速途网4月28日消息(报道:李楠)今日,通义千问开源1100亿参数模型Qwen1.5-110B,成为全系列首个千亿级参数开源模型,并在多项基准测评中都创下可与Llama3-70B媲美的成绩。目前Qwen1.5系列已累计开源10款大模型,通义千问开源模型下载量超过700万。
通义千问1100亿参数模型延续了Qwen1.5系列的Transformer解码器架构,采用了分组查询注意力方法(GQA),使得模型在推理时更加高效。110B模型支持32K上下文长度,具备优秀的多语言能力,支持中、英、法、德、西、俄、日、韩、越、阿拉伯等多种语言。
Qwen1.5-110B在MMLU、TheoremQA、GPQA等多个基准测评中展现出卓越性能,基础能力可与Meta刚刚发布的Llama-3-70B模型相媲美,相比通义千问720亿参数开源模型也有明显提升。研发团队指出,Qwen1.5-110B的预训练方法与同系列其他模型并无明显差异,性能提升主要来自于参数规模的扩增。
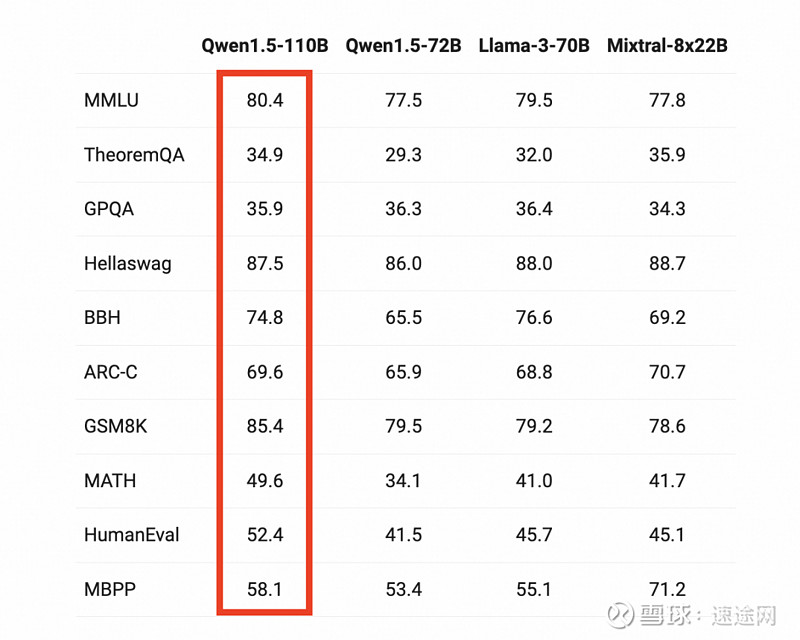
研发团队还在MT-Bench和AlpacaEval 2.0两个测评集上对1100亿参数模型的Chat版本作了评估,通义千问110B比通义千问72B的效果有显著提升。

今年2月初,通义千问团队推出最新开源模型系列Qwen1.5,随后在不到3个月的时间连续开出8款大语言模型,模型参数规模涵盖5亿、18亿、40亿、70亿、140亿、320亿、720亿、1100亿;Qwen1.5系列还推出了一款基于LLM开发的代码模型CodeQwen1.5-7B和一款混合专家模型Qwen1.5-MoE-A2.7B,均在开源社区收获热烈反响。
开发者可在魔搭社区ModelScope和HuggingFace等开源社区下载使用Qwen1.5-110B。据悉,目前通义千问开源模型下载量超过700万,是最受开发者欢迎的开源大模型之一。
通义大模型的落地应用也开启了加速度,近期,新东方、同程旅行、长安汽车、西部机场集团、亲宝宝等多家企业宣布接入通义大模型。通义大模型开始“上天入地”支持千行百业,比如,中国科学院国家天文台人工智能组基于通义千问开源模型开发了新一代天文大模型“星语3.0”,大模型首次应用于天文观测领域;陕煤建新煤矿等十余座矿山推出由通义大模型支持的新型矿山重大风险识别处置系统,这是大模型在矿山场景的首次规模化落地。