“AI 2.0时代,垂直领域的数据会成为重要的生产资料,并带来新的生产力突破。” 商汤科技董事长兼CEO徐立在“人工智能与数据要素产业生态大会”上说。
5月23日,作为第七届数字中国建设峰会的重要组成部分,人工智能与数据要素产业生态大会在福州正式召开。商汤科技董事长兼CEO徐立与中国工程院院士陈纯、中国工程院院士邓中翰、中国科学院院士林圣彩等一同出席,徐立发表主旨演讲,分享了商汤科技在探索新质生产力发展过程中,对于大模型产业化路径的独特见解与实践经验。

会上,商汤与福建实达集团达成战略合作,双方将在人工智能算力建设、智慧城市、智慧应急、人工智能教育、城市能源管理等领域展开合作,推动福建人工智能产业创新,助力“数字中国”建设。
遵循尺度定律,小模型也能具备大模型的能力
Scaling Law(尺度定律)被认为是大模型时代的“牛顿定律”,也是指导人工智能发展的基本法则,即随着模型参数量、数据量、算力的增加,模型的性能也会勇往直前不断提升。
之所以称之为“尺度定律”而非“规模定律”,因为它是一个资源调配的“指示器”。具体而言,尺度定律具有两个特性:
可预测性:可以跨越5~7个数量级尺度依然保持对性能的准确预测;
保序性:可以在小尺度上验证性能优劣,并在更大尺度上依然保持。
尺度定律可以指导我们在有限的研发资源上,找到最优的模型架构和数据配方,让较小的模型也能具备大模型的能力。
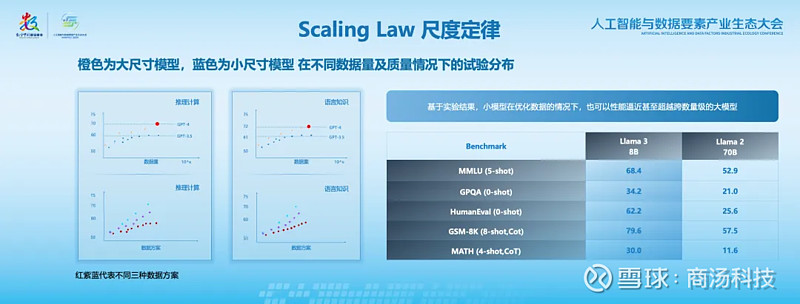
从以上实验数据可以看出,小模型在优化数据的情况下,性能上可以逼近甚至超越跨数量级的大模型。这背后,主要源于高质量的数据要素。
用户体验是大模型最重要标志,感知理解和内容生成双轮循环
最新发布的GPT-4o和谷歌Gemini,为AI行业带来了启发——流畅的体验是决定大模型好坏最重要标志。
流畅的体验来自实测问题上的性能,这与数据强相关,而要获得强大的数据能力,则需打通“感知理解”与“内容生成”的双轮循环。
回顾过去十年,人工智能主要解决对世界感知理解的问题,今天则进入了生成智能的时代。
如果要提升模型性能,感知理解和内容生成能力两者需相辅相成,互相协同。理解可以助力生成,而生成又可以反向推动理解能力的提升,进而形成互相循环的飞轮。
商汤「日日新5.0」大模型体系正是通过感知算法和生成算法协同研发,实现了强大的多模态感知理解和生成能力,并带来了出色的用户体验。
在感知理解能力方面,不仅可以精准解读并理解图像内容,进行问题解答及互动,还能掌握话题及其背后深层含义。如果没有深层次的多模态感知理解能力,那么大模型的水平只能停留在浅层的知识记忆。
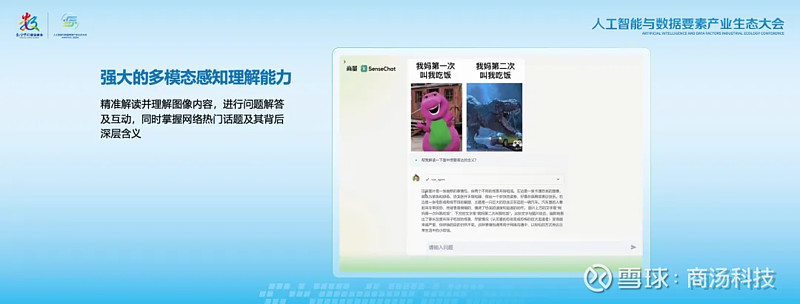
基于深度的多模态理解能力,「日日新5.0」能够精准理解图片背后隐藏的中国文化内涵
在生成能力方面,「日日新5.0」建立在深层次的场景和语言理解能力基础上,由此能够精准把握画作中场景氛围和内容的表达。

人像是评估文生图能力的关键场景之一,「日日新 5.0」生成的人像可以看出非常好皮肤的纹理,而其他几个大模型在皮肤上都做了磨皮
在很多垂直领域,中国有大量早期发展积累下来的知识,用好这些知识,就能做出差异化的生成效果。
在AI 2.0即生成式人工智能时代,垂直领域的数据会成为重要的生产资料,并带来新的生产力突破。如果模型生产出来之后,又能够利用好这些数据对外服务,再次数据资产化,就能形成一个不断迭代的数据飞轮。
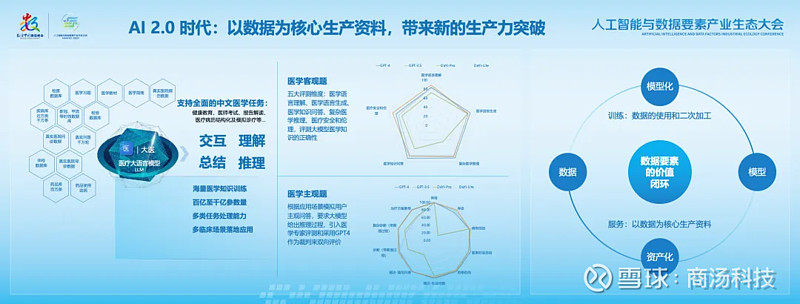
高效的响应速度,是大模型能力产业化的核心
其实,最新的GPT-4o综合能力略弱于GPT-4,但由于响应速度极快,反而可以带来更出色的使用体验。
商汤端侧大模型全面对标甚至超过GPT-4。来看一项有趣的评测:将日日新·端侧大语言模型SenseChat-Lite和GPT-4都接入到著名街机游戏《街霸》中进行对决。虽然GPT-4能够输出连招和复杂的动作,但SenseChat-Lite的出拳速度更快、动作更敏捷,拳拳到位,最终获得了胜利。

红色KEN是商汤日日新端侧模型操纵,绿色KEN是GPT-4操纵
这项评测并非比较模型性能的强弱,而是展示了在该场景下,小模型的响应速度更快。所以,只要找到合适的模型,产业化落地也会变得非常快。
SenseChat-Lite 1.8B作为商汤今年4月发布的端侧大模型,核心指标全面领先所有开源2B同级别模型,甚至在大部分测试中跨级击败了一些7B、13B模型。
当然,单纯的端侧模型,性能自然比不过千亿参数的云端大模型。但通过端云协同方案,将少数任务交给云端完成,而大部分任务放在端侧,可以大大减少推理成本和提升响应速度。
比如,在部分特定任务中,只需要调用30%的云端模型能力,就能获得90%~95%的性能体验,在不损失精度的同时,降低了70%的推理成本。
在性能方面,商汤的端侧大语言模型拥有业内最快的推理速度。比如,人眼睛最快的阅读数字是每秒20个字,而商汤的端侧大语言模型可在旗舰平台达到78.3字/秒。
扩散模型同样可在端侧实现业内最快的推理速度。在某主流平台上,商汤端侧扩散模型的推理速度单张约1.0秒,比友商云端App快10倍,并且支持在端上快速进行等比扩图、自由扩图、旋转扩图等图像编辑功能。
由于响应速度更快,覆盖面更广,端侧应用是生成式大模型落地的重要载体。
比如日常对话、常识问答、文案生成、相册管理、图片生成以及图片扩展等应用,都可以赋能包括手机、平板电脑、VR眼镜、车载电脑在内的海量终端设备。
《时代周刊》曾在1997年、2015年、2018年分别将克隆羊、VR、人工智能作为封面。但这三个都没有真正成为用来命名那个时代的要素,原因是没有真正切入到一个应用来驱动。
去年,《时代周刊》又将ChatGPT放在了封面上,和前面三次选择不同的是,ChatGPT的核心不在于GPT这项技术,而在于将GPT叠加到了Chat这项应用上。GPT是一个2018年就已经形成共识的技术。
所有技术真正意义上普及的关键,在于应用的叠加。中国发展人工智能的最大机会,正是在各种垂直行业的方向上,有着巨大的应用叠加的空间和潜力。
过去几年,商汤与福建省各地市保持长期紧密合作,从城市治理到算力基础设施服务、模型和生态层面进行了多项布局。
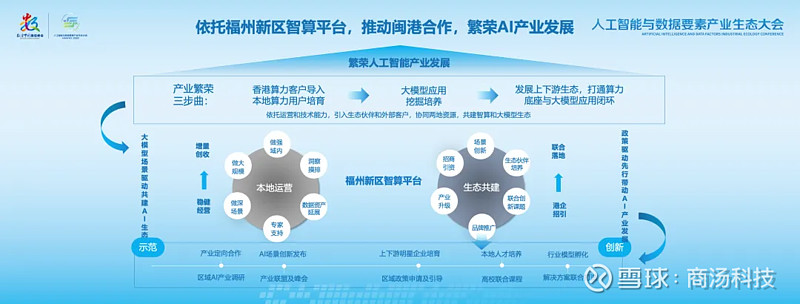
商汤希望依托福州新区智算平台,推动闽港合作及各地的生态协同,共同打造以应用为驱动,以数据资产为要素的核心人工智能生态圈,繁荣AI产业发展。