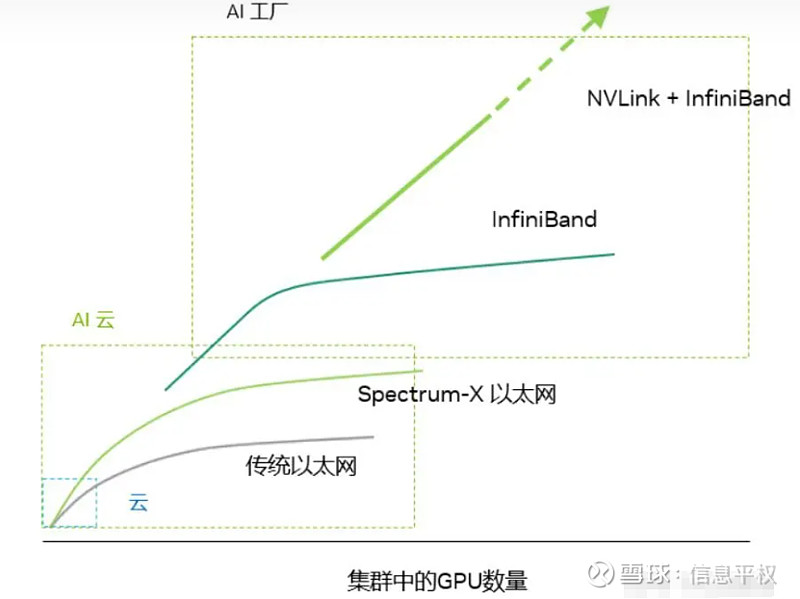
什么意思?我们前两天文章讨论的HB domain超节点,超节点越小比如8卡一个node,就是AI cloud;超节点越大就是AI factory。AI factory专门用于大模型这一单一任务,虽然系统成本看起来高,但利用高速的短距电/光传输,把每GBps的高带宽互联成本做到比传统网络互联还低,因为要满足模型训练中巨量的All Reduce和All2All,因此需要局部紧耦合。而AI cloud用于多样性任务,适配千奇百怪网络,可实现不同尺寸网络组合(scale-out灵活性更高),由于scale-out过程中带宽急剧收敛,系统总成本较低,但单位GBps带宽的成本不见得低,因为HBD小意味着HB数量多,scale out需要更多的“连接”,且都是走光路。
(这里插一句,前两篇一直在引用的meta和MIT那篇讨论最优HB Domain的论文,要特别留意的是其目标是将网络成本优化到最低,在这个约束下得到了HB Domain最佳256的结论,但如果约束条件是超大模型的训练性能,比如10万亿参数、尽可能高的MFU、更快的训练速度,很可能对HB Domain的追求不会停止...那NVL 576的确也有用武之地)
回到AI cloud,因为HB Domain较小,对Tensor并行的支持范围较小,因此AI cloud其实对不同尺度模型的支持能力较差,比如无法承受巨量的All Reduce带宽,不适合模型训练。但由于HBD较小,容错要求不像NVlink网络那么高,带宽随机、路由随机,老黄说的“最后一个学生交作业”问题没那么显著,而这点让UEC超以太在AI Cloud有了用武之地。
那么回到商业,就很清晰了,AI Factory的利润率显然远高于AI Cloud,一个是卖GPU+NVlink+IB的整个系统(额外增加了20-30%收入),一个是只卖卡+白盒让客户自己攒。因此NV做过多次尝试,想去定义AI factory,比如去年的GH200 256小集群,但不是很成功(除了对经验不足的某些主权AI、企业客户有吸引力),CSP客户还是选择HGX自己攒AI Cloud,比如Meta最近直接拎出来的两套网络方案对比。说白了,即便大规模训练NVlink+IB这一套的优势很大,但meta这种需要考虑投资回报、下游需求的多样性(LLM训练推理+推荐系统呢),以及未来模型训练结束后部署推理,即infra复用 ,会更倾向于AI Cloud投资。而OpenAI这种追求最强模型的,AI factory是必然选择。但这次NVL72,就是NV试图在二者中间找一个平衡,成本降低、耦合度提升、支持白盒(除了L1可能必选9个NVS tray)。
NVL72只是将NVLink做了紧耦合,大幅降低了scale-up的成本。那自然会想,Scale-out怎么办,IB相比UEC超以太还是贵啊。答案可能是Dragonfly。
2. Dragonfly + OCS
最早是Y博士在看Groq的时候就跟我说Dragonfly是其最大亮点,包括这次研究GB200的过程中Y博士也提出了Dragonfly应用的可能性。非常前瞻了。之后是LZQ兄弟也问到了NV的专家,认为Dragonfly是未来组网的大概率选择。因为随着computing负载越来越大,上行带宽还会不断double,IB的层数不得不增加,4层IB网络意味着什么相信光模块专业户们最懂了(嘴都要笑裂了),因此不可能4层网络,怎么办?Dragonfly。

这个2008年就被提出的架构,特点是网络直径小、成本低,早期用于HPC集群。(今天有另一位技术大佬告诉我,这次的NVL72也很像当年IBM的HPC大型机,甚至这种紧耦合网络结构也越来越像,看来科技行业真是个大循环...) 其特点是超节点通过高带宽链路直接相互连接,相比传统的leaf-spine拓扑大幅减少了交换机数量(5跳到3跳,单节点网络成本从160美金降到80美金)。但其缺点是网络拓展需要重新布线,太复杂。然而在几个月前的Hot chip上,英伟达首席科学家Bill Dally提出了一种创新,Dragonfly+OCS:组和组之间可以直接连接到光电路交换机OCS,通过布线自动化,有效解决了扩展问题。OCS还可以根据不同用户的需求,分配不同数量的资源,从而优化资源利用率。在计算节点出现故障的情况下,OCS可以连接冗余节点进行替换,迅速恢复系统的正常运行,避免服务中断,提高系统的可靠性。
3. 光/电/CPO
演讲中Bill Dally放出了CPO DWDM互联GPU的3D图:
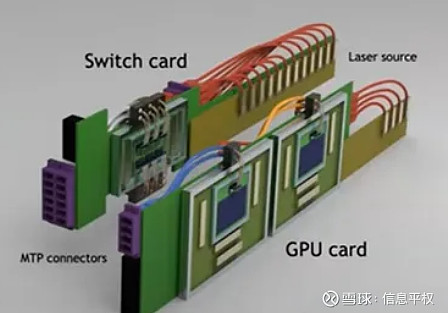

其中技术就来自Ayar labs。但这和博通的硅光拉远到交换机ASIC完全不同,这是直接在GPU附近电IO替换为光IO。Billy Dally认为如果这项技术取得成功,其互联密度甚至会超过电缆,而成本接近电缆,功耗甚至低于电缆,而互联距离可以与AOC光缆相当(这就变态了....)不过,还有一个对模型训练更重要的,可靠性。一般来说,电互联的可靠性要高于光互连,而上周博通那个发布上也提到了ASIC CPO可靠性其实高于复杂光路。但据我所知,Ayar labs的可靠性问题要比目前博通的CPO难得多得多得多....只挑一个最简答的逻辑,一个坏了是废掉一颗几千美金的交换机ASIC,一个坏了是废掉一颗几万美金的 GPU....要求能一样吗。因此个人判断这项技术的应用还要等挺久,至少要在交换机CPO之后。
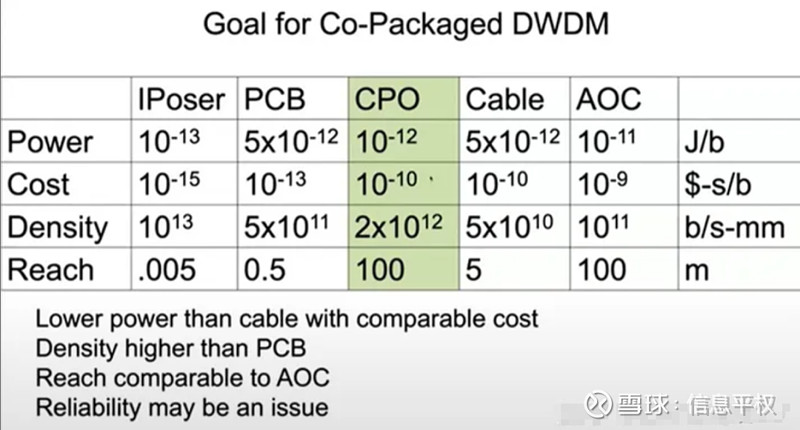
将以上点练成线,一个图谱似乎越来越清晰,距离从近到远,依次为CPO+NVLink紧耦合(NVL72超节点) + OCS+Dragonfly,分别解决了片间带宽、超节点rack内带宽、节点间网络带宽的问题,这可能就是面向未来的系统架构雏形。欢迎探讨。
网络写得要吐了,下次写软件....
(完)
以上相关话题欢迎星球内讨论,呼声很高的安费诺报告也已上传....