(从睁眼开始手机一直炸到现在,星球发了又删删了又发,确实感受到现在每一句话都要好好说,谨慎再谨慎)
先说GTC整体的感觉,相信纯芯片发烧友肯定失望了,因为Blackwell架构本身乏善可陈,如iPhone尺寸升级一般,告诉你这次B100的特点是“size更大”!几个型号的区别也没细说,除了GB200经过之前公众号文章普及相信大家都了解了。B200和B100又是什么区别?有张图似乎说的很清楚:
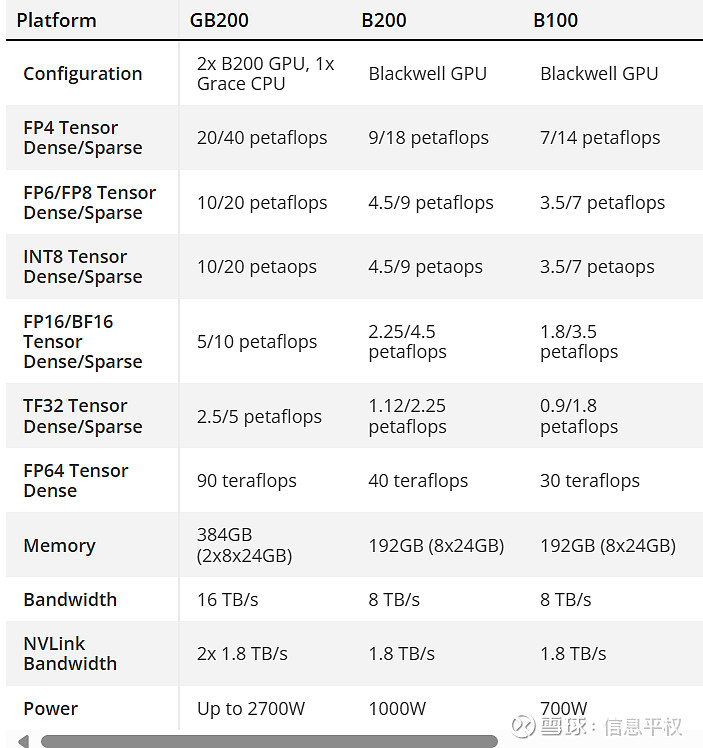
有位大哥总结很到位——“B200青春版”... 个人认为,B100是为了价格而定的产品,从性价比的角度,就是为了能打出一款3万美金超高性价比的单卡。通过降频让功耗维持和H100一样的700W,保证供应链可以无缝对接。其他设置如果不变,那你自然可以理解B100的毛利率肯定要低一些。转述下Yvonne昨晚发我的,很有道理:“GPU卡本身毛利率下来是更健康的状态 ,量可以超预期,把GPU的base做大,然后通过配套的网络设备、软件服务赚回来。”
我在星球一早也发了:

那么回到另一个最关键的问题,光模块到底利好还是利空。之前我也想简单了,认为GB200会和GH200的网络架构基本一致,今天出来发现还真不是....老黄太狠了。现在的NVL72单机柜(两个36卡的机柜用铜LACC互联)算力等效之前GH200的256,之前GH200 256方案用了两层nvswitch(96L1和36L2,实现了256卡互联),因此最后光模块1:9。256集群再往上scale out才需要IB和额外的光模块比例。但现在的GB200 NVL72,用9个NVSwitch 一层网络,就给你搞定了内部互联,只看NVL 72内部互联全是铜。当然了,机柜再向上scale out肯定还是光了。但问题也来了:1) 毕竟还是grace hopper c2c,网络负载肯定还是远大于pcie,只要继续scale-out,机柜对外互联,负载还是很大,光用量不会少的;2)但如果还是1EFlops算力内的需求,过去需要一个256卡小集群才能满足的需求,现在只需要一个NVL 72 机柜....意味着集群的需求变成了单机柜的需求,换句话说不用光了…3) 如果是csp大厂在GB200 NVL72基础上继续搞集群、继续扩展,那在机柜上面这层直接上IB,这一层的收敛比是多少,决定了光模块的用量和1.6T的渗透速度。
因此对于光模块来说问题变成了,需求(无论训练还是推理)能不能带动集群。毕竟过去H100 2560卡的集群,理论上需要3万多个光模块;而现在实现同等算力只需要最多500多张GB200(很可能更少...尤其是推理上),或者说8个NVL72机柜,IB这一层如果是1:3,那么需要1500个光模块....当然这里面会有到1.6T的价值量的提升.....
看到这儿一定很多人要骂了,说好的光进铜退呢!其实...这事儿老黄一直以来反复在说,符合NV一直以来的理念,铜还是光,工具罢了。NV要做的,就是不断把数据中心压缩为rack,再把rack压缩成芯片。当需求拉动芯片scale成了rack,又scale成了数据中心,那再来一遍,循环往复...不断地压缩、压缩、压缩...才实现了所谓的“10年100万倍算力提升”。这件事意味着什么:
1)千万别拿他当芯片,他一直以来都是一个系统,所有的优化,都是为了系统最优。
2)铜还是光,都是服务于系统。当我可以把集群压缩成机柜rack,过去由于太远而无法用铜实现的第二层NVSwitch,自然可以从光变成铜,距离缩短,成本降低(1/6)
3)硅可能是人类发现的最容易scale的东西,就算摩尔定律不进步,通过扩大晶体管就可以实现的事情,肯定比你扩大一个巨大IDC要简单的多...
4)如GB200,从系统角度看,就算blackwell本身架构没有进步,但从网络、内存、软件、带宽等各个小环节分别提升一倍,整个系统可以优化几十倍...因此可以升级的先升级,不能升级的先复用。非常清晰。
4)结合以上角度,思考NV想做的ASIC,似乎有了眉目。一个系统、复用能复用的、同时加入定制化需求(老黄自己说的加密计算等等)。所以这种ASIC怎么可能是AVGO/MRVL等做的那种DSA....
因此也不用线性外推铜进光退、光进铜退,都是在不同阶段服务于这个系统罢了。比如NVlink有一天到了电传输的IO瓶颈,也一定会上光。当board与board之间的互联速度跑的快了点,导致rack内那些铜缆也变得极其笨重,无法配置,也自然会再回到光。这都是在需求和供给你追我赶过程中的切面。
最后提一句,老黄专门提了,目前GB200最大的系统可以用来训练26万参数的模型,你说这指的是谁呢?准备迎接一个巨大的MOE...
BTW,听Daniel总说今晚还有一个CFO的会,到时听听大家会关心什么,会及时给大家更新。
(完)
今天各位嘉宾火力全开了,星球讨论很多,欢迎加入讨论。