
5月23日,英伟达发布财报。其中,网络部分的营收低于预期。与市场预期的Mellanox网络收入将达到36亿美金以上相比,一季度数字为31.7亿,相比去年Q4的33.3亿出现了环比下降。公司交流指出,未来将在以太网持续发力,Spectrum-X网络平台收入今年将达到大几十亿美金。为何IB网络渗透率提升遇到瓶颈,后续行业形势如何?我们将在此文作简要分析。
首先简要介绍两种网络类型。IB网络全称Infiniband,早在1999年由英特尔、IBM、Sun、戴尔等厂商组成的IB贸易协会(Infiniband Trade Association)发起,旨在为当时的PCI技术提供高速、高扩展性、高统一性替代方案。后来,由于网络泡沫破灭,巨头退场,该方案仅剩Mellanox一家默默支持。后来,英伟达收购Mellanox,将其网络技术用在自家数据中心方案中。因为IB网络设计伊始就是为数据密集型应用设计,特别适合Ai训练这种受制”带宽墙”的场景,在2022年以来的生成型AI浪潮中站在了风口浪尖,IB网络的渗透率节节攀升。
图一:前500超算系统中网络技术份额
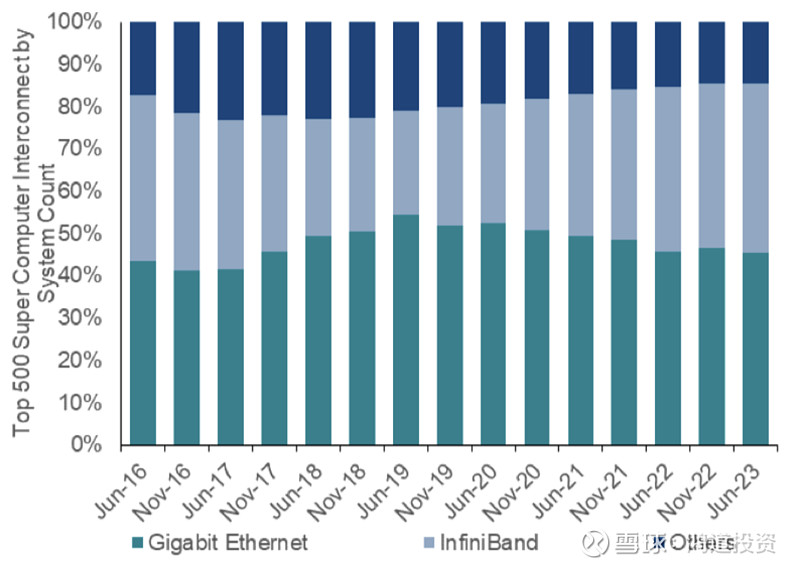
(数据来源:BNP Paribas)
以太网英文全称Ethernet,是1970年代就诞生的技术,是为通用局域网互联设计的一种规范,世界上超过90%的局域网都是以太网构建的。以太网需要适应的应用场景、物理链接规范、传输协议都要比IB宽泛的多。AI训练中,由于GPU、网卡、内存之间需要高速传输数据,业界发明了一种名叫RDMA的技术,使网卡接管数据,在发送方和接收方的内存间直接传输数据,从而绕过缓存和操作系统。IB和以太网都支持RDMA,支持RDMA的以太网称为RoCE(RDMA over Converged Ethernet)。以下所称的以太网,全部指应用RoCE技术的以太网。
以太网和IB各有千秋。IB的优势是,他原生支持数据的无损传输,采用了一种叫流量控制(Flow Control)的机制,防止网络拥堵引起丢包。同时,IB采用一种特殊的网络拓扑结构(Switched Fabric),将网络上的节点通过交换电路两两互联,达到更高的吞吐量,这比采用了广播网络(Broadcast Network)的以太网效率更高。最后,IB网络与英伟达自家显卡、网卡配合更好,支持很多独家特性。所以IB网络无论延迟、带宽、吞吐量还是拓扑灵活性都要显著强于以太网。
但IB网络的成本显著高于以太网。它和英伟达的一整套解决方案绑定,网卡、交换机、光纤、光模块都要选购英伟达的,整体的成本最高可达以太网的5-10倍。
以上反映在行业上,可谓公说公有理,婆说婆有理,双方都认为各自方案更优。英伟达是坚定的IB支持者。英伟达认为,买得多省的多,虽然IB贵,但选用了其整套解决方案后,训练和推理的效率将大幅提升,摊在全生命周期上还是划算的。以太网支持者则认为,便宜就是硬道理,以太网不用和英伟达绑定,还可以对网络自行调优,达到和IB类似的性能。以太网的支持者包括交换芯片ASIC设计商博通、采用博通交换芯片的白牌交换机厂商Arista、几个自行设计ASIC的下游云厂商和AMD、英特尔等非英伟达AI加速卡设计厂商。2023年8月,以上多家公司设立超以太网联盟(Ultra Ethernet Consortium),旨在发展可以媲美IB的下一代以太网,一副天下苦秦久矣之势。
在23年初到现在的生成式AI爆发期,IB网络无疑是成功的,英伟达“买得多省的多”的战略大获全胜。2023年,英伟达的Mellanox分部营收从1季度的9亿上升到了4季度的33.3亿,全年超过80亿,已经占数据中心营收的16.8%,甚至接近了大家熟知的游戏显卡营收。
由此,市场将上述趋势外推,认为未来AI训练网络所有份额都会被IB攫取,对Mellanox的盈利预测不断上调。但23年底开始,产业上明显有了不一样的声音。
在三月中旬的博通AI Day上,博通向投资者展示了Meta的两个2.4万卡大型数据中心,其中一个由IB打造,另一个由以太网打造。以太网版本性能表现甚至高于IB版本10%,成本是其1/2。在5月的Arista业绩会上,公司确认Meta此数据中心采用了其交换机产品。
四月,微软和OpenAI爆出将合作打造“星际之门”项目,砸千亿美元打造一台AI超算,微软一直是IB的最大金主,但OpenAI却告知微软,倾向于使用开放以太网替换掉英伟达的IB。
云厂商方面,亚马逊的AWS和谷歌GCP都采用了魔改版的以太网架构,选择对IB观望。AWS(亚马逊)的EFA采用了8x400G以太网,谷歌GCP则采用了8x200G以太网。
我们认为,市场代表的”理想”和客户所代表的”现实”有所出入,但并不冲突,因为以太网和IB本来就是萝卜青菜的关系。市场喜欢站在股票角度,论证非黑即白的问题,但客户往往基于自身业务和财务角度,考虑更多“柴米油盐”的问题。
两者的设计初衷不同。以太网的设计目标是实现不同系统之间的互连互通,因此需要考虑兼容性、灵活性和通用性,而不是追求极致的性能。IB网络的设计目标是解决高性能计算场景中的数据传输瓶颈,因此需要考虑高带宽、低时延、高可靠性和高可扩展性,而不是追求广泛的兼容性。
极致性能方面,IB做的相当出色。举个例子,IB支持一种叫SHARP(Scalable Hierarchical Aggregation Protocol,可扩展分层聚合协议)的关键特性,可以与英伟达的显卡和交换机芯片配合,将部分大模型训练的运算放在交换机上。比如SHARP支持一种叫Allreduce的运算,它像一个传达室师傅一样,先高效地收集不同节点中的数据(reduce),再把结果分发给各个机器,避免了两两互传造成的延时。
AI训练对丢包非常敏感,0.01的丢包率就会使RDMA吞吐率下降为0。IB是一种无损(loseless)网络,是天生为RDMA设计的,从硬件级别保证可靠传输。以太网则是一种有损网络,因为日常应用场景中,网络是不可靠的,设备A发给设备B的信息很可能丢失,以太网需要考虑这种可能。传统的以太网采用TCP/IP传输协议,消息需要通过操作系统内核,增大了数据移动复制开销。即使后来出现RoCE,使以太网能支持无损网络,更好适应分布训练场景,性能也比不上IB。
采用IB网络通常能用到英伟达最新最快的网络系统,它们通常是领先业界的。2021年初英伟达发布Quantum 2 400G网络系统时,业界主流还停留在200G甚至100G。2024年初的GTC大会上,英伟达推出Quantum X800,将超算网络速率提升到了1.6T。Quantum X800在业界首先采用了224G速率SerDes,业界主流还停留在112G。简单讲,SerDes是交换芯片上一种重要的电路,作用是高效率的串并联数据转换。Serdes速率越高,交换机达到同样吞吐量需要的光口数越少,这意味着更高的传输效率、更少的光模块交换机使用量,更简洁的网络架构。
最后,IB与英伟达自家的软件栈和NVLink配合的都更好。总结一下,英伟达确实将网络与计算合二为一,配合自家的软件支持,打造了极致性能但又极端昂贵的解决方案。
在生成式AI爆发的2023年,模型参数量从GPT2的15亿膨胀到了GPT3的1750亿,已经超过了人脑神经元的数量。以ChatGPT、Midjourney、Character.AI为代表的AIGC应用如雨后春笋般涌现,估值节节攀升。焦虑感使各家大模型和云厂商全力投入军备竞赛,落后一个月就有可能失去先机。在这个阶段,训练是绝对的需求主力,客户需要更快的速度、更多的卡。然而,由于台积电之前的先进封装相关资本投入不足,英伟达的加速卡遇到了严重的产能瓶颈问题,“一卡难求”贯穿了23全年。英伟达的系统分以太网和IB两种规格,但重金买IB版本的客户往往能更快的拿到卡。与英伟达关系密切的超微电脑、Alchip等厂商也能帮厂商更快拿卡,也享受了一波“关系”红利。可以说,2023年全产业链都在为英伟达能生产出更多的卡、客户能拿到更多的卡服务。以上两个因素是IB网络在去年渗透率快速上升的重要原因。
但进入2024年,随着产业链瓶颈开始被一一攻破,卡已经不再稀缺。AI服务器厂商新入者戴尔和HPE在其年初的年报发布会上都指出,“GPU的供给出现缓解,交期已经显著缩短”。同时,大模型单纯基于参数量的迭代也进入瓶颈期,产业开始趋于冷静,厂商开始思考切实可行的应用落地方法。在4月底的发布会上,谷歌和OpenAI都发布了其适合端侧的成熟多模态模型,市场关注点开始转向消费者的实际体验。由于一年间厂商都囤积了一定数量的训练卡,下游应用对推理算力的调用也开始稳步增长,推理需求开始边际取代训练需求。2月中旬,英伟达首席财务官Colette Kress表示,过去12个月数据中心营收中有超过40%的业务是有关部署AI模型,而非训练。这显著的超出了市场预期。在年初,瑞银分析师还预计,到明年有90%的芯片需求将源于训练,推理芯片仅占到市场的20%。
初创公司Groq的CEO,谷歌前AI工程师Jonathan Ross指出:“对于推理领域,你能部署多少取决于成本。” “在谷歌,有很多模型都能训练成功,但其中的80%都没能部署,因为投产的成本太高了。”
英特尔的CEO Pat Gelsinger在去年年底的一次采访中曾提到:“从经济学的角度看推理应用的话,我不会打造一个需要花费4万美元的全是H100的后台环境,因为它耗电太多,并且需要构建新的管理和安全模型,以及新的IT基础设施。”
在推理网络中,以太网确实有一定的比较优势。首先当然是便宜。据我们估算,Meta最新采用了IB网络的2.4万卡数据中心总投资可达9.1亿美金,其中IB网络部分的成本就占了20%以上。其中单个交换机成本超过35000美金,总体交换机开销在接近7000万美金。但采用了博通芯片的相关交换机售价仅为其一半不到。如果采用以太网,这个数据中心上Meta可以节省超过9100万美金。
IB的拓扑结构比较复杂,需要更多的昂贵配件。以标准的8000张卡H100配置为例,采用博通或英伟达以太网交换机方案仅需要192个交换机,但采用IB方案需要448个交换机和3倍的线缆数量。
其次,以太网有强大的生态基础,而 IB 网络则相对比较小众,需要专业的运维人员,天生处于劣势。同时数据中心网络三张网均可以采用以太网构建,三网合一,只需要一个运维团队,统一的运维策略。
以太网也有不可比拟的灵活性。在IB网络刚诞生的20年前,它主要用于点对点或小规模集群。因为当时,企业客户购买的HPC集群通常只有256个节点,最多也就1000个节点。如今,拥有1万个节点已经不是什么稀奇事。微软等厂商开始探讨更大规模,涉及10万个节点甚至更多节点的部署。当前IB最大的网络集群只有16000节点,已经满足不了GPT4级别模型的最低集群大小。由于网络连接复杂,IB网络一旦建好,想增添节点会变得很繁琐,对部件损坏的容忍度也更低。但这正是以太网擅长的。
在大规模集群中,IB过于“严谨”的特性也带来了麻烦。首先,IB网络有一种特殊的”信用流量控制”机制(Credit-based Flow Control),“信用”是接收端返还给发送端的一种回执,显示当前接收端的缓存还剩多少。大量发送数据后,接收端的缓存被填满,接收端将不能再发送数据。由于设计原因,这种情况会在各节点中“传染”,并形成网络阻塞,影响了实际性能。Arista声称Meta经过调校的以太网集群性能比IB集群性能高10%,确实有其现实基础。
在厂商的实际应用中,IB也显得太”娇贵”。与训练这种一次性、连贯性任务不同,下游客户的推理调用具有明显的波峰波谷和随机特性,网络波动是家常便饭。IB网络的信用机制不能很好的适应这种千变万化的网络环境。
所以,当IB网络已经不是拿卡的”敲门砖”,客户通过调优能达到甚至超过IB的性能,也不用和英伟达进行生态绑定,以太网和IB攻守之势生变。
站台以太网的厂商不能放过这个机会,在去年成立了超以太网联盟(UEC),前文已经提过不再赘述。在UEC的愿景中,厂商选择什么网络设备、甚至什么厂商的卡都是自由的,同一集群中可以存在不同品牌的卡,它们以统一的节点内和节点间规范互通,也可以享受以太网更多样化和成本更低的配件。
面对这种兵临城下的架势,英伟达开始应对。在5月的业绩会上,公司指出高层很重视以太网的市场前景,其Spectrum产品线可能在当年达到数十亿美元的收入规模。Spectrum是英伟达的以太网产品线,对应其IB的Quantum产品线。Spectrum的性能并不比竞品差。2022年初推出的Spectrum 4与同期博通芯片的交换机同为支持800G的51.2T产品,甚至比自家21年发布的Quantum2交换机性能强。但Spectrum产品线一直不瘟不火,原因是英伟达采取隔代发布策略,先发布利润率高的IB产品,再发布利润低的以太网产品。
发力以太网,对英伟达是一种悖论。Spectrum 4已经存在了两年多,如果能发力早就已经发力,是公司“先IB后以太网”的策略导致其发力不及预期。而若公司改变这个战略,又等于承认IB的不足,需要牺牲毛利和广大以太网配件厂家竞争。从刚发布的GB200系统定价策略来看,人设对老黄非常重要,英伟达往往不愿意“屈尊”牺牲毛利。如果Spectrum的毛利达到或接近Quantum的水平,就失去了以太网低成本的意义,客户不如选择其他厂商的产品。
当然,现在不能断定以太网会全面取代IB,也不会认为英伟达未来一定一家独大。我们对两种技术的发展持开放态度,因为技术进步中,各种破坏性创新是常态,稳步发展才是小概率事件。首先,英伟达自身进步速度是比较恐怖的,前述1.6T交换机领先于业界发布就是一个例子。其在下一代网络技术,比如光电共封装(CPO)的进度也是业界领先的。其次,英伟达对软硬件生态的掌控使其有种种方法留住客户。最后,大模型的技术进化还没有看到明显的颓势,创新仍然可能带来算力需求的非线性增长。我们会时刻关注相关领域的进展。

房地产:组合拳新政研析
简述英特尔为什么站台玻璃基板
从“五一数据”看消费


