



文丨Congerry
除了投资 AI 创企,微软更要亲身入局。
随着GPT-4、Gemini等大模型的出现,大模型在推理、生成、分析等各方面的能力不断取得突破,但其庞大的参数量和算力需求,也成为了它们落地应用的障碍。
怎么让大模型“小而美”成了许多AI公司孜孜以求的目标。
周二,微软正式推出Phi-3系列模型。它是微软前两个小型语言模型 2023 年 6 月发布的 Phi-1和 12 月发布的 Phi-2 的后续产品。

Phi-3系列模型第一款模型名为 Phi-3-mini,只有 38 亿个参数,这使得它非常适合在智能手机和笔记本电脑中使用的消费级 GPU 或人工智能加速硬件上运行。
Phi-3-mini 可在配备 A16 Bionic 芯片的 iPhone 上以原生 4 位版本运行,速度超过每秒 12 个 token。
虽然参数小,但是 Phi-3-mini 的性能可与 Mixtral 8x7B 和 GPT-3.5 等更大型的模型相媲美。Phi-3-mini有两种上下文长度变体——4K和128K tokens,是同类中首个支持高达128K tokens 上下文窗口的模型,且对质量影响很小。
通过一系列公开基准测试的数据对比可见,Phi-3 Mini(3.8亿参数)在自然语言理解、推理、编码、数学等多个任务上,已经全面拥有了接近GPT-3.5(1750亿参数)的能力。
它在 MMLU 语言理解基准测试中取得了 69% 的成绩,在 MT 基准测试中取得了 8.38 分的成绩。
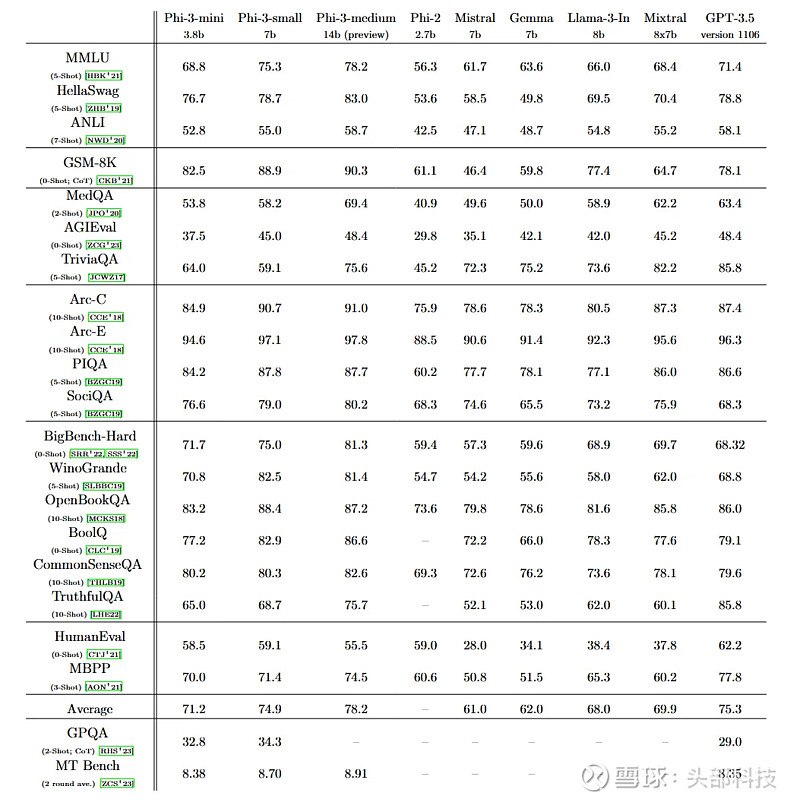
Microsoft 提供的图表,显示 Phi-3 在各种基准测试中的性能。
微软还计划在未来几周内,向Phi-3家族添加更多模型,包括Phi-3-small(7B参数)和Phi-3-medium(14B参数)。
具有 70 亿个参数的 Phi-3-small 和具有 140 亿个参数的 Phi-3-medium,,在同类模型的基准测试中表现与 Phi-3-mini 类似。
他们在 MMLU 基准中分别达到 75% 和 78%,在 MT 基准中分别达到 8.7 和 8.9 分。这使得它们不落后于更大的模型,例如Meta 最近发布的 700 亿参数 Llama 3。
在大多数情况下,Phi 模型的性能优于同类模型(Phi 3 7b 与 Llama 3 8b相比)。
在数据上,微软的研究团队通过使用精心策划的高质量训练数据,这些数据最初来自教科书,成功地将Phi-3模型的能力压缩到如此小的尺寸。
微软表示,这种创新完全在于他们的训练数据集,这是phi-2使用的数据集的扩展版本,由大量过滤的网络数据和合成数据组成,并且模型还针对鲁棒性、安全性和聊天格式进行了进一步的调整。
不过微软指出,与更大的模型相比,Phi-3-mini 的事实知识能力较低,例如在 TriviaQA 基准测试中,这是一个弱点。然而,这可以通过搜索引擎的集成来弥补。
在安全方面,微软表示,Phi-3 采取了多步骤方法,包括一致性培训、红队、自动化测试和独立审查,大大减少了潜在有害反应的数量。
据微软称,Phi 3 使用与 Meta 的 Llama 模型类似的块结构和相同的 tokenizer,以便让开源社区尽可能多地从 Phi 3 中受益。
这意味着为 Llama 2 模型系列开发的所有包都可以直接适配Phi-3-mini。
目前,微软已经在其云端 Azure AI Studio、以及 Hugging Face、Ollama 等第三方平台上发布了 Phi-3 Mini。未来几周内,公司还将陆续开源 70亿 和140亿参数量的 Phi-3 Small 和 Medium。
对于AI公司和开发者来说,小型模型将会成为即学小成的绝佳切入点,在降低门槛的同时也不失质量保证。
对终端用户而言,本地和边缘AI设备可能会因此拥有全新的智能服务体验。而从能源消耗和环境影响的角度来看,小模型可能意味着AI发展将步入一个更加可持续的阶段。