文章来源于公众号“科学大院”(ID:kexuedayuan)
作者:高睿昊
正文共3295字,预计阅读时间约为11分钟
8年前,高考结束后的暑假,作为班里的“电脑爱好者”,我经常被同学们问上大学配什么新电脑。当时的我告诉大家,配好电脑有两个东西很重要,一个叫CPU,决定电脑反应速度的快慢;另一个叫GPU,负责图形的运算,玩电脑游戏流畅可得靠它。

用于桌面计算机的GPU和数据中心计算机的GPU(图片来源:Amazon)
那时候的GPU,在大家印象里就是用来打游戏的。然而8年后的今天,随着ChatGPT等大语言模型(LLM)横空出世,能够处理人工智能高性能计算的GPU突然引来各大科技公司抢购。自称为“人工智能计算领域的领导者”的GPU生产商英伟达(NVIDIA)在一年内股价飙升,6月19日更是一跃成为全球市值最高的公司。刚刚高考完的同学们要是想买台带GPU的电脑,申请“爸妈轮天使投资”的理由也变成了“我想学人工智能”。

GPU生产商英伟达(图片来源:英伟达)
8年之间,GPU如何从“游戏处理单元”蜕变成“人工智能处理平台”?带着这个问题,今天和大家一起聊聊,GPU到底是怎么回事。
GPU能做的事情CPU都能做?
我们为什么需要GPU
比起GPU,大家可能更熟悉的还是计算机的CPU,全称为中央处理单元(Central Processing Unit)。CPU是计算机的“大脑”,它支配计算机中的其他部件,协同完成网页浏览、游戏渲染、视频播放等等一切“计算任务”。CPU决定了计算机的运行速度,有一句网络用语是“把我CPU干烧了”,就是用CPU工作温度过高失灵,来比喻脑子里的事情太多太复杂,脑子转不过来了。


左为CPU是计算机的“大脑”(图片来源:veer);右为英特尔(Intel)i9-12900KS CPU(图片来源:hothardware)
而GPU也是被CPU支配控制的部件之一。GPU全称为图形处理单元(Graphic Processing Unit),主要功能是完成图形处理相关任务,以GPU为核心的主板扩展卡就是大家在买电脑时经常听说的显卡。

英伟达Geforce 6600 GT GPU(图片来源:wiki)

安装在台式机箱里的CPU和GPU,这是英伟达网站上一个搭载RTX40系列GPU的机箱概念图(图片来源:英伟达)
理论上,所有能由GPU完成的计算任务,都能由CPU完成。一台电脑没有独立GPU仍然能够正常开机,但若是没了CPU就“臣妾不能够了”。既然如此,我们为什么还要花大价钱去买GPU呢?因为,就像我们不能抛开剂量谈毒性,计算机也不能抛开“性能”谈“功能”。

CPU和GPU各有擅长的计算任务(图片来源:IBE)
对于游戏渲染、人工智能这些计算任务,CPU并不擅长,虽然也能从功能层面上完成,但性能表现十分有限。对于游戏渲染而言,性能的局限性体现在更低的帧率,更粗糙的画质上,也许无伤大雅。但在人工智能的应用上,以大语言模型GPT为案例分析,如果仅使用CPU的话,其训练时间将长达数百年,这样的速度显然不能满足我们对于人工智能技术突破的渴望。
而GPU恰好擅长这些“热门且艰巨”的任务。在配置了GPU的计算机系统中,CPU不再孤独地承担一切,而是将这些自己不擅长的任务卸载(offload)到GPU上加速执行。得益于特殊的并行架构设计,GPU在处理这些任务时游刃有余,可以轻松地为我们提供细腻入微的3D画质,让OpenAI公司每隔几个月就能推陈出新。
GPU是如何实现加速的?
从并行架构的角度看GPU与CPU的区别
在开始讨论之前,我们需要进行一个类比:计算机中的一个程序,可以类比成由一连串运算题组成的试卷——计算机科学家们的祖师爷艾伦·图灵就是这么构想计算机程序的。当然,这些运算题有难有易,有小学生就能轻松应对的四则运算,也有高中生可以玩转的三角函数,还有大学生才能完全掌握的微积分。
计算机科学家曾希望CPU可以像一位经验老道的“数学家”,发挥他的计算能力(计算指令)、敏锐的决策力(控制指令)快速地完成试卷(程序),得到用户想要的结果。而随着计算机的程序越来越复杂,“老数学家”的能力逐渐不能满足要求了,他主要的缺点是:即使每道题都能算的很快,但任何时间都只能一心一意地算一道题。
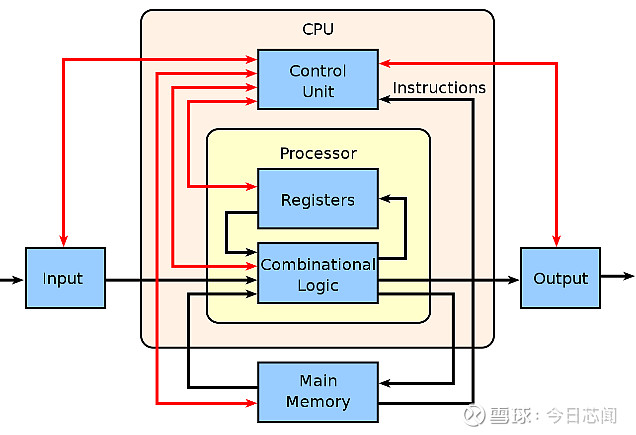
单核CPU计算机的工作框架,黑线为数据流,红线为控制流,均由单个CPU处理(图片来源:wiki)
于是,英特尔、IBM、AMD等公司开始意识到,可以在一个CPU内“聘请”多位数学家,也就构成了目前常见的多核CPU。当然受限于芯片散热、良率的约束,多位数学家中的每一位都不像的从前的那么强,可能更像是多位准备参加高等数学考试的“大学生”。——为什么是准备参加呢?因为考完试就忘了(扎心)。
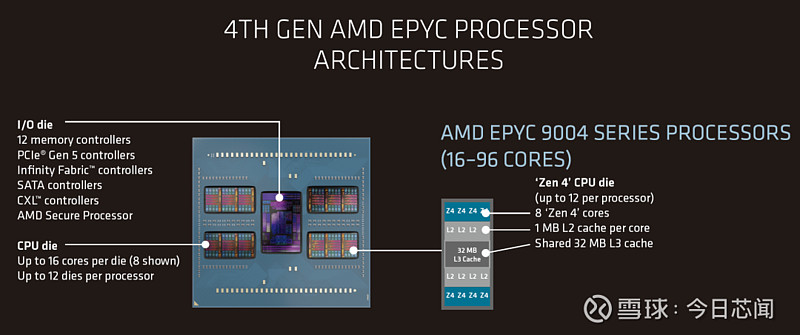
第四代AMD EPYC处理器架构,EPYC是AMD的高性能服务器处理器系列,图中的Z4就是我们所说的“大学生”核心,一个CPU中可包含16-96个核心(图片来源:AMD官网)
GPU则可以类比成约由几千到上万个“小学生”核心组成的大型计算团队。相比于大学生核心,单个小学生核心只能计算更简单的运算,且计算速度也仅有大学生的1/4~1/3。下图展示了英伟达H100 GPU的架构,“小学生”核心对应图中的绿色小格子,一共有18432个。一万多名小学生核心先被层层划分成为上百个“班级”,在班级内部再动态划分成32-64人一组的“值日小组”。

英伟达H100 GPU架构图,GPU中包含了众多小核心,按照层次结构进行组织(图片来源:英伟达H100架构白皮书)
该如何让这么多小学生核心高效协作呢?像CPU一样让每个小学生都独立完成试卷,显然不是一个理智的方案。为了解决协同问题,英伟达GPU增加了一条规则限制:每个“值日小组”内的所有核心(线程)在同一时间只能执行一种运算操作(指令),而一个或多个值日小组(可以跨越班级)可以被组织起来共同完成一张程序试卷,这种协同工作模式被称为单指令多线程并行(Single instruction, multiple threads,简称为SIMT),是英伟达GPU运作的核心模式。我们用一张示意图对比CPU和GPU的并行运作方法。
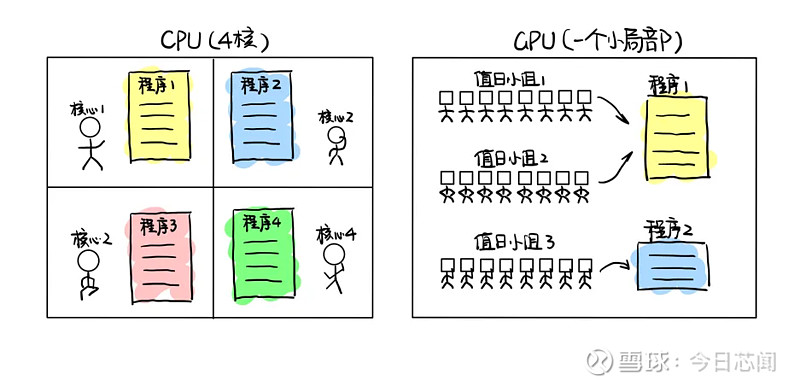
多核与SIMT并行方式差异的示意图(作者自制)
聪明的你应该已经意识到,这种奇妙的组织方式会让CPU和GPU所能做答的试卷产生明显的区别。如果CPU(单个核心)的试卷长这样:
已知:
a = 1, b = 2, c = 3
又知:
d = a * 2
e = d + b
f = c / e
求: f
那么 GPU 的试卷将会是这样的(假设一个值日小组有三个核心):
已知:
a0 = 1, a1 = 2, a2 = 3,
b0 = 4, b1 = 5, b2 = 6,
c0 = 7, c1 = 8, c2 = 9
又知:
d0 = a0 * 2
d1 = a1 * 2
d2 = a2 * 2
e0 = d0 + b0
e1 = d1 + b1
e2 = d2 + b2
f0 = c0 / e0
f1 = c1 / e1
f2 = c2 / e2
求: f0, f1, f2
这也太奇怪了!怎么会有人出这样的试卷呢?事实情况是:图形渲染和人工智能应用恰好符合这样的特点。对于图形渲染而言,输入的3D图形是由众多离散的点坐标组成的,在渲染过程中需要并行地对多个点进行相同的位置转换、光照运算;在人工智能应用中,现实世界输入的图像、文字被表达成了大规模的矩阵和向量,而矩阵和向量之间的运算操作也可以抽象成多个数值并行执行相同的运算,正中SIMT并行的下怀!
既然,GPU的并行模式这么优秀,我们为什么不干脆把CPU也设计成这样呢?答案是:SIMT并行相比多核并行损失了一定的“通用性”。在我们的类比中,更直观的表达是:我们不一定能把试卷组织成适合GPU的样子。一个案例便是我们每天都在访问的微信、淘宝等互联网应用,由于每个用户都在发送不一样的消息、查看不一样的商品,很难让GPU的值日小组高效协同。
如何乘上AI的“东风:从GPU到GPGPU
1999年,英伟达发布了世界上第一款GPU——GeForce 256,它集成了变换、裁剪及渲染等图形计算的硬件加速,也因此被命名为图形处理单元。

GeForce 256 GPU(图片来源:wiki)
早期GPU的可编程性很弱,大多数用户只能调用固定的编程接口进行固定的图形操作。但是一些具有前瞻视野的计算机科学家意识到了GPU可挖掘的并行计算潜力,他们尝试将洋流模拟、大气模拟等科学计算问题映射转换成GPU可支持的图形操作,并获得了性能收益。

搭载GeForce 256 芯片的GPU板卡(图片来源:VGA Museum)
也许是受到了这种“歪打正着”的应用场景启发,2007年英伟达推出了CUDA(Compute Unified Device Architecture)编程框架,向开发者全面放开了GPU的可编程能力。借助CUDA,用户可以用类似C/C++的编程方式编写适用于GPU的并行程序。从此,GPU的名字变成了GPGPU(General-purpose computing on graphics processing units),多出来的GP表达了对通用性的支持。
在比CUDA推出稍早一点的2006年,人工智能泰斗Hinton及其团队改进了深度神经网络的训练方法,属于“连接主义学派”的深度学习方法开始回暖。到了2012年,图像分类模型 AlexNet 赢得了 ImageNet 竞赛,激发了深度学习研究的热情,借助GPGPU进行训练的方法开始被广泛采纳。2014年,NVIDIA推出了cuDNN深度学习加速库,让基于GPU的深度学习训练变得更加容易。
之后的故事我们逐渐熟悉,2016年谷歌的人工智能围棋软件AlphaGo击败韩国棋手李世石,在AlphaGo的早期版本中,谷歌使用了176块GPU支撑其运行。
由上百块GPU训练的AlphaGo击败了韩国棋手李世石(图片来源:Deepmind)
2022年末,聊天机器人ChatGPT惊艳登场,引发了人门对于人工智能技术新一轮的憧憬。ChatGPT是一种大语言模型,能够基于海量文本数据的训练,通过机器学习理解并生成人类语言。尽管缺乏公开数据支持,但是相关领域研究者普遍认为OpenAI公司采用了数千到数万块当时顶级的NVIDIA A100 GPU以支持训练。

聊天机器人ChatGPT掀起了人工智能新一轮的研究热潮(图片来源:pexel)
在此背景下,支撑大模型算力需求的GPU正成为各大科技企业争夺的“紧俏货”。作为具有垄断地位的厂商,英伟达在这场人工智能的狂潮中,凭借十余年的技术积累,成功抓住了机遇,完成了从“游戏处理器”到“人工智能计算平台”的华丽转身,可谓是“好风凭借力,送我上青云”。
英伟达在GPU领域处于全球垄断地位,然而受限于美国政府的出口限制,高端GPU型号对我国处于禁售状态。开发设计具有独立自主知识产权的人工智能计算平台,是我国计算机科研人员当前发力的重点问题之一。那么,刚刚高考完“想要学人工智能”的你,愿不愿意参与到这一开启未来的征程中来呢?
作者:高睿昊
作者单位:中国科学院计算技术研究所
-END-
本文出品自“科学大院”公众号(kexuedayuan),转载请注明公众号出处。
科学大院是中国科学院官方科普微平台,致力于最新科研成果的深度解读、社会热点事件的科学发声。
主办机构:中国科学院学部工作局
运行机构:中国科学院计算机网络信息中心
技术支持:中国科普博览
今日芯闻
服务内容
广告投放 | 政府招商 | 产业报告
投融资 | 专家咨询 | 人才服务 | 论坛策划
推荐阅读
成立一年估值70亿元,谁在争夺“天才少年”
苏州半导体独角兽,要IPO了
168亿元半导体收购案,诞生!
良品率提升22%!格创东智助力打造半导体智慧数字车间
芯片大佬最新年薪曝光:2.48亿元!
今年最大天使轮诞生了
推荐关注
你的每一个“在看” 我都当成喜欢