
【重点提示:本文仅为线性推演假设下的测算,未有考虑任何风险因素,未有做任何风险补偿测算。笔者的内容和依据可能完全不准,错误离谱,仅作为YY之用。即便猜对了,中间也可能历经极大的波动。所以务必谨慎!!
股市有风险,投资需谨慎!股市有风险,投资需谨慎!】
比尔·盖茨: “我们总是高估未来两年的变化,低估未来 10 年的变革。”
如果当年克林顿刚刚推出信息高速公路的时候,一个人和你说,亚马逊这样的公司会在未来涨到几千亿、一万亿美金市值,你会认为他疯了。
如果当年苹果3刚刚推出的时候,手机电池不给力,苹果4信号出问题,一个人和你说,苹果这样的公司会在未来涨到3万亿美金市值,你同样会认为他疯了。
今天笔者,决定做一个疯子——
对中际旭创(带着英伟达)基于三种假设去推演下它未来乐观(以及最乐观)的市值空间。
先说推演的结果,相对比较乐观的市值在6000亿左右,极为乐观为1.2万亿市值。
【可能推演结果不对,但是众多球友勿喷,先看完文章,重要的是推演的思路逻辑】
——————————————
一,基于底层逻辑的推演——算力需求暴增+摩尔定律已死+算力卡需求大增
1.1 算力百万倍的增长——Scaling law法则
2020年1月23日OPENAI的论文里面的核心观点是这样的:对于基于transformer的语言模型,假设模型的参数量为N,数据集tokens个数为D(token数),那么,模型的计算量【C约等于 6N*D】 (划重点)
模型的计算量C一定后,模型的性能即精度就基本确定。它的决策变量只有N和D,跟模型的具体结构诸如层数、 深度、 attention头个数(宽度)基本无关。相关性非常小,性能(即test loss)在2%的区间内。
Openai发现这个规律后,通过构建一个巨大的海量数据集,然后简单增加gpt模型的深度,就做出了惊人的具有涌现能力的大语言模型。
我们看下OpenAI每一代GTP的参数
表1、
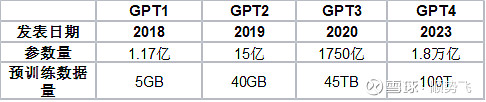
通过上面表格初步测算(毛估估,不一定精准),GPT4的算力需求是GPT3的20倍左右。
按照过往,OpenAI对GPT大模型2年迭代一个版本的测算,未来10年训练侧对算力需求的扩张很大可能在32万倍以上
(新闻显示:人工智能领域的算力需求约每3.5个月翻一倍,测算下来每年是10倍增长,10年则是100亿倍的增长)
推理侧的算力推演,英伟达GB200 NVL72 是DGX H100推理性能的30倍,训练性能是H100的4倍,大概可以得出训练算力需求是推理算力需求的7.5倍。
目前推理侧大概占算力需求的40%,B端的行业渗透率为4%,未来达到40-80%渗透率,存在10-20倍的增长。则简单推算,算力推理侧需求大概可以折算到3倍训练侧的算力需求。(未考虑toC端的机器人等应用)。
阶段结论:整体的算力需求增长预计在100万倍以上。
(20240509更新
据OpenAI在2020年发表的论文《ScalingLawsforNeuralLanguageModels》,大模型在完成训练之后,模型本身已经固定,参数配置完成之后即可进行推理应用。而推理过程实质上就是对大模型参数的再次遍历,通过输入文本编码后的向量,经过注意力机制的计算,输出结果并转化为文字。
这一过程中,模型的参数量取决于模型层数、前馈层的层数、注意力机制层的头数(head)等。推理过程所需要的算力可以由公式C≈2NBS来刻画。由于解码模块在进行推理的过程中,主要执行前向传播,主要计算量体现在文本编码、注意力机制计算、文本解码等环节。根据OpenAI给出的计算公式,每输入一个Token,并经历这样一个计算过程,所需要的计算量=2N+2,其中公式后半部分主要反映上下文窗口大小,由于这部分在总计算量中的占比较小,所需字节常以K级别表示,因此在计算中往往予以忽略。
最终,我们得到大模型推理的计算需求为单次计算量与Token数量的乘积,即C≈2NBS。
通过底层算力和性能提升对比测算,可以发现英伟达最新的BackWell系统为了推理做了更大的优化。
)
算力百万倍的增长——海外大佬观点对照
第一位:OpenAI山姆·奥特曼
2024年1月12日,OpenAI的CEO山姆·奥特曼作为嘉宾参与了比尔·盖茨的播客节目《为我解惑》(Unconfuse Me)。
提及AI对人类社会的影响,奥特曼直言,“AI将引发人类历史上‘最快’的一次技术革命,而人类可能还完全没有准备好如何应对,也对AI技术的发展速度没有足够的预期。”
盖茨也认同奥特曼的观点,他认为,“AI将迫使我们人类以前所未有的速度适应这次变革。”
人类如何适应AI的快速发展,又如何限制AI带来的负面影响,这是目前各国政府及整个科技行业都在努力解决的问题。奥特曼一直强调AI监管的必要性,盖茨在对话中直接了当地问他,“你到底想要做什么?”
奥特曼回应说:“我认为我们开始逐渐弄明白,科技将迅速朝着具有十万或百万倍GPT-4计算能力的系统发展。如果我们是正确的,这项技术将影响到社会、地缘政治力量的平衡等方方面面。”
第二位:英伟达黄仁勋
2024年3月初,NVIDIA英伟达CEO黄仁勋回到了他的母校美国斯坦福大学,参加了斯坦福商学院SIEPR经济峰会以及View From The Top 系列活动。活动访谈上,黄仁勋表示,【在未来的10年里,英伟达将会把深度学习的计算能力再提高100万倍,以满足AI计算机不断训练、推理、学习、应用的需求,并持续改进。】
我们每10年都将算力提高一百万倍,而需求却增长一万亿倍,这两者必须相互抵消。(非常重要,划重点)
然后还有技术扩散等等,这只是时间问题,但这并不改变这样一个事实:总有一天,世界上所有的计算机都将100%地改变,每一个数据中心,价值数万亿美元的基础设施,将完全改变,然后在这之上还会建造新的基础设施。
第三位:月之暗面(Kimi)杨植麟
月之暗面创始人杨植麟的部分观点
最终直接训练一个万亿的 dense model 肯定效果会比一个只有千亿参数的模型要好。
我们经常会提起“摩尔定律”,摩尔定律最早指的是,每N年晶体管数量可能会翻一倍。现在,AI时代也有不同的摩尔定律。可能每N个月,模型的参数数量翻一倍,那N个月后模型算力也要翻一倍,每N个月你的能实现可用的这个场景数量,它应该翻一倍。
我们认为其实现在最关键的其实应该是这个定律,这是通往AGI非常必要的路。它不应该是一个线性的增长,它应该是一个指数的增长。
在推理层,Transformer模型中自注意力机制(Self Attention)的计算量会随着上下文长度的增加呈平方级增长,比如上下文增加32倍时,计算量实际会增长1000倍。同时,超长上下文也将带来显存与带宽压力。
26 年的时候也许模型用于推理的计算量会远远大于训练本身,可能花 10 倍的成本去推理,推理完之后花一倍的成本来训练,到时候推理就是训练。
通过逻辑推演、大模型系统参数对比测算和大佬观点对照:算力的需求在未来十年可以确认大概率在百万倍的量级增幅。(划重点)
1.2 摩尔定律已死
1965年,时任仙童半导体公司研究开发实验室主任的戈登·摩尔为《电子学》杂志写了一篇观察评论报告,在报告中摩尔提到,工程师可以不断缩小晶体管的体积,芯片中的晶体管和电阻器的数量每18个月左右会翻番,半导体的性能与容量将以指数级增长,并且这种增长趋势将继续延续下去。他的这种预测,被称为“摩尔定律”。1975年,摩尔修正摩尔定律,提出每隔24个月晶体管的数量将翻番。
在最初的40年里,晶体管数量的增长得益于制程工艺的创新,与摩尔定律一直保持着“默契”。 以CPU为例 ,从早年的180纳米到后来的130纳米再到90、65、45、32、28 纳米。
但是,任何以指数增加的物理量都预示着灾难。要知道,这时就接近某种极限了。——这个极限就是物理学本身的极限
我们知道,nm是一个长度单位。但这个长度是多少呢?以芯片中的硅原子举例,其直径是0.117nm,3nm差不多是25个硅原子首尾相连的长度。由于原子在常温下也会做布朗运动,也就是普通的热运动,虽然这种布朗运动是不会摆脱原子之间的范德瓦尔力的,也就是原子之间的相互作用力,但我们也能从这一点上推判处,3nm的尺度内硅原子的稳定性,这就像宽度为25个不固定的小球的线条在铺设电路。我们知道温度越高原子的布朗运动越剧烈,25个硅原子宽度的电路,必然随着温度的升高,电路的稳定性越来越差。
在微观体系下,电子会发生量子的隧穿效应,不能很准地表示“0”和“1”,也就是通常说的“摩尔定律碰到天花板”的原因。
目前技术下
3NM可以实现,2NM或许可以努力,但是1NM目前看,基本已经是摩尔定律在物理学上的终结。
摩尔定律已死——海外大佬观点对照
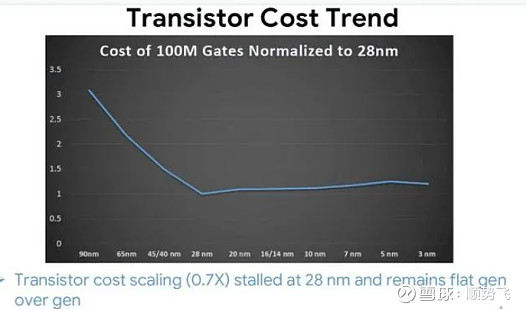
2014年,三维半导体集成公司MonolithIC 3D的首席执行官Zvi Or-Bach提交了一份分析报告,显示每晶体管成本在28 纳米时已停止下降。
同年,台积电创始人张忠谋于先生在公开场合表示,摩尔定律正在苟延残喘,预计还有5-6年寿命。而在2017年时,他认为摩尔定律现在更多反映经济学定理,即单位晶体管的价格会每两年减少1半,但在2025年就很难达到。
2019年,黄仁勋在CES 2019上说,长期以来一直认为的 " 计算机处理能力将每两年翻一番 " 的摩尔定律,已经达到了它的发展极限。
2023年,谷歌的Milind Shah在 IEDM 2023 的短期课程(SC1.6)中验证了出,自台积电 2012 年量产28纳米平面工艺技术以来,1 亿个栅极(gate)单位晶体管成本实际上有所增加,并没有变得便宜。
1.3 更多的更多的算力芯片
算力需求的大幅扩张,芯片制程接近物理极限,单位面积芯片下性能难以大幅提升——这意味着,以目前技术路径看,只能通过使用更多的算力芯片来达成未来的算力需求
(这里继续划重点,而由于GPU和光模块存在比例关系,所以看官可以耐心接着看下去)
这里我们看今年1月海外媒体的报道:
2024年1月,媒体OpenAI CEO Sam Altman正在与台积电和中东投资者进行谈判,以启动一家新的芯片合资企业,旨在减少OpenAI对英伟达的依赖,并满足其日益增长的处理能力需求。
此后奥特曼回应媒体曝光寻求7万亿美金的支持
奥特曼:事实的核心是我们认为世界将需要更多的人工智能算力。(划重点)这不仅仅包括芯片,还包括放置服务器的数据中心。投建一座数据中心不仅需要芯片,还需要许多的设备和材料。这种规模将需要在全球对许多事物进行投资,而不仅仅是我们许多人考虑的芯片。
基础设施的总成本将会很高。多高?我认为我们还不知道,但它将是7万亿。(划重点)我听说过关于这个数据的报道。虽然有些人不喜欢听这些,但我认为这对全球都有巨大的好处。这是我们想看看是否有办法帮助解决的事情。
许多企业都需要人工智能服务。随着模型变得越来越强大,因为它们能够处理更多的事情,我们希望确保它变得更容易获得、更丰富、对每个人来说都负担得起,而不是走到另一个方向,变得异常昂贵、只有最富有的人才能负担得起。这样真的很糟糕。
【合理推演:奥特曼为何要自己寻求7万亿美金的支持,为何与台积电洽谈AI芯片投资及生产计划。那大概率是看到了自己会对算力芯片有强大的需求,而这个需求需要多少的量,我们可以通过一些简单的倍数去做测算】
笔者在这里(表2)根据GTP历次版本的参数和英伟达不同版本的算力提升根据时间进行了测算。
依据:
Scaling law法则C=6ND——根据GTP的已经公开的参数,结合 Sam Altman的公开采访
(OpenAI 首席执行官 Sam Altman 接受公开采访 表示,GTP-5 在 2024 年底至 2025 年发布,它的参数量为 GTP-3 的 100 倍,需要的计 算量为 GTP-3 的 200-400 倍)
训练算力增长需求是每个版本增长20倍左右的算力需求。
同时,英伟达GPU服务器的算力提升——芯片对于训练侧每2年一代提升4倍性能,可以近似于每年2倍提升,推理侧每2年一代提升7到8倍。(根据目前产品迭代情况测算,同时,黄仁勋在2023GTC大会上表示过去8年算力芯片能力增长1000倍,推算得到大概每年2.5倍的性能增长,与笔者根据新闻整理的2倍性能增长基本一致)
那么在行业没有任何发展阻碍的情况下
(如数据集不够、如电力问题、如可能产生情感伦理问题,如超越人类问题)
阶段结论:如果英伟达的单位芯片性能没有超越过往的提升速率,那么为了满足算力需求增长的芯片数量几乎是需要达到每年翻倍。
(2024年5月1日更新,借用公众号光学小豆芽的图片和观点。作为和我这里的观点验证或者对照,文章部分截取如下:
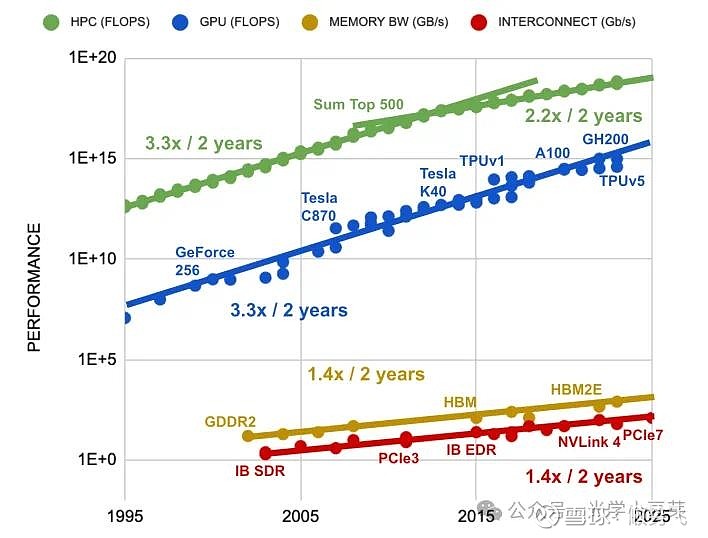
计算芯片的性能大约每两年提高3.3倍,HBM芯片的带宽每两年提高1.4倍,而互联带宽(PCIe,IB,NVLink等)每两年提高1.4倍,如下图所示。可以看出计算性能与互联带宽的发展速度存在较大的差异。3.3/1.4=2.4,需要将互联的数目增加2.4倍,才能弥补两者间的发展速度差异。
与此同时,在AIGC的驱动下,AI算力的需求呈指数级增长,每2-3个月翻一番,两年内增加了100倍多,如下图所示。
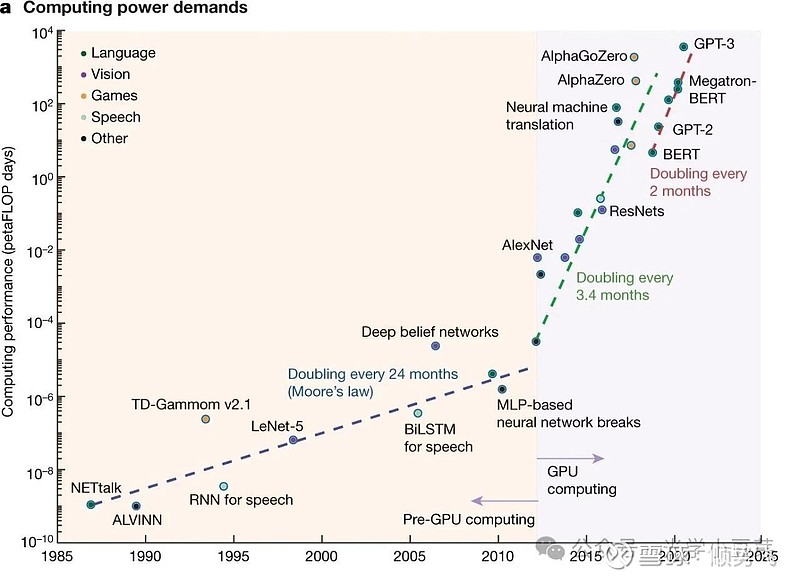
简单计算下,100倍的算力增长需求,计算芯片的性能提升3.3倍,因此计算芯片的数目需要增加30倍多。再考虑到先前的2.4倍差异,每两年的互联总数需要提升70多倍。如何解决这一问题?一方面增加光模块的带宽。它的发展趋势是每四年带宽提升一倍,包括提升单通道速率、增加通道数、使用更多波长等方法。另一方面,增加光模块的总数目,提升IO口的带宽密度,在有限空间内可以布置更多的接口。)
更多的更多的算力芯片——海外大厂观点对照
台积电:
魏哲家强调,几乎所有领域的AI创新者都在与台积电合作以解决算力需求,预计今年AI服务器处理器(指训练和推理所用的GPU、AI加速器和CPU)相关营收将增长一倍以上,占到全年营收的11~13%。同时他预测,未来五年AI服务器处理器将以50%的年复合增速增长,到2028年占台积电整体营收比例将超过20%。现阶段大多数AI加速器采用台积电4/5nm制程,且考虑到先进制程带来的节能表现,客户对3nm乃至2nm的采用意愿相当高,越来越多的客户希望能够使用2nm制程。为此2年之后,台积电很有可能就将从3纳米走向2纳米。”
广达:
代工大厂广大资深副总经理暨云达科技总经理杨麒令于2023年9月13日表示,数据中心与企业客户加速采用人工智能(AI)服务器,但上游零组件缺货,无法完全满足强劲需求,看好AI是未来至少5到10年甚至更长时间的发展趋势。
2024年4月23日,杨麒令证实,搭载当前“最强AI芯片”英伟达GB200的服务器,预计将于9月量产。四大云服务提供商(CSP)客户需求大,预计广达今年的服务器出货量维持两位数增长。目前全球各地持续训练大语言模型,对AI服务器及芯片的需求持续增长。
广达预计,今年AI服务器营收占比将从去年的20%,跃升至超过50%。【今年翻倍】
所以,台积电的50%增速极大概率是靠谱的(甚至超过这一复合增速,继续划重点)。
因此,笔者同样根据台积电对到2028年的复合展望作为依据,在表格2中增加了测算,到2028年左右,英伟达利润可能达到惊人的6000亿美金净利润!
数据可能有一些夸张,我们找到新闻来源对照看一下:
2023年12月7日,美国超威半导体公司(AMD)首席执行官苏姿丰表示,预计到2027年,用于数据中心的人工智能芯片市场的规模将增长到4000亿美元,年化复合增长率高达70%。
英伟达企业运算副总裁曼努维尔·达斯(Manuvir Das)给出了另一组数据显示,预计 AI 所在的潜在市场(TAM)规模将增长至6000亿美元。其中,芯片和系统可分得3000亿美元,生成式AI软件可分得1500亿美元,另外1500亿美元则由英伟达企业软件贡献。
瑞穗(Mizuho)分析师维贾伊-拉克什(Vijay Rakesh)预计,英伟达至少会在2027年之前保持其在人工智能芯片领域的主导地位。拉克什补充说,到2027年,该公司在人工智能服务器市场的份额将达到75%,可以创造约3000亿美元的人工智能特定收入。
以英伟达高管的数据,按照英伟达85%市占率,50%净利率测算,利润规模可以达到2550亿美金水平。和笔者表格里根据台积电对行业50%增速测算下的2026到2027年的利润1800-4000亿量级相符合。
而如果按照每年翻倍的计算推演,10年后的2033年,以2024年市场预测的英伟达550亿美金利润为基础,推演的利润甚至可以达到10万亿美金量级。这个由于还是缺乏产业端的信息,仅就看看。
对了,这里笔者提示一下scaling law 法则的特性,就是在模型架构的阶段,找到了一个预估训练LLM回报的公式,不用拿超大的模型跟数据,用几个月甚至几年的时间慢慢做实验,只要在小模型、小数据下验证、确认公式了,就基本可以确认去设计一个更大型的训练,大幅度减少了实验成本。
其实,这意味着,在小模型阶段就可以预测到大模型未来需要多大的算力。
最新的24年4月25日,OpenAI CEO山姆•奥特曼透露,“GPT-5会比GPT-4更聪明,GPT-6会比GPT-5更聪明,我们还远未到达这个曲线的顶部。”
那各位是不是大概可以 理解为何山姆奥特曼会希望筹集7万亿美金建立芯片制造和数据中心等等了?
【当然这里可能存在笔者计算的问题,如线性推演,或者未有考虑芯片技术的升级,请专业方面的大咖多指正】
表2
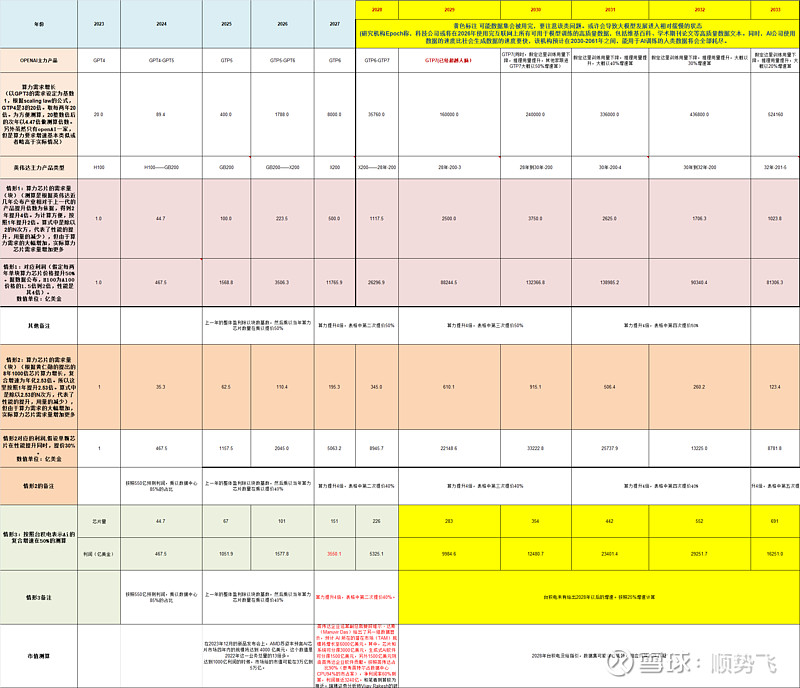
(笔者表格里仅考虑了训练侧的增长,由于推理侧缺乏远期数据支持,尚未考虑。目前根据英伟达黄仁勋的观点,推理侧需求占总算力需求的40%。
2024年5月4日,同时对英伟达的增速根据算力芯片性能提升不同情境,做了三种情形测算。相对可以做参考验证的是台积电50%增速的观点——这个观点所得数据,基本能够和英伟达高管对于未来人工智能芯片市场6000亿美金的规模对照。)
小Tips:
行业通常以测试集上的损失来度量模型性能L。尽管存在提到的三个幂律关系,但为了稍微減小一点损失就付出成倍的模型参数和计算量,这真的是一种划算的策略吗?
实际上,研究者发现,尽管模型的损失只是在稳定下降,但模型在某些下游任务的性能却可能突然出现大幅度的提升。
这种由量变所带来的质变,称为涌现。因此,虽然损失只由l降低到了 0.9l,但这并不等价于“性能”只提升了百分之十。
【所以,笔者预计,即使数据集使用到了尽头,增加参数量、大力出奇迹的继续堆算力,可能还是会继续延续较长一段时间。
(20240429更新:在可见的未来,网路上可见的Data数量可能会不够了,因此研究Data Repeatition就变的很重要,AI2发现repeat 4次都还可以给LM带来有效的improve ,新加坡国立大学跟爱丁堡大学的研究者则提出11个针对data repeatition的insight。——本段摘录自公众号互联网持续学习圈)
2 需要更多的更多的更多的 光模块
前面的表格里,显示了大模型每代训练需求的扩张,需要的算力芯片越多,需要的算力服务器的集群越大。
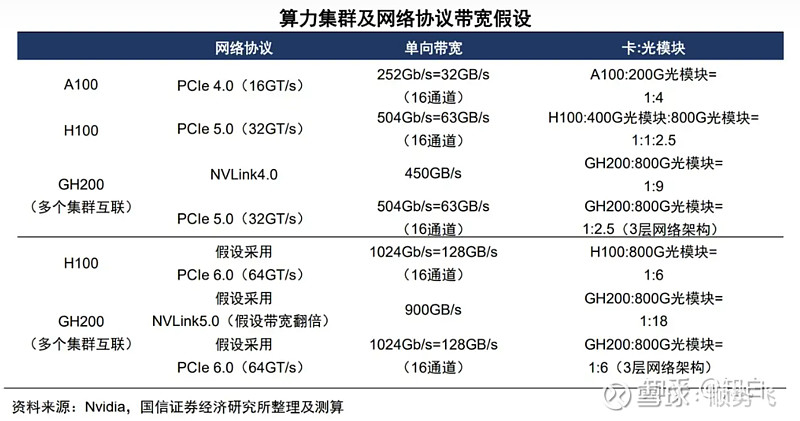
目前大家都可以得到的数据,GPU比光模块的比例大概在1:2到1:2.5。
但是当整个计算集群因为我们此前分析而需要不断的扩大的时候,所需要的光模块在比例上可能进一步增加。(为什么——解释:是否能释放百亿亿级计算和万亿参数 AI 模型的全部潜力取决于服务器集群中每个 GPU 之间能否快速、顺畅的通信。)
笔者这里用一个非常简单的图(手工作图,比较丑,勿喷,仅供理解)
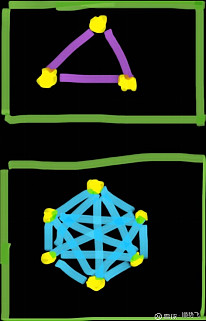
图中的点代表了AI服务器集群,线代表连接集群的光纤和光模块(甚至也有铜缆)等等。
当图上仅有3个点的时候,所需光模块和GPU是1:1的关系,而当服务集群变为6个点时,比例变成了光模块 15 : 6 的GPU。
当集群中的点越多,这个比例会进一步增大。
(20240504更新
基于缩小网络瓶颈考虑,大规模AI集群的网络架构需要满足大带宽、低时延、无损的需求。智算中心网络架构一般采用Fat-Tree(胖树)网络架构,具有无阻塞网络的特点。
同时为避免节点内互联瓶颈,英伟达采用NVLink实现卡间高效互联。对比PCIe,NVLink具有更高带宽优势,成为英伟达显存共享架构的基础,创造了新的GPU到GPU的光连接需求。
对于 AI Factory 通过 NVLINK+infiniband满足几十万张、几百万张GPU互联的需求。
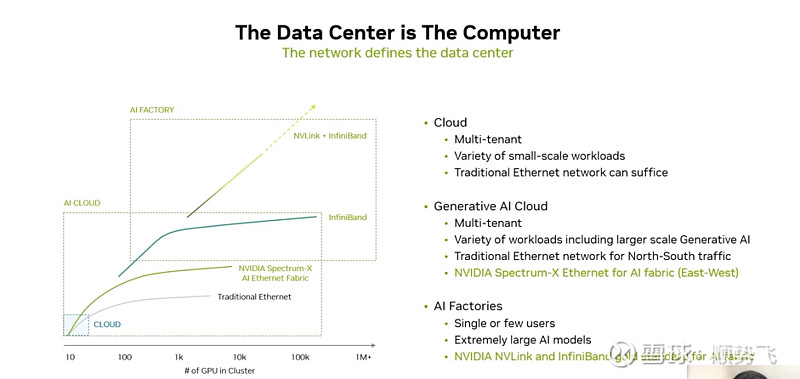
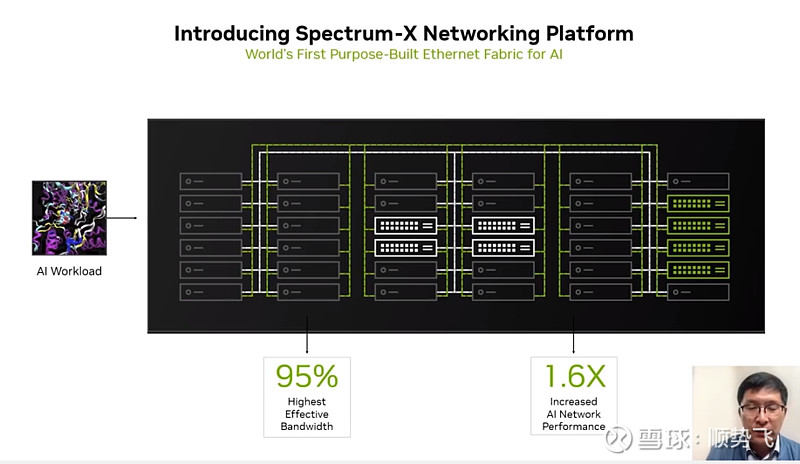
针对以太网,推出Spectrum-X平台,进行优化(基于以太网的)
[该平台的信息解释——
NVIDIA® Spectrum™-X 网络平台是第一个专为提高Ethernet-based AI云的性能和效率而设计的以太网平台。这项突破性技术在类似LLM的大规模AI工作负载中,提升了1.7倍AI性能、能效,以及保证在多租户环境中的一致、可预测性。Spectrum-X基于Spectrum-4以太网交换机与NVIDIA BlueField®-3 DPU网卡构建,针对AI工作负载进行了端到端优化。
NVIDIA 网络高级副总裁 Gilad Shainer 表示:“生成 A1等变革性技术正在迫使每个企业突破数据中心性能的界限,以追求竞争优势。 “NVIDIA Spectrum-X是一种新型以太网网络,它为有可能改变整个行业的下一代 A| 工作负载消除了障碍。
NVIDIA Spectrum-X网络平台用途广泛,可用于各种人工智能应用。 它使用完全基于标准的以太网,并可与基于以太网的堆栈互操作 该平台从 Spectrum-4 开始,这是世界上第一款专为 Ai网络构建的 51Tb秒以太网交换机。
高级 ROCE 扩展跨 Spectrum-4交换机BlueField-3 DPU 和 NVIDIA LinkX 光学器件协同工作,以创建针对 A 云优化的端到端 400GbE 网络。
NVIDIA Spectrum-X通过性能隔离增强多租户,以确保租户的 AI工作负载以最佳和一致的方式运行。它还提供更好的 AI 性能可见性因为它可以识别性能瓶颈,并且具有完全自动化的结构验证功能。
]
大规模、高带宽的网络传输,传统以太网可能网络阻塞,很难构建无损网络,一旦丢包,触发数据重传机制,使得传输效率大幅下降。
同时,传统以太网很难保证时延,而由于是需要并行计算,一旦某个节点产生时延,会使得其他地方即便时延非常低,意义也不大。所以整个系统是受制于计算最慢的节点。
传统网络内部很难实现网络带宽的均匀分配,而AI需要整个网络没有拥塞,需要把有限的端口进行均匀的划分,把任务进行快速的划分。传统很难达到。

针对传统以太网,构建端到端网络平台上,面向AI的网络,可以达到95%的传输有效带宽,比传统以太网的性能提升60%以上的性能提升。


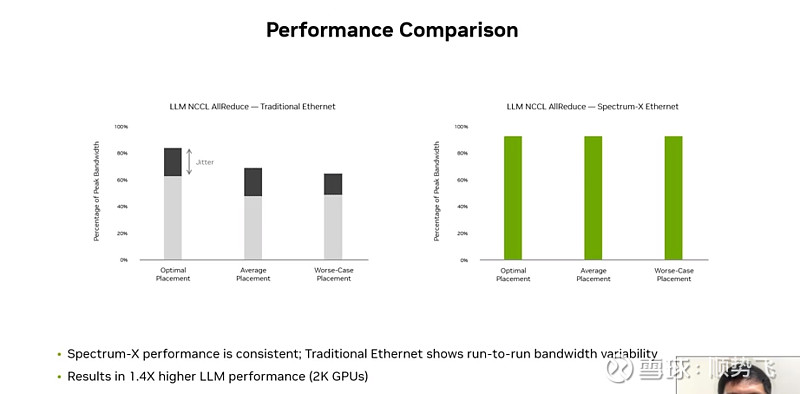
上图,针对2000个GPU,使用Spectrum-x的提升了40%的性能。
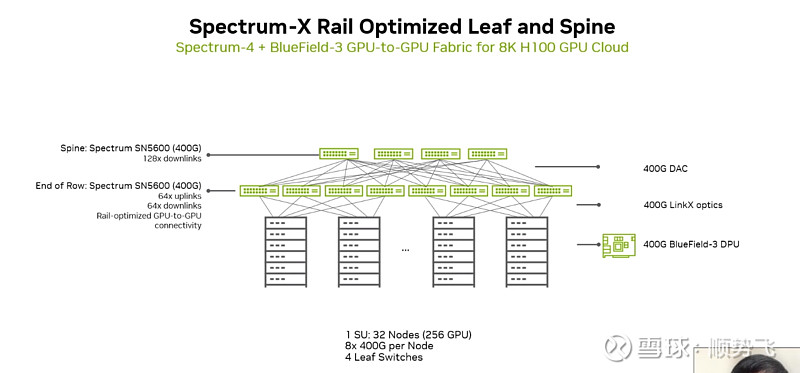
上图,2层以太网交换机,搭建出最多可以连接8000张GPU的集群。单个交换机支持128个400G的接口。
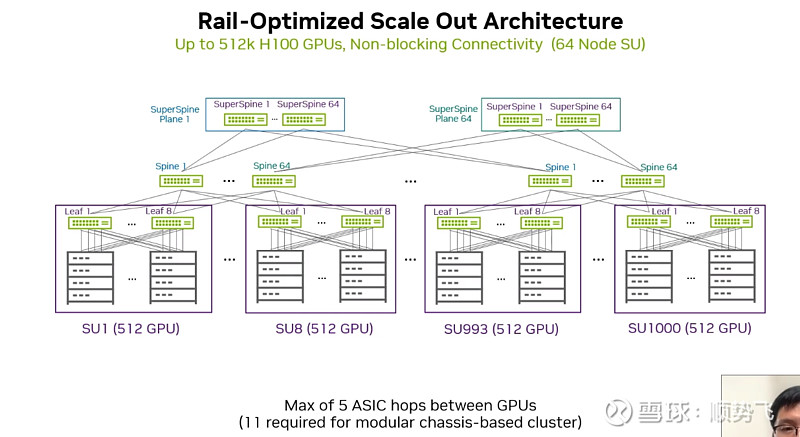
上图 3层以太网络,搭建51万张GPU的集群。(把原来低速的升级到高速的400G)
第四代 NVIDIA NVSwitch™ 可在一个含有 72 个 GPU 的 NVLink 域 (NVL72) 中实现 130TB/s 的 GPU 带宽,并通过 NVIDIA SHARP™ 技术对 FP8 的支持提供 4 倍于原来的带宽效率。使用 NVSwitch 后,NVIDIA NVLink 交换机系统能以惊人的 1.8TB/s 互连速度为多服务器集群提供支持。采用 NVLink 的多服务器集群可以在计算量增加的情况下同步扩展 GPU 通信,因此 NVL72 可支持的 GPU 吞吐量为单个 8-GPU 系统的 9 倍。
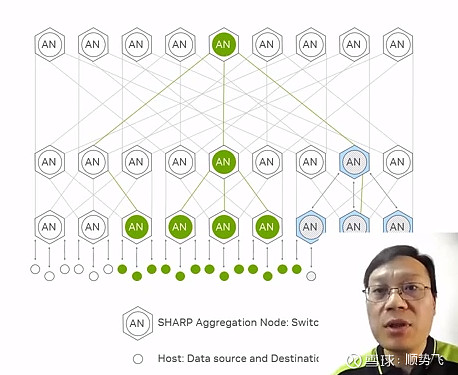
胖树结构:
GPU服务器,也称为system或node,是一个包含8个GPU的集群,其中集群内的GPU通过使用四个定制的NVLink交换机(NVswitches)之间的NVLink进行通信。可以通过GPU网络将多个GPU服务器连接在一起,形成大规模系统。GPU网络是一组以leaf/spine或3级CLOS拓扑结构排列的交换机。它为连接到网络的GPU服务器之间提供任意的连接。
网络中的leaf/spine交换机通常遵循胖树拓扑结构。在胖树拓扑中,随着从节点到leaf和spine的拓扑结构的上升,链路的带宽增加。这是因为每个上行链路需要处理多个下行链路的带宽。
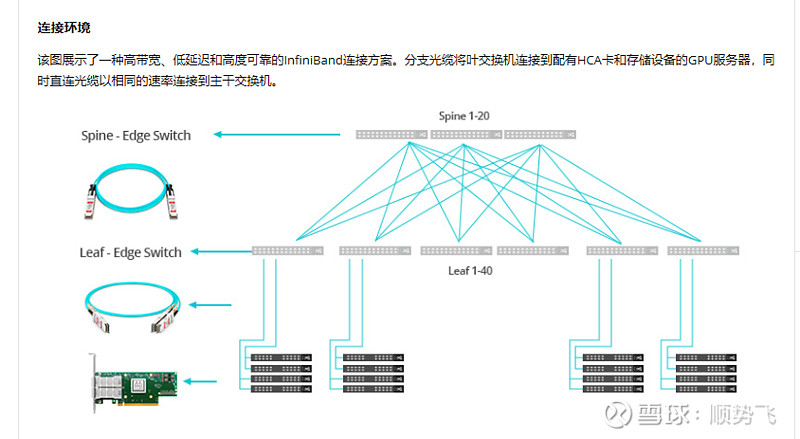
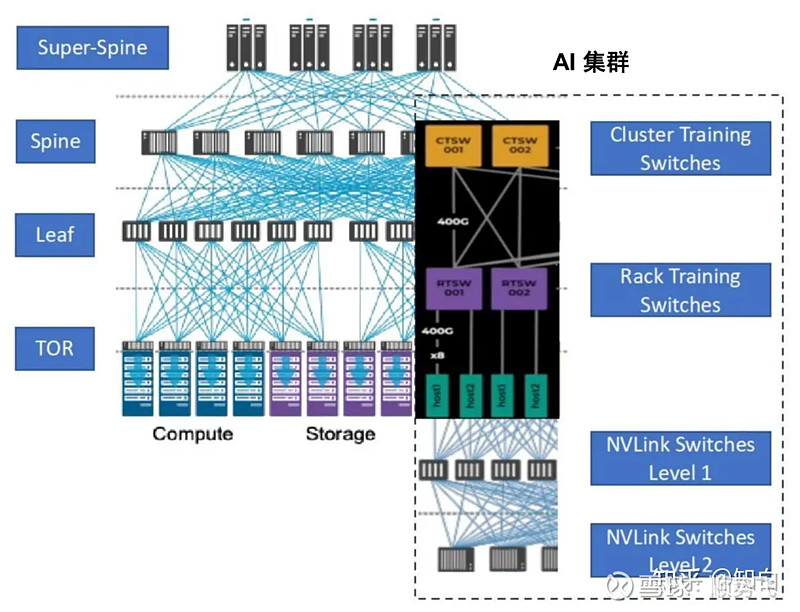
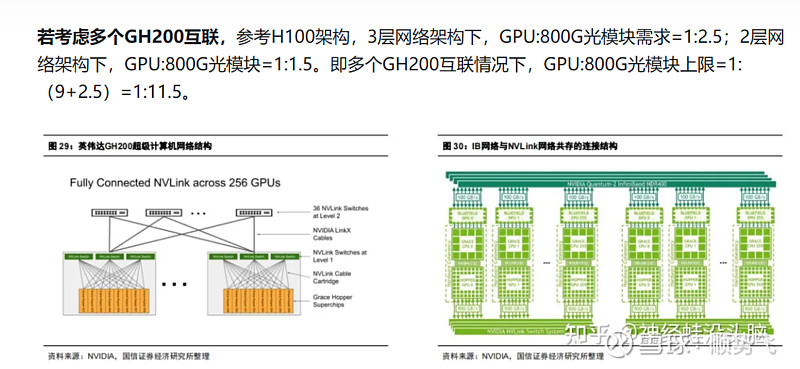
券商测算和分析数据参考:

在 InfiniBand 和以太网之间选择数据中心网络可以显着影响性能、可靠性和成本效益。这两种技术都有各自的优势,并且可以满足不同的网络需求。本文详细比较了数据中心环境中的 InfiniBand 和以太网,讨论了它们对网络带宽、利用率、端口配置和互连选项的影响。
InfiniBand 和以太网对数据中心网络带宽的影响
InfiniBand 和以太网可以显着影响数据中心网络中的可用带宽。 InfiniBand 通常提供比以太网更高的带宽,使其适用于快速数据传输至关重要的高性能计算环境。另一方面,以太网虽然通常提供比 InfiniBand 更低的带宽,但为许多标准数据中心应用提供了足够的性能,并且与各种设备兼容。
比较数据中心环境中 InfiniBand 和以太网的利用率
在比较 InfiniBand 和以太网在数据中心的利用率时,有几个因素会发挥作用。 InfiniBand 的高性能、低延迟和服务质量 (QoS) 功能使其成为需要稳健且可靠的数据传输的高要求应用程序的理想选择。相反,以太网的多功能性、易用性和广泛的兼容性使其成为满足一般数据中心网络需求的实用选择。
)
需要更多的更多的更多的 光模块——对照海外龙头企业公告信息
博通(AVGO)——
2023年建造了一个TPU集群超过1万个节点,需要 2 层高端交换机才能实现。到 2024 年,我们将把这一目标扩大到 3 万多个。而我们的客户现在想要的是如何将集群扩展到10万、数十万、甚至100 万个节点。(划重点)
当客户考虑100万卡集群,需要解决的最大问题就是 RDMA和PCIe。博通正在批量出货 PCIe Gen 5 交换机,到了今年年底就会推出PCIe Gen 6 交换机样品。同时,XPU与XPU之间的高速互联(对标NVLink),博通将与 AMD 合作,构建一个扩展解决方案,由 Broadcom 负责构建交换机,AMD 构建加速器,以开放的方式合作,并将其提交给标准制定机构。
迈威尔科技(MRVL)——

(上图来自@闷得而蜜,此处非常感谢闷大的信息普及)
博通的观点验证了大集群的需求,迈威尔科技验证了在后期大集群所需光模块的用量在和GPU的比例上会呈现更大的弹性。
阶段结论:综上,定性看,光模块的用量的增长趋势,可能会超越市场的预期。(再次划重点)
二,基于当下市场盈利预期和估值区间的对中际旭创的市值乐观推演
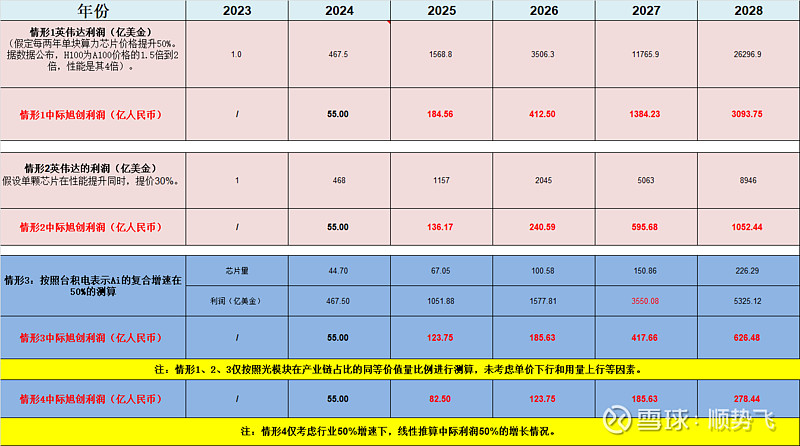
2.1中际利润和英伟达利润的对比
英伟达今年预期550亿美金利润,中际旭创券商普遍预计为55亿(笔者认为可能到60亿)
那简单根据线性关系(大约等同于产业链上的价值链的切分),不计算任何用量弹性,截止2028年的中际利润范围
表3:
【这里仍然可能存在笔者计算的问题。请专业方面的大咖多指正】
2.2 其他信息来源对照
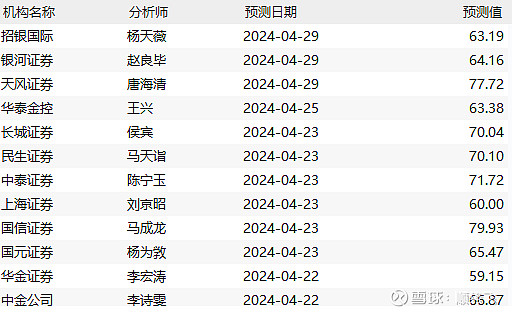
国内券商
2025年,中际旭创的利润普遍预测在67亿左右(平均值)。
研究报告中目前最高81亿(海通国际)。同时,兴业证券最新电话会议显示,上调中际旭创2025年盈利预测,认为明年至少实现80亿到100亿以上水平(产业链较好的情况下)
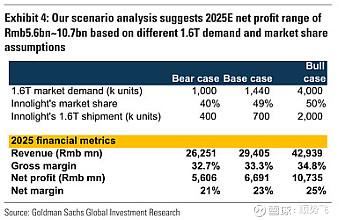
海外券商
高盛报告指出,2025年将是1.6T光模块放量的元年。英伟达的新GPU芯片GB200将需要1.6T光模块配套,预计中际旭创在2025年的1.6T出货量将在40万支到200万支之间,净利润在56亿到107亿人民币之间。中值为81.5亿。
大V @闷得而蜜 :
净利润预期修正:高盛的报告虽然低估了市场空间,但首次给予光模块龙头企业净利润突破100亿的预期。根据产业链追踪和TSMC的产能规划,修正后的中际旭创2025年净利润预期范围为100到150亿人民币。中性预测120亿。
最新雪球发帖市值看到5000亿。
大V @落笔摇五岳:
在4月28号提示,通过分析,台积电CoWoS扩产的节奏,海力士/三星/美光HBM扩产的产能。以及英伟达GB200销量的各种预测。推测全球高速光模块的需求。预估2025年净利润为141亿。
大V 悦然坐看云起:
4月10号发帖表示,根据明年光模块需求测算,中际利润保底100亿,并很有可能冲击120亿。
从多家券商研究报告和大V测算,
对于2025年的利润平均预测为80-120亿;
以相对乐观的60倍市盈率计算,对应市值为4800亿—7200亿市值之间。
以极乐观百倍市盈率计算,对应市值8000至12000亿。
【仅为推算不同市盈率下的市值,市盈率参考最近三年市盈率波动区间。】
如下图:
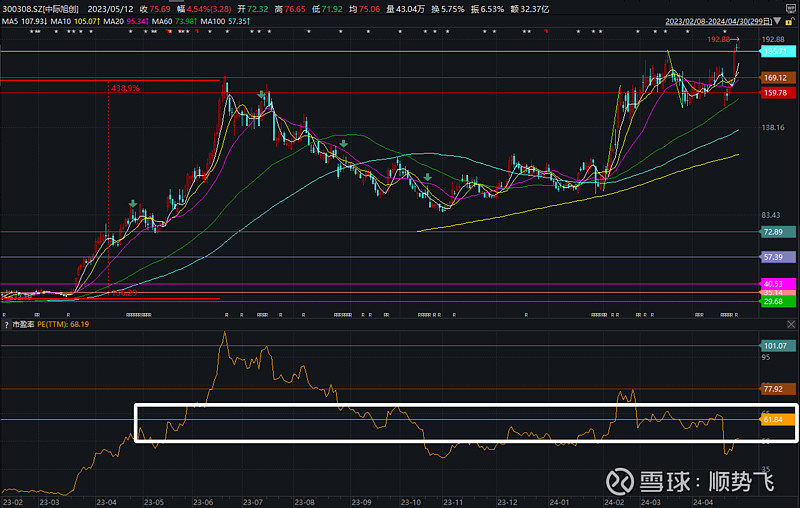
从远期利润看,测算市值高点(市场可能认为的利润高点),
给与10-20倍估值(参考阳光电源近期的市盈率水平)
2028年假定利润在280亿—600亿之间,对应市值为2800亿—12000亿市值。
(反向推算,按照市场过渡炒作达到顶峰后,市值然后下跌一半,到2800亿,则预期也能在5600-6000亿左右。)
三,基于历史产业大周期中代表性牛股的股价普遍涨幅(乐观情形)
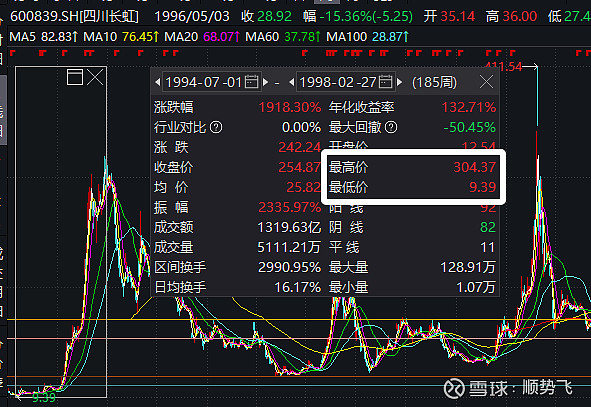
3.1、90年代的四川长虹、海尔——电器设备普及+娱乐化诉求
长虹累计涨幅最高达到32倍,青岛海尔累计涨幅21倍。
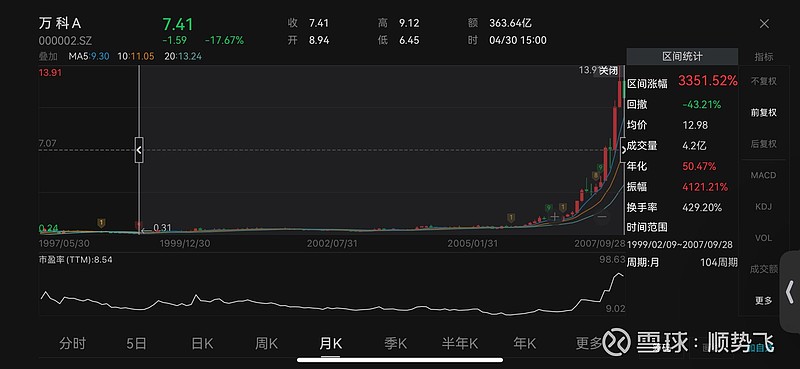
3.2、2000年后的万科、华侨城A——地产货币化+城镇化诉求
万科累计涨幅最高达33倍,华侨城A累计涨幅43倍;
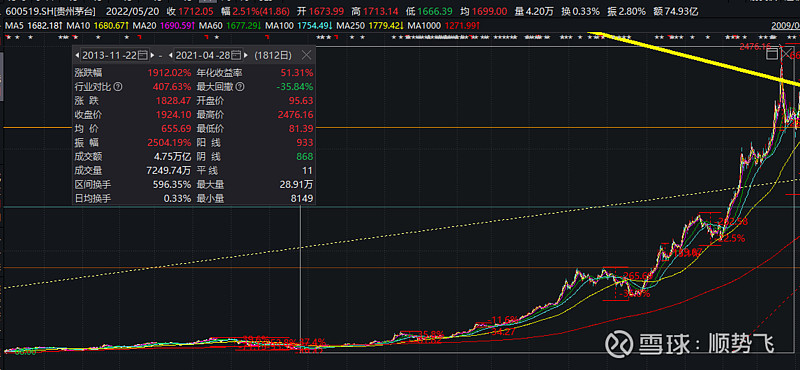
3.3、2013年后的茅台、恒瑞医药——地产中后周期的消费升级+人口中老龄化
贵州茅台从塑化剂事件后,累计涨幅高达30倍;
恒瑞医药在同时期,累计涨幅超过20倍(此前回调比茅台更小,从回调不超过50%算起,累计涨幅超40倍);
3.4、2010年后的腾讯控股、舜宇光学、立讯精密、苹果——移动互联网周期
腾讯累计涨幅最高达100倍,舜玉光学累计涨幅最高超200倍,立讯精密累计涨幅超50倍,苹果累计涨幅超84倍。
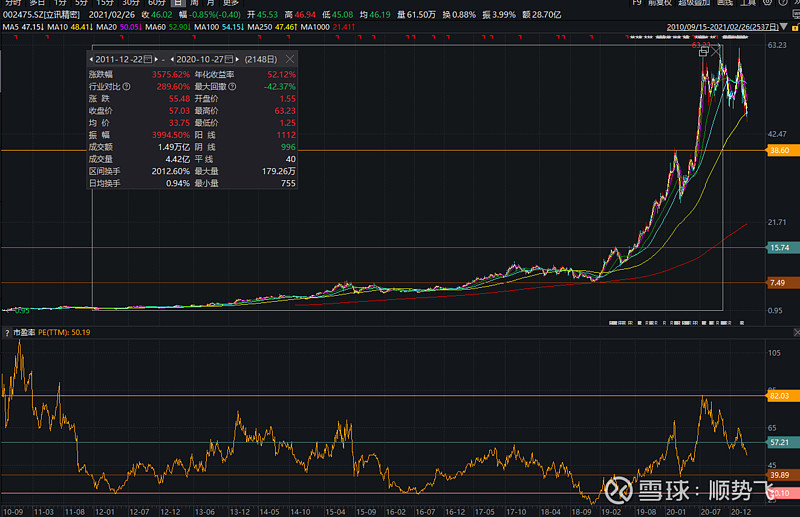
3.5、宁德时代、阳光电源、隆基绿能——环保+能源变革与替代
2018年后,宁德时代累计涨幅高达11.7倍,阳光电源累计涨幅最高达35倍,隆基绿能累计涨幅最高达32倍。
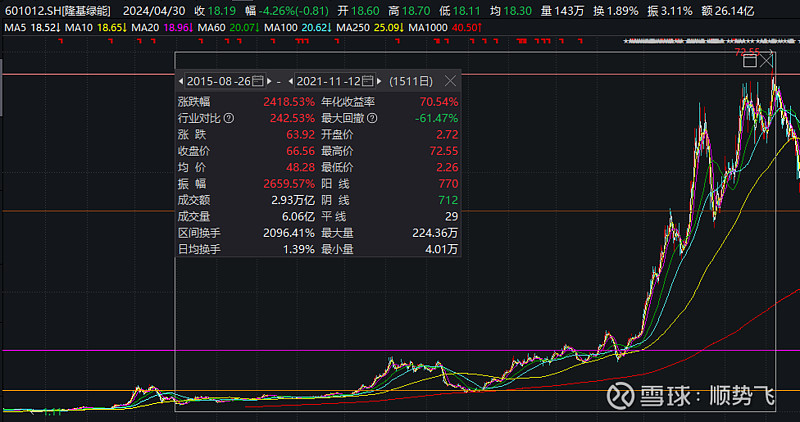
我们可以发现,每个10年左右的大的产业周期或者需求周期中,核心品种的涨幅起步都是30倍左右的累计涨幅。
假定中际旭创是A股在人工智能时代,(业绩预期最强,经营稳定性也相对其他科技股最高的品种,竞争格局相对较好。参考舜宇光学、立讯精密定位)
以2022年9月30日阶段最低点市值作为基准
按照20倍累计涨幅,对应市值为4063亿元。
阶段结论,如果中际真能达成30倍涨幅,测算市值为6142亿元。
【务必注意,此处仅为推演,不代表事实】
四,基于市场定价有效性和产业革命最高市值公司倍数测算
前几天,笔者曾经写过,
市场对于成长阶段的股票,要么定价极为高估(类似2000年的思科,估值定价很高。类似2021年见顶的宁德时代、阳光电源,);
要么定价看似挺高,实际非常低估(类似1996年的思科,2010年的茅台,2014年的爱尔眼科,估值定价也偏高)。
以这种视角来思考,
如果未来5到10年是人工智能发展的大时代(重点之重点,如果不认可,基本可以不看)
在产业趋势刚刚开始的第2年初,$中际旭创(SZ300308)$ 的定价,在当下是极为高估的概率更大,还是非常低估的概率更大???
(需要各位问问自己,给自己一个答案。)
从产业周期看
历史上大的工业革命或者产业革命下,
龙头上市公司的市值相对于上一代龙头顶峰市值都会有10倍量级的扩张(这个结论不接受反驳![[没眼看]](//assets.imedao.com/ugc/images/face/emoji_45.png?v=1 "[没眼看]") )
)
可以看下美国公司的例子:
纽约中央铁路(1亿美元,1878)
纽约中央铁路于1853年由多家公司合并而成,1878年公司市值达到1亿美元。该公司建立了连接纽约、芝加哥、波士顿和圣·路易斯的重要铁路,代表着美国大规模的铁路运输开发史
AT&T(10亿美元,1924)
1916年,美国电话电报公司(AT&T)成为道琼斯工业平均指数成分股。1924年,公司市值达到10亿美元,是第一家市值达到10亿美元的美国公司。
通用汽车(100亿美元,1955)
1955年,通用汽车成为第一家市值达到100亿美元的公司。20世纪50年代正是通用汽车,福持汽车这样的美国汽车公司的黄金岁月。彼时,丰田汽车尚未大规模进入美国汽车市场
数十年后,在金融危机的冲击之下,通用汽车于2009年6月向纽约破产法院递交破产申请,并波道琼斯工业平均指数剔除。2010年11月,曾被摘的通用汽车重返华尔街
通用电气(1000亿美元,1995)
1995年,通用电气成为美国第一家市值达到1000亿美元的公司。那个时代,也是杰克·韦尔奇执掌通用电气以来最红火的时代。
苹果公司(3万亿美金,2023)
2018年8月3日凌晨,美股周四收盘,苹果公司市值终于1万亿美元大关,正式成为首家市值破万亿美元的科技公司。此后在2023年7月19日,苹果成为世界证券历史上第一家市值达到3万亿美元的公司。在2010-2020年初期,苹果公司凭借苹果手机进入了移动互联网时代,将股票市值天花板扩张至万亿美金。
阶段结论:
人工智能时代,随着AI对各类行业、公司和生活更方面的改进和效率提升
笔者预计这个时代会极大概率迎来10万亿美金级别市值的上市公司。
而,假定,假设,假如……英伟达达成超过10万亿美金(反向推算业绩,4000亿美金净利润,25倍市盈率,对应10万亿美金市值。4000亿美金是否不可预期还是有机会接近,可以看上面英伟达高管对于人工智能达到6000亿潜在市场的目标值。![]()
乐观看15万亿美金,按照5000亿美金净利润,30倍估值算)
对照当下英伟达2万亿的市值,其涨幅将超过5倍-7倍。
(20240501更新:从图形结构推演英伟达未来股价——目前英伟达正在形成2次基底,第一次基底区间为450美金+-50美金的范围,目前第二次基底为850美金+-100美金的范围。未来第三次基底可能形成的区间为1700美金+-200美金的范围,第四次基底的区间为3400美金+-500美金的区间。突破后会超过4000美金。
而4000美金,25亿股本,对应10万亿美金市值)
则A股的映射概念,也将有机会随之扩张5倍-7倍。
中际旭创,作为与AI时代核心玩家绑定最紧密的A股标的,在海外龙头扩张5倍-7倍的情况下,市值同步扩张也将从1500左右,扩张到6500亿-10500左右的市值。
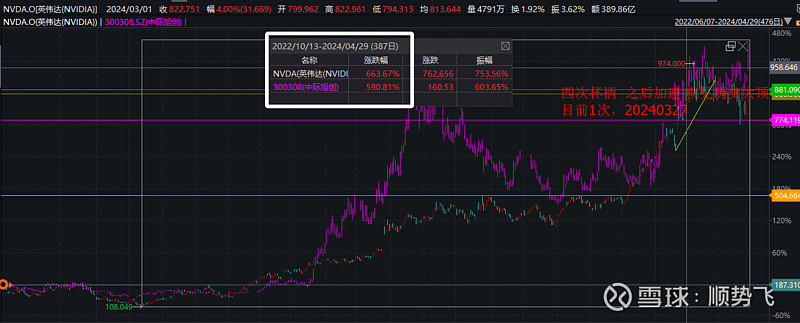
综上,预计中际旭创较为乐观的市值可能落在6000亿人民币左右(8.03亿股本,对应股价747元),有一定的可能性达成。
这里可以做反向推算达成难度,比如在120亿利润水平下,估值50倍,达到6000亿水平。120亿利润大概在2025年到2026年,可能有一定概率达成。
极为乐观考量,预计市值可能在9000—12000亿市值(8.03亿股本下,对应股价1120-1245元)。
同样做反向推算,按照50倍到80倍市盈率(有泡沫),对应预估业绩125亿到200亿之间,相关业绩可能达成时间在2026年—2027年。达成概率可能相对较低一些。
需要注意,这一周期可能会走的相对漫长。需要一步一步的去看。
同时,不要说笔者按计算器,因为市场走势其实并不以个人观点为转移。笔者仅仅是做了测算,
更为重要的是——
【定性分析上,人工智能时代是否来临,产业是否爆发,增速是否是可见未来最高的。都需要各位问问自己。
这里只是给与推演的路径和测算依据,至于自己是否认可,需要根据各位自己的体系做好产业发展研究,行业竞争格局分析,公司业务发展测算和估值的合理评估!!!】
小TIPS:
假定真的推演实现,未来反转下跌,即见顶可能的原因可能有:估值过高,算力需求增速开始放缓导致中际利润增速放缓,技术变化光模块的应用减少,甚至被取代。或者,下游应用爆发,更加具有吸引力的公司和行业出现等等。
好了,笔者的推演结束。务必再次注意下方的提示——
【重点提示:以上仅为线性推演的假设参考,未有考虑任何风险因素,未有做任何风险补偿测算。仅作为YY之用。股市有风险,投资需谨慎!股市有风险,投资需谨慎。】