
苹果的机器学习科学家Awni Hannun(吴恩达学生),宣布Apple刚刚上线了专门为M系列芯片定制的神经网络框架 MLX。Jim Fan评论“这可能是苹果迄今为止在开源人工智能方面的最大举措: MLX,一个为苹果芯片优化的PyTorch式的神经网络框架”。MLX设计了一系列深度学习用户易于上手的API,包含一些经典案例,比如 Llama、LoRa、Stable Diffusion 和 Whisper,让用户不需要再使用过去的CPU框架。
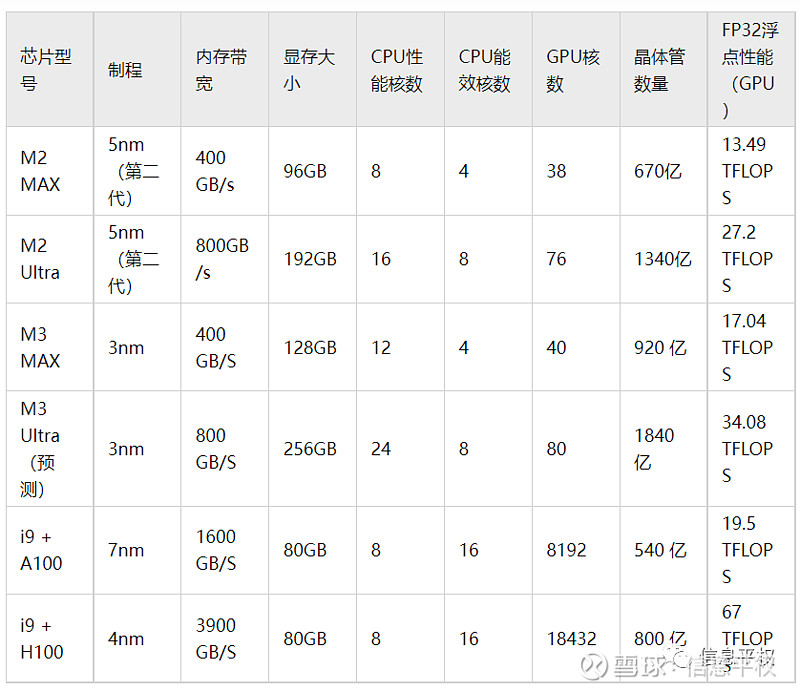
要知道,M系列芯片的内存是比GPU大的。其最大技术卖点就是“统一内存”,之前有人对比过M系列和A100,M2 Ultra的内存有192GB,统一内存意味着内存可以被显卡直接当显存用,假设80%作为显存使用,那也有153GB显存,什么概念?相当于两张A100或H100的HBM。当然劣势是带宽,毕竟HBM更紧密的堆叠使IO速度更快,达到1.6-3.9TB/s,而M系列显存是800G/s(和4090差不多)。但从显存规格上,已经可以本地运行800亿参数模型(优化后的gpt 3.5才200亿参数)。明年要发布的M3 ultra从面积上看内存可能是256G。
这就可以了?显然不行。除了内存和处理器之间的带宽速度是短板,不支持CUDA才是M系列跑AI的最大硬伤(英伟达和苹果早年闹掰的结果),导致很多模型只是理论上可以在M上跑,但实际效果很差。而对于这次MLX的功能描述如下:

也就是说苹果不仅仅希望用M系列做推理和部署,还要“Transformer LM training”。对,没有Large,毕竟没有卡间互联大模型训练那是绝对不可能滴。但单卡跑跑小模型训练、fine-tune、LoRA、推理,问题似乎不大。具体效果可能要看更多评测了,但过去任何兼容CUDA(Rocm)、越过CUDA(Pytorch 2.0)的努力都不太成功,作为同样具有“全栈系统定义能力”的苹果,不知道是否有成功可能。
但无论如何,对端侧AI都是一个好消息。高通、联发科在移动端的计算架构体系设计能力,和苹果还是差一大截。尤其是苹果拥有从芯片到OS到应用的全栈能力,还有siri这种天然存在的场景,苹果理论上会比任何安卓厂商,更有能力推出一款AI Agent Killer APP,拭目以待。