正态分布,也称为高斯分布(Gaussian distribution),是连续概率分布的一种。它在统计学、自然科学、社会科学、以及工程学等多个领域中都有着广泛的应用。
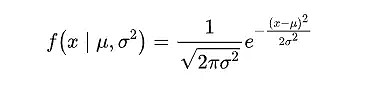
x 是股票或指数的收盘价
μ 是分布的均值,代表分布的中心位置。
σ 是标准差,代表分布的离散程度或分散程度。
正态分布的概率密度函数(PDF)具有一个独特的钟形曲线,其形状由两个参数决定:均值(μ)和标准差(σ)。
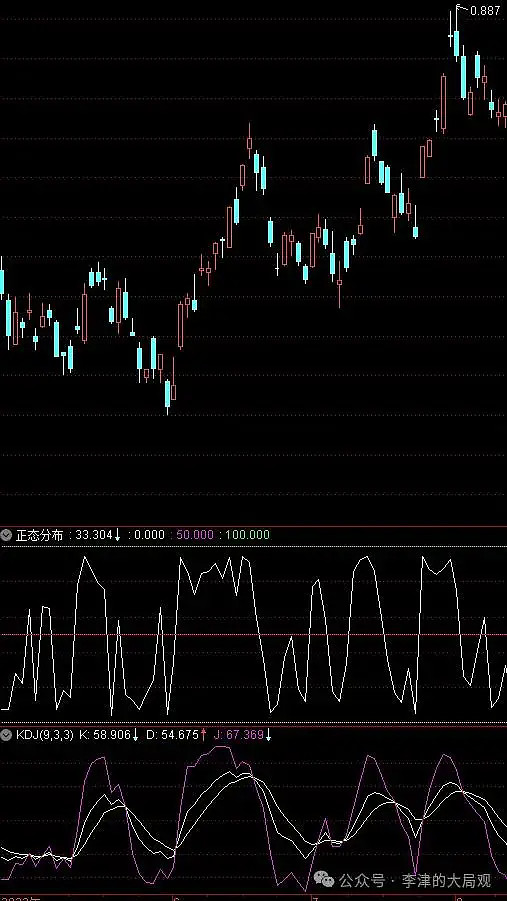
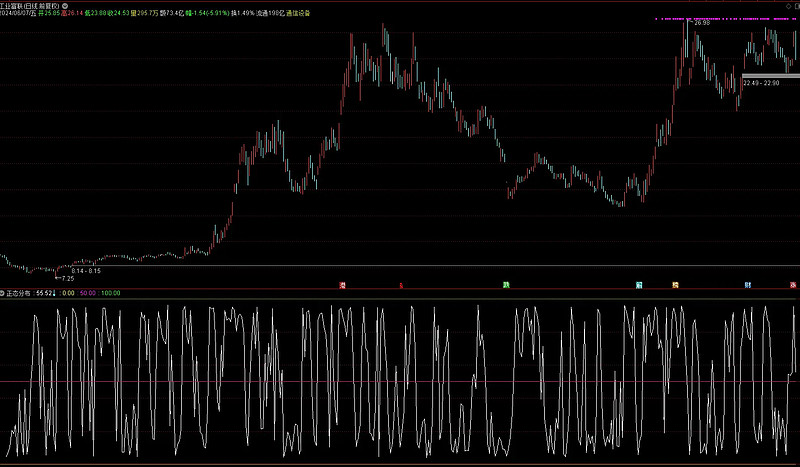
跟KDJ差不多,KDJ估计是以正态分布做拟态的随机算法
public static double normsinv(double p) {
double LOW = 0.02425;
double HIGH = 0.97575;
double a[] = { -3.969683028665376e+01, 2.209460984245205e+02,
-2.759285104469687e+02, 1.383577518672690e+02,
-3.066479806614716e+01, 2.506628277459239e+00 };
double b[] = { -5.447609879822406e+01, 1.615858368580409e+02,
-1.556989798598866e+02, 6.680131188771972e+01,
-1.328068155288572e+01 };
double c[] = { -7.784894002430293e-03, -3.223964580411365e-01,
-2.400758277161838e+00, -2.549732539343734e+00,
4.374664141464968e+00, 2.938163982698783e+00 };
double d[] = { 7.784695709041462e-03, 3.224671290700398e-01,
2.445134137142996e+00, 3.754408661907416e+00 };
double q, r;
if (p < LOW) {
q = Math.sqrt(-2 * Math.log(p));
(((((c[0] * q + c[1]) * q + c[2]) * q + c[3]) * q + c[4])
* q + c[5])
/ ((((d[0] * q + d[1]) * q + d[2]) * q + d[3]) * q + 1);
} else if (p > HIGH) {
q = Math.sqrt(-2 * Math.log(1 - p));
return -(((((c[0] * q + c[1]) * q + c[2]) * q + c[3]) * q + c[4])
* q + c[5])
/ ((((d[0] * q + d[1]) * q + d[2]) * q + d[3]) * q + 1);
} else {
q = p - 0.5;
r = q * q;
return (((((a[0] * r + a[1]) * r + a[2]) * r + a[3]) * r + a[4])
* r + a[5])
* q
/ (((((b[0] * r + b[1]) * r + b[2]) * r + b[3]) * r + b[4])
* r + 1);
}
}
这段代码名为normsinv,用于计算标准正态分布的逆累积分布函数(Inverse Cumulative Distribution Function,ICDF)。这个方法接受一个介于0和1之间的概率值p,并返回该概率对应的标准正态分布的分位数(即随机变量的值,使得累积概率小于或等于p)。这个方法使用了一种称为“Box-Muller”方法的变体来计算逆累积分布函数。
68-95-99.7规则:在正态分布中,大约68%的数据值落在均值的一个标准差范围内(μ±σ),95%的数据值落在两个标准差范围内(μ±2σ),而99.7%的数据值落在三个标准差范围内(μ±3σ)。