

藏在边缘大模型落地背后的六边形战士,揭秘芯动力科技硬核杀手锏。
作者 |程茜
编辑 |漠影
就在前天,国内最高规格的AI产业盛会第七届世界人工智能大会(WAIC 2024)开幕,展区已成“大模型”主场,各路玩家隔空斗法。
既有闻名业界的通用大模型大秀生成、理解能力,在金融、医疗等诸多领域施展拳脚的行业大模型,还有能直接部署在PC、服务器等边缘设备的端侧大模型效果惊艳。
可以看到从去年至今,大模型产业的发展焦点正在从技术突破向落地应用外延。一方面,通用大模型表现惊艳,另一方面,距离用户更近且性能已经足够强大的端侧大模型呈现出规模化应用潜力。
在这之中,随着技术的成熟和应用场景的拓展,端侧大模型市场已经成为AI领域的一个重要增长点,而端侧大模型走向落地部署背后的一个关键角色就是底层芯片玩家。

WAIC上,一家清华系GPGPU创企的展台上,我们看到其AI加速卡AzureBlade K340l已经可以支撑大模型跑在AI PC等设备上,并已经适配Llama 3-8B、Stable Diffusion、通义千问等开源模型。
这家创企的技术实力不容小觑。本月初,芯动力科技团队联手帝国理工、剑桥大学、清华大学、中山大学等顶尖学府的计算机架构团队,共同撰写的论文《Circular Reconfigurable Parallel Processor for Edge Computing》(RPP芯片架构)成功被第51届计算机体系结构国际研讨会(ISCA 2024)的Industry Track收录。
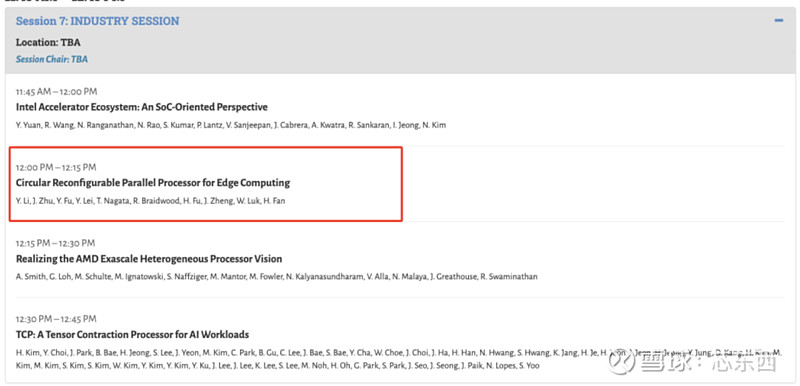
据了解,Industry Track的录取接收率仅为15.3%。同时,芯动力科技还受邀在ISCA 2024会议上发表演讲,与Intel、AMD等国际知名企业同台交流。

在WAIC上,我们可以看到以芯动力科技为代表的国内AI芯片玩家,已经亮出了诸多技术成果与案例演示,为端侧大模型部署落地装上了加速引擎。
01.
“六边形战士”RPP架构
破局边缘大模型落地
大模型加速落地应用现在已经成为共识,不过通用大模型很难理解企业的真实痛点,让企业真正用上大模型实现降本增效是当前的重中之重。
但相比于面向消费者的AI工具,企业对于大模型能力的要求更高,除了大模型本身的性能表现需要足够优越外,还有更为重要的几点就是数据安全、响应够快,这也是跑在云上的大模型缺少的。
因此边缘大模型脱颖而出,因为边缘设备距离企业的业务或者用户本身距离更近,且能够支持本地私有化部署保证用户的数据安全。与此同时,底层的AI芯片就称为AI落地边缘端的必要条件。
这也导致边缘大模型部署对AI加速卡的特性提出了更高要求。因为边缘端往往只有一个独立设备,因此就需要芯片需要同时兼顾体积小、性能强、功耗低。当下Llama系列、通义千问等开源模型,已经在较小的参数规模下达到了较好的性能,能够实现很好的文升文、文生图效果。这也为大模型在端侧落地提供了机会。
还有更为重要的一点是,大模型的技术突破仍在不断革新。为了让大模型在资源有限的设备上部署,大模型量化部署精度正在从8bit向4bit支持,大模型的快速演变对芯片研发的长周期,大投入提出了不小的挑战。
这些难题在对芯片的性能及灵活性提出不小挑战的同时,也是大模型落地的必要条件。对于众多专用芯片来讲,这意味着需要开展全新的芯片设计工作,而对芯动力科技可重构并行处理器架构(RPP)来讲,则仅需进行一次软件开发即可。在面对边缘大模型落地所面临的难题时,芯动力科技的RPP架构展现出其固有的天然优势。
在生成式AI日新月异的应用场景中,唯一不变的就是变化本身。芯动力构建的通用性生态决定了,未来若出现除Transformer以外的新型算法基底,RPP架构将能够迅速完成算法的兼容与优化,而无需改变硬件架构。这使得RPP架构拥有更持久的生命力和更广阔的市场前景。
RPP架构是针对并行计算设计的芯片架构,芯动力将其称作“六边形战士”。这一架构既结合了NPU的高效率与GPU的高通用性优势,更具备DSP的低延时,可满足高效并行计算及AI计算应用,如图像计算、视觉计算、信号处理计算等,大大提高了系统的实时性和响应速度。
芯动力首款基于可重构架构的GPGPU芯片RPP-R8每颗芯片内含有1024个计算核,相比传统GPU架构在同样的算力占用更小的芯片面积,实现了低功耗和高能效的有效平衡。RPP-R8除了具备专用芯片所没有的通用编程性,面积效率比可达到同类产品的7~10倍,能效比也超过3倍。

除了芯片本身外,芯动力科技还会为企业提供相应的软件帮助其部署集成。
02.
文图生成+安防、工业、医疗
让AI在边缘端大展拳脚
相比于云端大模型,端侧大模型能够根据用户的行为和偏好提供更加个性化的服务,极大提升用户体验。一方面端侧大模型性能水平直追云端,另一方面参数规模小的端侧大模型部署成本正不断降低。
因此,WAIC展区内单纯展现通用大模型本身性能表现的厂商少之又少,更多是丰富的行业应用、创新工具等。这也使得大模型落地应用的场景,以及有哪些惊艳的效果成为WAIC的重点。
单在芯动力科技一家的展区里,就可以看到边缘大模型的文生文、文生图、泛安防、机器视觉、医疗影像等诸多演示案例。
面向边缘大模型市场潜力急速增长的背景,芯动力科技已经构建起了丰富的产品体系。其中,在RPP架构的加持下,芯动力科技AzureBlade K340l中集成的芯片AE7100,以17mmx17mm的面积大概半张名片的大小就实现了32 TOPs的算力与60GB/s的内存带宽。

▲芯动力科技AzureBlade K340l
同时,这一加速卡采用完全可编程设计,兼容CUDA+ONNX,已经可以广泛应用于AI PC、机器视觉、泛安防、医疗影像等诸多领域。
基于AzureBlade K340l,芯动力科技现场演示的AI PC适配了通义千问的7B模型,在文生文的演示中,文字对话的生成速度很快,能满足基本的办公、生活需求。
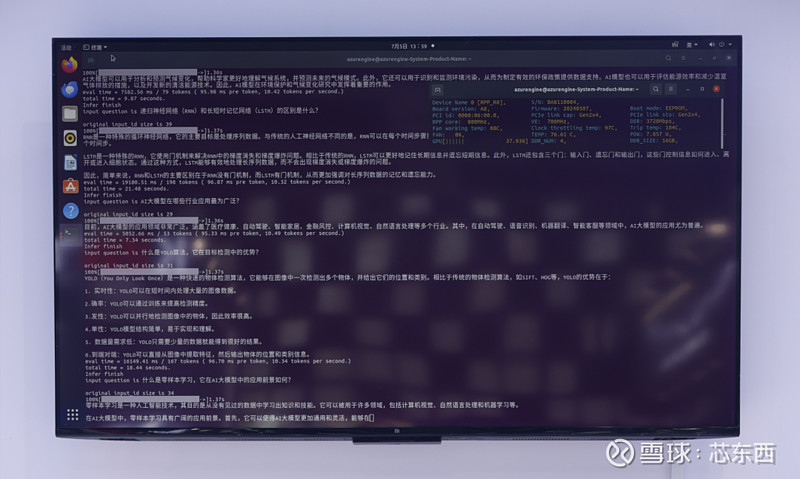
在文生图演示中,现场基于加速卡适配的是Stable Diffusion模型,因此仅支持英文输入,据现场工作人员介绍,目前文生图的平均生成速度在12s左右。当输入“生成一张含有帅气男子的海报”,模型仅用了将近10s的时间就很好消化了提示词中的元素。
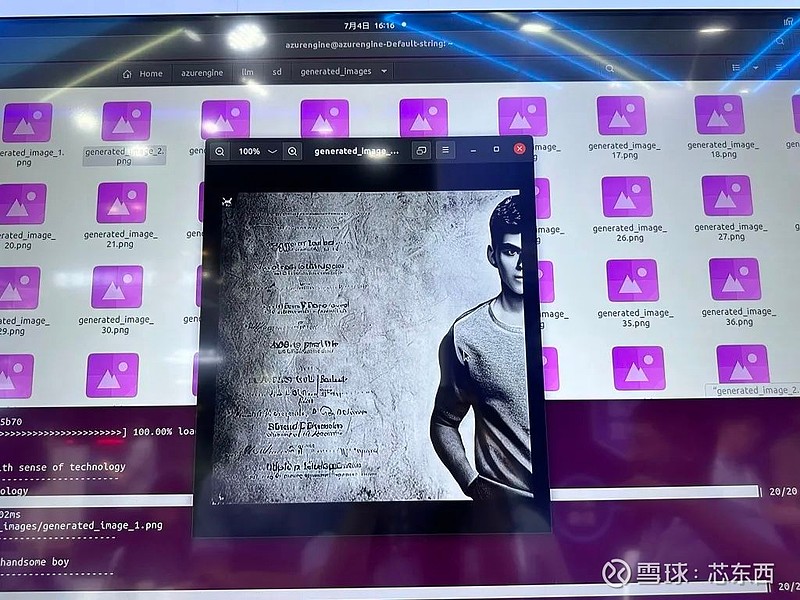
除了这些边缘大模型部署,芯动力科技在泛安防领域实现了姿势检测,据工作人员介绍,芯动力科技的芯片可以应用于养老院场景中,老年人摔倒预防等,可以基于摄像头的姿态识别能力快速检测出是否有老人摔倒并联动采取措施。

在机器视觉、信号处理、医疗影像领域,芯动力科技的芯片可以用于瑕疵判断以及医疗图像增强等。
此前,工业场景下的工业器件瑕疵检测往往依靠大量人工通过肉眼识别,这不仅效率低下且消耗了大量的人力物力。基于AI机器视觉不仅可以加速这一流程,且识别结果能更加精准。
在医疗影像方面,基于机器视觉可以增强患者的影像图片效果,帮助医生快速进行判断。
面向边缘大模型部署以及边缘设备的智能化升级,芯动力科技已经形成了芯片、AI加速卡、边缘服务器等全套产品体系,为边缘市场的爆发提供强劲的动力。
03.
边缘大模型战事正酣
芯动力科技瞄准下一增长点
即便当下端侧大模型的性能等已经呈现出实际应用的能力,但芯动力科技要做的事远不止于此。
一定程度上,参数规模越大大模型所呈现出的效果更好。因此,在边缘设备上部署的大模型参数规模未来也会有继续增长的可能。
另一方面,如今图片、音频、视频、3D等多模态大模型层出不穷,这些能力对于用户而言也至关重要,因此边缘大模型的部署不会满足于简单的文生文、文生文。
还有更多创新算法的出现,都会对芯片本身的灵活性、适配性提出更高的要求。
因此,始终坚持与边缘端设备企业协同突破的芯动力科技率先看到了这些挑战,并正在以RPP架构这一“六边形战士”为核心持续突破技术瓶颈。
大模型、创新算法层出不穷,RPP架构天然拥有的通用性优势,能够让芯动力科技更快支持新算法。对于大模型在边缘端落地,性价比高、功耗低、成本可控、灵活度高缺一不可,而恰好RPP架构都能满足。
与此同时,芯动力科技还有一大差异化优势就是,能与边缘端的设备玩家持续协同优化芯片、软件,以跟得上大模型产业的迭代速度。
这背后也会反推用户进一步看到大模型的实际价值。随着边缘大模型在设备上的落地增多,真正落地的步伐加快,使得用户的付费意愿增强,进一步有了商业化、规模化应用的潜力。
对于芯动力科技而言,他们看到了企业在边缘大模型上加速推进产品的决心。边缘企业对于大模型的看法已经发生变化,从让大模型跑起来到如何真正实现商业化演进。
因此,一方面,芯动力科技专注于边缘大模型的落地应用,另一方面也关注到了边缘端设备的智能化升级演进,也就是既看到潜力绝大的市场,也关注需求旺盛但产业发展仍处于初期的玩家。
眼光以及目标都更加长远的芯动力科技,站在大模型产业突飞猛进的当下,已经找到了自己的正确站位,以更高性价比的方式让大模型在边缘端的价值被释放出来,同时也向后看到了下一个边缘设备市场的爆发点。
04.
结语:边缘大模型崛起
芯动力科技已先行一步
国内AI大模型的研发虽然起步较晚,前沿技术相比国外有一定差距,但在应用落地端,国内进展已经风起云涌。物流、金融、医疗等行业都开始探索大模型的深度应用。
更靠近数据源、能实现更快响应和更低延迟的边缘大模型出现了越来越多的技术演进和创新突破,其面临的功耗、成本等诸多难题正在被以芯动力科技为代表的玩家逐一击破。
目前,边缘大模型规模化落地的潜力已经凸显,芯动力科技的产品布局已经初见成效。伴随着这一领域的技术进步与行业需求增长,率先出手的芯动力科技能够抢占先机,找到大模型深入行业的更大价值。