
今年以来,随着ChatGPT的火爆出圈,市场对AI大模型以及相关产业链的关注度越来越高。产业链中能够更快吃到全球AI发展红利的环节非算力基础设施莫属,其中的逻辑也非常简单,AI大模型的发展遵循Scaling Law,即在算力越大、数据量越大、参数越多的情况下模型的性能也会越好。提高算力可以提升模型性能,也可以缩短大模型训练时间,因此算力成为各大大模型厂商先行“军备竞赛”的关键。
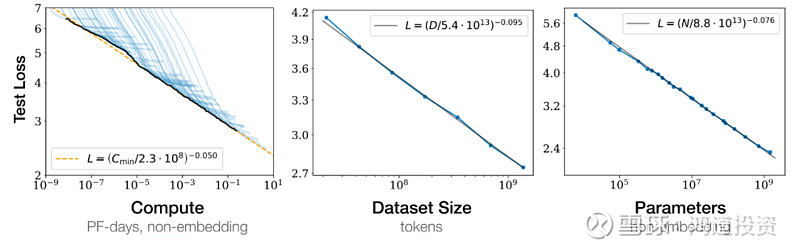
图表 1 大模型的Scaling Law
想提升算力,毋庸置疑GPU是核心中的核心,但由于单卡所提供的算力远不及大模型厂商的需求,他们不得不利用成千上万台GPU服务器组成的算力集群来加速完成自己的训练任务。

图表 2 算力的提升:从单卡到节点到集群
然而,算力的提升不是单纯的GPU的堆叠。随着集群内的GPU越来越多,连接GPU的网络成为了算力提升的瓶颈。从以下两张图可以看到,GPU堆叠带来的算力提升是有损耗的,即1+1可能只有等于1.5的效果,且GPU越多损耗越大。而损耗的来源其实就是网络能力不足,比如平均来看大模型的训练时间中有40-50%的时间用在了网络通信上,而在部分大模型训练中这一比例甚至达到80%以上。在高性能计算集群中,网络可以等效于一部分算力,这也是英伟达CEO黄仁勋如此重视网络的原因。
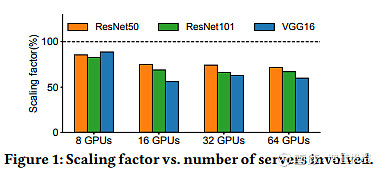
图表3 GPU越多,算力提升的损耗越大

图表4 部分大模型的训练时间构成(蓝色为网络通信部分)
想要针对大模型训练优化网络能力,目前行业中普遍有几种做法:
1、最直接的就是升级网卡,比如英伟达A100匹配的CX6网卡带宽为200G,H100匹配的CX7网卡带宽就升级到了400G,带宽提升可以直接增加数据传输速度;
2、采用无收敛的胖树架构,使每个节点之间可以无阻塞通信,最直观的变化就是每层网络向上总带宽从减少变为相等;
3、增加网络层数来覆盖更多GPU;
4、采用天生无损的IB网络替代传统以太网,避免因丢包产生的网络瘫痪问题;
5、英伟达在GH200中通过扩大私有的NVLink网络覆盖范围,实现256张GPU卡之间达到9倍于以太网和IB网络的通信带宽,将256张GPU本质上变为一张大GPU。
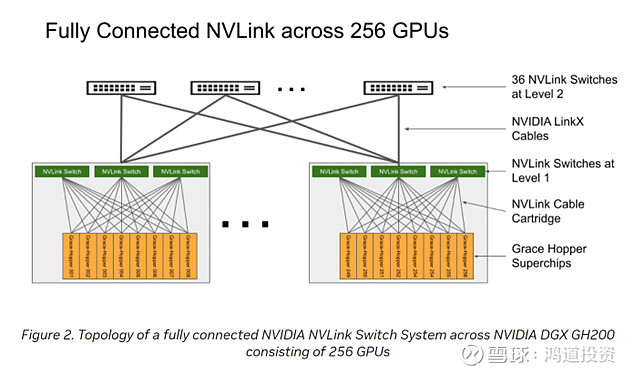
图表5 英伟达DGX GH200的网络拓扑图(通过NVLink连接256张GPU)
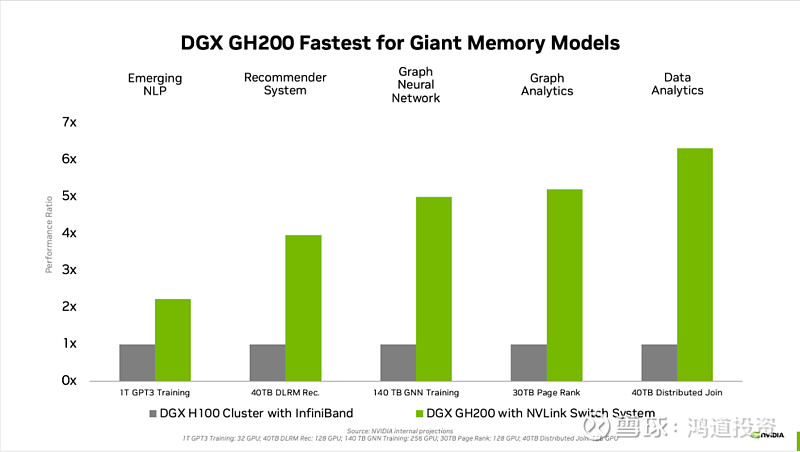
图表6 英伟达DGX GH200相比DGX H100 256卡集群性能大幅提升
以上的各种方案,反映到网络的物理连接上,基本都会表现为整体网络带宽的增加。相应的,承担网络通信功能的交换机和光模块在单个产品传输能力不变的情况下,使用数量要大幅提升才能匹配整体网络带宽的增长。比如市场关注度较高的800G光模块:GPU的比值就有1.5:1、2.5:1、9:1等各种方案,对应的交换机的用量也会有一定提升,取决于具体的网络架构。因此,在AI的拉动下,网络设备投资占整体数据中心capex的比例会有提升,光模块的capex占比可能从传统数据中心的1-2%提升到2-3%或者更高。
整体而言,AI的发展对网络提出了更高的要求。从短期看,可能是一些数字上的变化,包括用量、比例等;从长期看,由于网络是决定算力使用和扩张效率的关键,网络的价值可能向算力的价值贴近,相关的网络设备投资额占比可能会持续提升。我们会持续关注网络相关技术的最新变化,紧跟这一波大的技术升级周期,希望能够有所收获。

锂价下行通道开启,厂商综合能力考验加剧
六月光伏产业链价格速降,上半年国内装机高增
六月乘用车零售同环比实现正增长



