

从ChatGPT代表的文生文,到Midjourney代表的文生图,再到Sora代表的文生视频,Suno为代表的文生音乐,“暴力美学”在持续突破内容生产的天花板,多模态也成为了共识的发展趋势,下一个领域会是什么?在人类可视范围,可选的答案不多,更多人愿意押注在3D领域。
它代表了从元宇宙、XR设备、以及Apple Vision Pro 带来的持续期待,关于我们对内容消费体验的不断追求,关于人类自身未来生活的想象。
但3D赛道同时又似乎是目前尚未被巨头覆盖的领域,尚未有基石模型,一切尚在混沌,尚在迅疾发展,但也拉开一场争夺未来的赛马:是发布产品还是打磨技术?是不断迭代还是交付工业标准?是从图像开始还是3D原生?在这些问题的推动下,3D领域的技术在过去一年飞速迭代,甚至已经开始出清。
本文试图描述3D领域的技术发展路径,并通过不同玩家的产品和市场判断,尝试解答上述问题。
有意思的是,似乎当前在3D领域最有价值的工作,多数都是由华人完成的。有团队直白地告诉我们:图生3D的 Sora 时刻,会在中国发生。这真是令人兴奋的判断。
1
从谷歌DreamFusion 开始的升维路径:
从2D图像生成模拟3D模型
与图像和视频不同,人们在日常生活中单纯从视觉感知很少接触真正的3D信息。
因为人的双眼成像和立体视觉机制,导致人的大脑如此容易被骗,我们可以通过多种手段把2D信息做成3D感受,比如最近Sora 带来的视频,比如全景图片、球幕电影、3D电影、裸眼3D等多是如此。
而且,3D资产比2D复杂很多。2D的AIGC基本只有一种选择:生成像素。但是模型、贴图、骨骼、(关键帧)动画等都可以算作3D资产的一部分。而即使是最主流的3D资产——3D模型——其表示也分为网格(Mesh)、体素(Voxel)、点云、SDF、NeRF 等等。
一旦考虑到实际落地到渲染管线中,由于多年来产业发展的基础限制,基本上只有一种主流表示可以选择:Mesh。一个基本的Mesh大概如下图所示。由成百上千个或四方的,或三角形的面,共同构造出一个三维的物的各个角度。
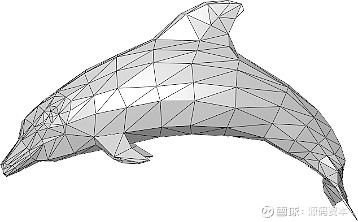
图片来自Polygon mesh的维基百科
在非AI生成的情况下,这样的3D模型可以通过扫描生成,也可以由建模师手动生成。后期再进行对外部材质的贴图,呈现出一只可以用在游戏中的,或是蓝色卡通感的海豚,或是偏灰现实感的海豚。
虽然3D模型属于三维模型,但我们进行观察时,仍然可以从任意面将其视为一个二维图像——这也是最初人们在试图对3D模型进行AI生成时,所考虑的路线——这种路线被称为“2D升维派”。
2022年9月29日,Google发布了文生3D的技术DreamFusion,利用预训练的2D文本到图像扩散模型,首次在无需3D数据的情况下完成开放域的文本到3D的合成。
这中间,是借用了一个叫做NeRF的表达方式,全名为神经辐射场(Neural Radiance Field, NeRF)。
辐射场,是描述光如何从3D场景中的表面发射或散射的术语。而NeRF通过在模型训练过程中,分析模型输出和目标数据(如3D扫描结果)之间的辐射场残差,实现误差反馈,让模型可以迭代优化预测,从而提高生成精确3D表征的能力。
在Google的3D生成方法中,模型并没有见过3D数据,而是见了足够多的2D数据。
实际上,人眼其实也只能看见2D的图像,但是当人对一个物体的多个角度的2D图像进行观察之后,人就能够意识到某个物体,实际上的3D的状态。
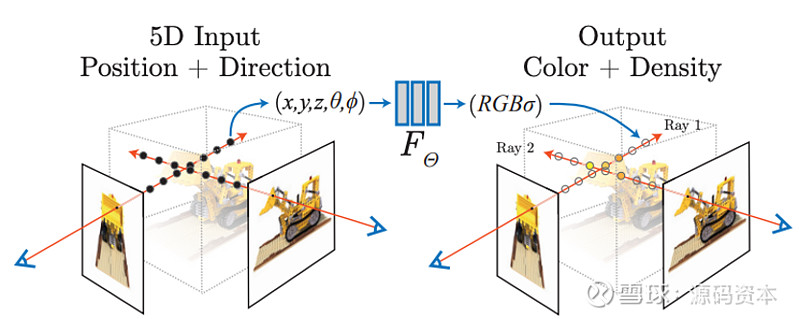
图片来源:Mildenhall, Ben, et al. "Nerf: Representing scenes as neural radiance fields for view synthesis." Communications of the ACM 65.1 (2021): 99-106.
从某个角度来讲,可以把NeRF理解为一个从2D升往3D表达的中间态。当一个人见过物体足够多的角度后,拿一坨粘土,就能捏出这个物体的3D拟合态,这个粘土就是NeRF。
在Google推出这个思路后,其后很久的3D生成,都走了类似路线,即从 2D预训练模型蒸馏出3D信息。
其中影响比较大的工作,包括英伟达在谷歌之后没多久推出的AI工具 Magic3D,虽然技术路线相似,但对其进行了进一步的改良,提升了其质量。
国际图形学年会(SIGGRAPH)2023年最佳论文提出了可替代NeRF的新的表达方式——3DGS(高斯喷射),渲染速度、生成质量等各方面都好于NeRF,并在3D重建方面价值提升明显,只是无法转成质量较好的mesh。而整个3D产业基于 mesh为基础单位发展至今,软硬件及引擎都只能编辑 mesh,由此形成了一定限制。
2
多头问题何解?
基于3D原生数据的大模型
从2D升维至3D,大模型跟人类一样,观察了足够多的平面,可以意识到它的3D状态。
在每一个角度看、即在每一个2D平面上,我们都能看到一个完整的物体切面,但是当这块粘土以此被捏成3D状态时,这种方法最大的问题便是——AI生成的3D对象有多个头或者多个面,多头问题也即雅努斯问题(Janus Problem)。

由于ProlificDreamer缺乏3D形状一致性而出现的雅努斯问题。左边是一只看似正常的蓝鸟的正面视图。右边是一幅令人困惑的图像,描绘了一只有双面的鸟。
为了能够实际应用到内容制作中,理想的3D生成模型应当满足以下要求:
(a)有能力生成具有几何细节和任意拓扑的形状。
(b)输出的应该是纹理网格,这是Blender和Maya等标准图形软件所使用的主要表达。
3D模型必须具备从不同角度看物体形状的一致性,才能避免每个正面侧面都正常,变成整体却不正常。
有没有可能,直接用3D原生数据训练3D大模型?
在OpenAI的Sora出现之前,人们普遍使用借用较为成熟的文生图像的方式,希望能用生成二维的图像的方式,再做一些升维的工作,完成视频的生成,也确实曾经取得一些成果。
而Sora的到来则几乎推翻了前人的所有工作——只要将足量的完整视频输入Transformer的架构中进行训练,大模型能够涌现的智能,要远超人类能够为它所做的修修补补。大模型自己学到了原训练数据中的许多内容,在生成视频的时长、多角度拍摄连贯性上,取得了巨大的提升。
正如Sora的技术革新所展示的,虽然图像生成是更为成熟的技术领域,人们习惯从图像生成出发去推导生成其他的形态,实际上,对于要生成的资产进行直接训练,能够让模型获得更大收益。
以Sora而言,直接对视频进行训练,大大提升了其视频内部的帧间一致性。基于图像生成的视频生成,因为训练时没有足够长的时序的信息约束,生成的视频很多时候会出现闪烁的问题,无法确保基础物理法则的一致性,视频长度也无法保证。而直接以视频作为单位进行训练,虽然需要消耗更大的计算资源,则能直接规避这个问题。
“3D原生派”直接在ShapeNet等3D数据集上进行训练,从训练到推理都基于3D数据。
NIPS在 2016 年提出3D-GAN ,即计算机视觉领域主导模型之一GAN的3D版本,以 voxel 为单位,生成3D模型。
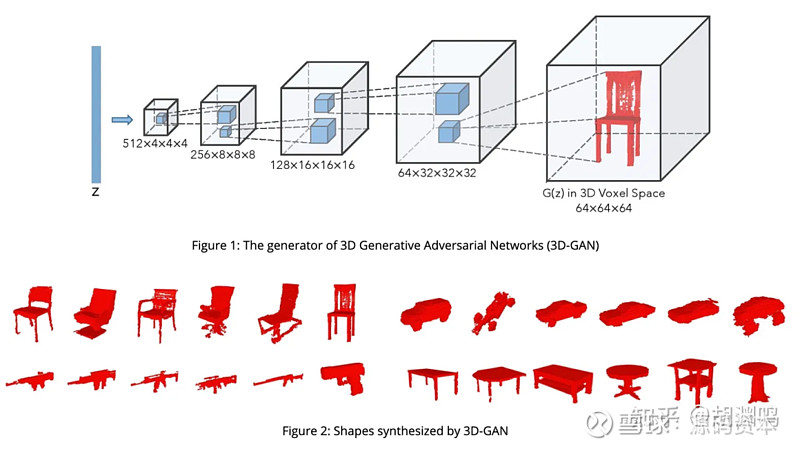
3D GAN 的原理和生成效果
2022 年,英伟达发布GET3D架构:核心是通过可微分表面建模、可微分渲染以及2D生成对抗性网络,可以从2D图像集合中训练模型,直接生成具有复杂拓扑、丰富几何细节和高保真纹理的显式纹理3D网格。

GET3D生成模型(来源:GET3D论文官网网页链接)
OpenAI在2023年5月,推出3D原生数据训练的文生3D模型Shap·E,但是效果距离3D领域追求的Production-Ready还有距离。
用3D原生数据训练大模型,问题显而易见:3D的数据集(ShapeNet 有 51 K 模型、Objaverse 有 800+K、商业模型网站 SketchFab 有 5M)和 2D的 LAION 的5B数量级的数据差了至少三个数量级,且因为3D数据天然的稀缺性、收集的难度,也难实现数据多样性。数据的限制让研究人员普遍认为很难在此基础上训练出足够好的大模型,在特定领域有效,但泛化性受限。
是否有办法增强模型泛化性?当前有团队的实践是,尝试把万物的3D形态都编码到同一种表达上,也就是进行tokenize,再传入模型训练,据了解,结合与Sora相同的Diffusion Transformer架构,没有任何2D先验的原生3D大模型,已在泛化性上有较好表现。

大模型CLAY
3
数据问题一定要解决吗?
2D升维的新进展
2023 年 7 月,来自UCSD等机构的研究者发布了One-2-3-45,摆脱了逐物体优化的生成范式,能够在45秒内将任何单一的2D图像转化为3D效果。
首先,他们使用一个特殊的模型(视图条件的2D扩散模型)来从原始的2D图片生成多个不同角度的2D图像。这就像是从不同的角度看同一个物体。然后,他们使用一个基于SDF(有符号距离函数)的神经网络模型,根据这些多视图图像来构建出3D模型。这就像是将这些不同角度的2D图像"堆叠"起来,形成一个完整的3D形状。
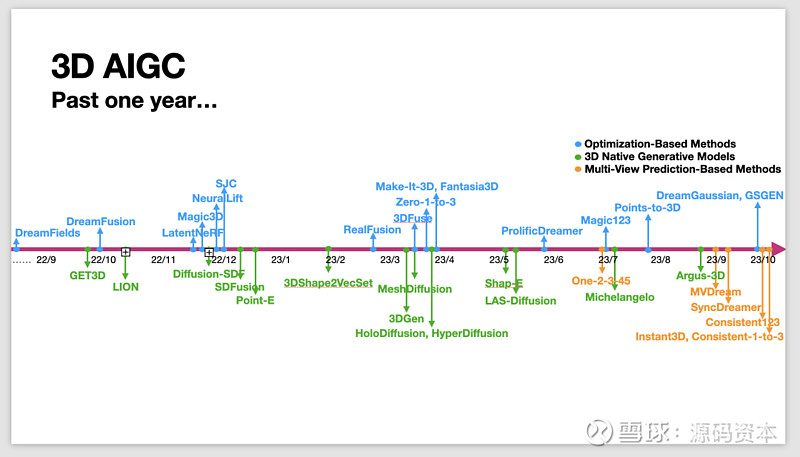
过去一年涌现的大量3D AIGC工作
与其他现有的2D升维方法相比,这种方法有几个优点:
●速度快:它可以在很短的时间内生成3D模型,比其他方法快很多。
●几何形状好:生成的3D模型的形状更接近真实物体的形状。
●3D一致性好:从不同角度看,生成的3D模型的外观更一致。
●紧密遵循输入图像:生成的3D模型更准确地反映了原始2D图片的内容。
与单纯依靠3D原生数据的方法相比,这种方法通过利用2D模型的先验知识,具有更强的泛化性,能够不受有限的3D训练数据的影响,生成更多种类,更加多样的3D模型。
受此启发,学术界大量工作开始遵循这一新生成范式。近期不少研究专注于利用2D扩散模型来生成一致的多视角图像,或训练3D网络从多视角图像生成3D模型。
One-2-3-45团队也在2023年11月发布了新工作One-2-3-45++,实现了更高精度的几何和纹理生成。
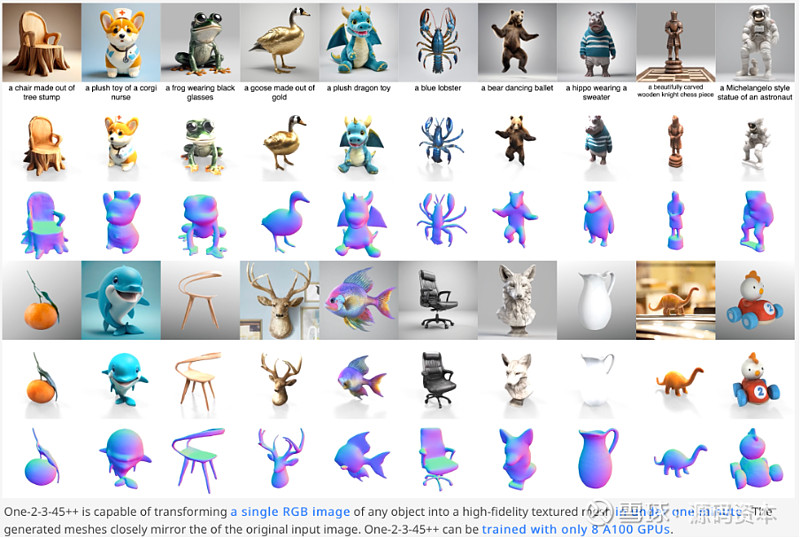
图片来源: 网页链接
2023 年 11 月,Adobe Research和澳大利亚国立大学(ANU)联合研发的人工智能模型宣布了新算法,该算法采用了名为LRM(Large Reconstruction Model)的高度可扩展神经网络,包含一百万数据集和五亿参数,涵盖图像、3D形状和视频等多种数据。
LRM通过采用大规模数据和高容量模型的组合,实现了从单张图像到3D模型的快速而准确的重建。
项目页面:网页链接
这两项研究,推动了2D升维派的技术升级。在2D和3D的联合训练模型绕开了3D原生数据问题。
4
Production Ready 的距离
大模型的技术能力在过去一两年进展飞速,而其中一个令人诟病的点,在于模型能力虽然飞速发展,展现出惊人的潜力,但AI应用的商业化,却并没有人们想象地那么快。
很多应用,如文生图,虽然效果出众,C端用户玩的热闹,但是并没有非常快地渗透到专业的生产管线中产生价值。
而这样的情形,如果在3D生成领域复制的话,对于创业公司可能是致命的。
目前B端的3D模型使用主要分为两个大类:一个是在工业设计方面。3D模型直接服务于设计和生产,在这种工业流程中,对于3D模型的各方面的要求,都需要非常精确。因为生产出来,是真的需要能够严丝合缝地贴合在一起。
所有的人工智能生成技术,目前都很难控制精准生成,以目前的3D生成技术,想在这个方面达到可用,都还比较难,商业化相对也较为遥远。
而另一个大类,是艺术创作方面,即包括对游戏的角色、背景等的建模。在这个领域,精确性的要求相对于生产更低,是目前比较可能进行商业化的路线。
不过,以目前的3D模型的生成精度,直接生成成品,替代掉原有稳定的人工生成,还比较难。模型表面的面片设计是否光滑对称、模型能否具备可驱动的能力等等都是目前的3D模型无法直接提供成品的障碍之一。
而3D模型生成服务能不能进入游戏设计管线?
目前看来是可以的,但也仍然面临困难。
正常游戏中的建模,人的头发、人的脑袋、人的衣服、鞋都是分开建模,但目前的算法还很难做好,而且AI对于3D模型的生成质量其实距离专业人士建模水平还有较大距离,AI对生产管线引入带来的价值究竟有多大?
在游戏生产中,目前比较可行的一个方案是,为游戏、动画的背景填充提供素材。目前多个团队都已经与影视、游戏等厂商展开了相关的合作。
在一个动画场景中,其实除了主要人物的建模外,还存在大量的背景物品建模。比如可能一个主人公站在桌子前,而桌子上摆满了很多瓶瓶罐罐。这些瓶瓶罐罐每一个实际上都需要建模,而如果全部用人工进行这样的操作,十分费时。
具体的合作中,3D建模团队直接从博物馆拍摄了很多动画所需的素材,用模型生成了对应的3D模型,并对其模型的API调用收费。
不过这样的商业模式是否能走向规模化,还是取决于技术的成熟度。3D生成的技术路线,目前还远远没有到一个收敛到同一技术路线的阶段。
整个基础模型的水平,类比图像生成,可能还在MidjourneyV3-V4的状态,因此模型的竞争还会至少持续一年。之后可能才是比拼应用侧的包装,个性化内容生成的竞争。
3D数据如何tokenize,模型训练数据量的大小,后期的材质生成,都是一些3D模型生成需要卷的问题。
不过,也是正因如此,国内外AI 3D模型方面,技术差距并不大。
5
3D到底有什么用?
人类对内容的消费,经历了文字、图片、音乐、短视频、电影等多种内容形式的发展,然而到了如今,如果你有 30 分钟,你会选择打开抖音,还是打开王者荣耀,还是打开一本书?
无关对错好坏,人类对内容的主流消费,始终是往单位时间内信息密度更高的方向发展。在同样的时间里,短视频或者游戏的信息密度远远大于一本书。
如果我们要追逐一个更高单位信息密度的内容形式,那也许就是3D——这就是为什么元宇宙、XR曾如此激发市场热情。
普通人如何在视觉端感知3D内容?或许我们需要与3D信息产生视觉之外的交互,这一点有赖于终端设备的变革。以手机为最主要的终端设备,当前的内容形式已经走到了尽头。XR设备能在多大程度替代手机,3D就能在多大程度上替代当前的内容形式。从这个意义上讲,Apple Vision pro是苹果公司打开并定义未来的硬件设备。
我们现在用文字写日记、用照片记录珍贵时刻、用短视频记录生活,未来或许我们将进入用3D信息记录场景的时刻。
这会是多大的市场?有3D产业人士向我们进行了测算:当前 UE 引擎的用户数+Unity的用户数+Blender 的用户数≈3D 市场用户。排除同时使用多个软件的人,这样的3D模型的使用者,大概为1000万到2000万人。
但是长远来看,如果真的有3D成为人类生活主要内容消费形式的那一天,当前的2D创作者或许都将变成3D创作者。这中间的增量是多少呢?大约15个亿。那看起来是距离现在还很远的未来,那个时候,我们的生活场景可能都已经发生了巨大变化。但让我们怀抱期待。




