本文全文共 6488 字,阅读全文约需 16 分钟

01 大模型AI时代到来
发布针对 AIGC 训练 GPU,英伟达掀起 AI 服务器芯片市场争夺
围绕生成式人工智能,英伟达发布一系列加速模型训练和推理的软硬件新品。
2023 年 3 月 22 日,英伟达在 GTC 大会上发布一款新的 GPU——带有双 GPU NVLink的 H100 NVL,以支持 ChatGPT 类大型语言模型推理。基于 NVIDIA Hopper 架构的H100 配有一个 Transformer 引擎,H100 NVL 拥有 188GB HBM3 内存(每张卡 94GB),是目前英伟达发布的内存最大的显卡。与用于 GPT-3 处理的 HGX A100 相比,配备四对 H100 与双 GPU NVLink 的标准服务器的速度最高可达 10 倍。

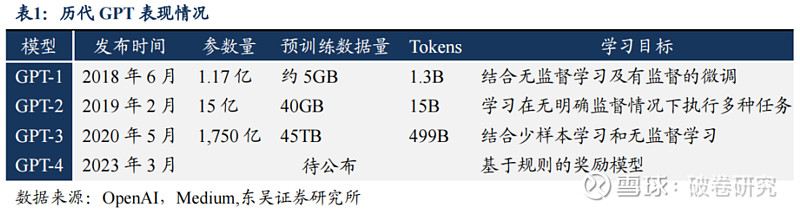
GPT 升级至四代,模型能力高速提升,对数据中心算力提出更高要求。从 2018 年起,OpenAI 开始发布生成式预训练语言模型 GPT,当时参数量只有 1.17亿个。2020 年,OpenAI 发布 GPT-3 预训练模型,参数量为 1750 亿个,使用 1000亿个词汇的语料库进行训练,在文本分析、机器翻译、机器写作等自然语言处理应用领域表现出色。2022 年 12 月,OenAI 发布基于 GPT-3.5 的聊天机器人模型ChatGPT,具有出色的文字聊天和复杂语言处理能力。从运算规格来看,ChatGPT主要以 NVIDIA A100 为主,独家使用 Microsoft Azure 云服务资源。2023 年 3 月 15 日,OpenAI 正式官宣了多模态大模型 GPT-4,ChatGPT4 将输入内容扩展到 2.5 万字内的文字和图像,较ChatGPT 能够处理更复杂、更细微的问题。
人工智能芯片主要分为“训练(Training)”芯片和“推理(Inference)”芯片。“训练芯片”主要用于人工智能算法训练,即在云端将一系列经过标记的数据输入算法模型进行计算,不断调整优化算法参数,直至算法识别准确率达到较高水平。“推理芯片”主要用于人工智能算法推理,即将在云端训练好的算法模型进行裁剪优化变“轻”之后,进入“实战”阶段,输入数据直接得出准确的识别结果。
➢ 训练芯片:通过大量的数据输入,构建复杂的深度神经网络模型的一种AI芯片。需要较高的计算性能、能够处理海量的数据、具有一定的通用性,以便完成各种各样的学习任务,注重绝对的计算能力。
➢ 推理芯片:推断芯片主要是指利用训练出来的模型加载数据,计算“推理”出各种结论的一种AI芯片,注重综合指标,侧重考虑单位能耗算力、时延、成本等性能。

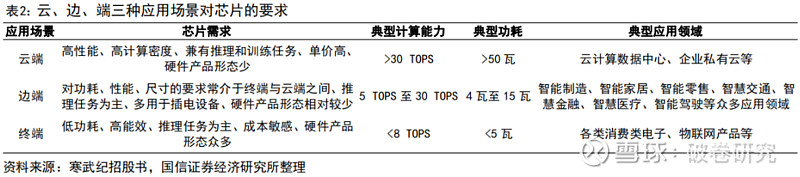
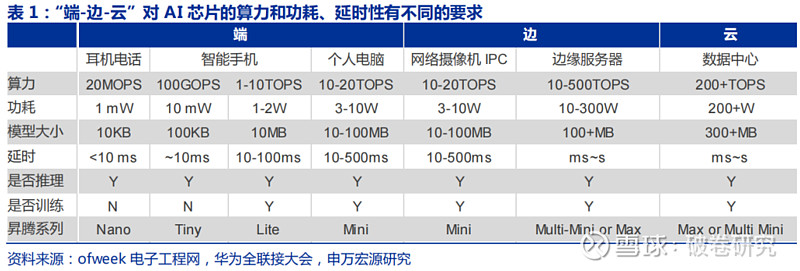
不同用途(训练 or 推理)、不同应用场景(云-边-端)对 AI 芯片有着不同的要求。首先,训练芯片追求的是高计算性能(高吞吐率)、低功耗,但是推理芯片主要追求的是低延时(完成推理过程所需要的时间尽可能短)、低功耗。目前,“云、边、端”应用场景尚无标准划分界,人工智能技术在云、边、端设备中均有广泛应用,不同应用场景对芯片算力和功耗要求亦不相同。其中,数据中心侧对芯片要求更高,一般要求具有高性能、高存储容量、高计算密度、兼有推理和训练任务的特点,训练过程对时延没有什么要求,因此需要保证 AI 芯片在尽可能保证较高算力的情况下,功耗尽可能低,其典型计算能力大于 30TOPS,典型功耗大于 50瓦,主要应用于云计算数据数据中心等领域;端和边上进行的大部分是 AI“推理”,因此用于端和边的 AI 芯片性能要求和上述推理芯片一致。
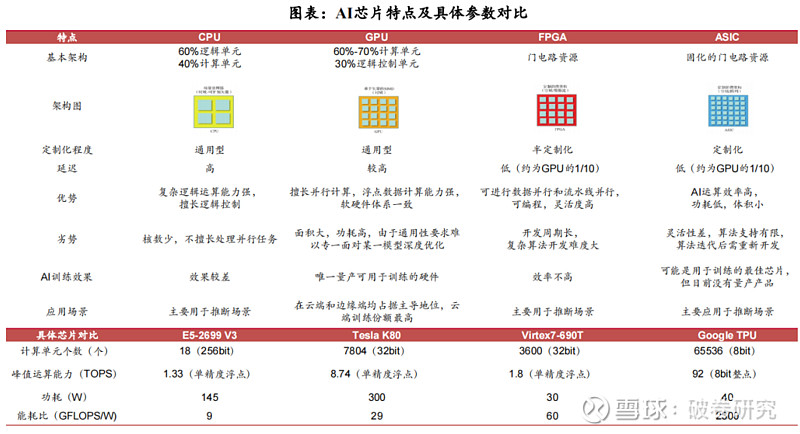
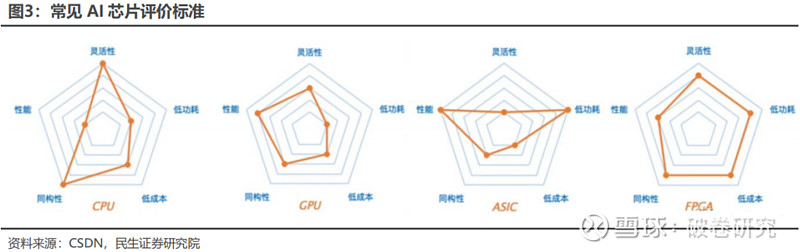
目前用于人工智能深度/机器学习的芯片主要有 GPU、FPGA、ASIC 三类芯片。三类芯片用于深度学习时各有优缺点:(1)通用性:GPU>FPGA>ASIC,通用性越低,代表其适合支持的算法类型约少。(2)性能功耗比:GPU<FPGA<ASIC,性能功耗比越高越好,意味着相同功耗下运算次数越多,训练相同算法所需要的时间越短。
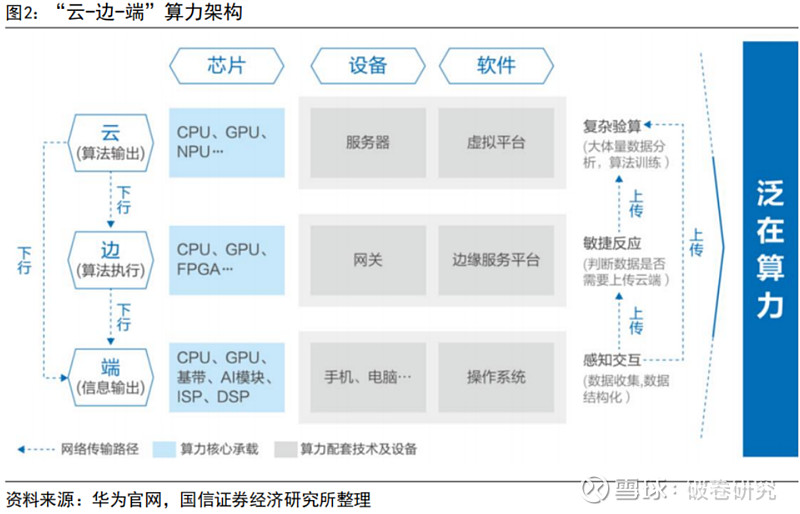
“云-边-端”高算力网络基本形成,通过构建泛在部署架构满足大算力需求。云端智能芯片及加速卡是云服务器、数据中心等进行人工智能处理的核心器件,算力由 GPU、NPU 等芯片产生,通过虚拟平台调度服务器设备进行复杂数据处理,支持高复杂度和数据吞吐量高速增长的人工智能处理任务。边缘计算在终端和云端之间的设备上配备适度的计算能力,算力由 CPU、FPGA 等芯片产生,可解决云计算场景下数据安全、隐私保护、带宽与时延等潜在问题,保障数据传输的稳定性和低延时性。终端智能处理器是终端设备中支持人工智能处理运算的核心器件,算力主要由 CPU、DSP 等芯片产生,使终端设备拥有更流畅的用户体验。
全球数据总量及数据中心负载任务量大幅度上涨,服务器算力需求呈指数级增长。随着人工智能、数据挖掘等新技术发展,海量数据产生及对其计算和处理成为数据中心发展关键。据 IDC 数据,全球数据总量预计由 2021 年的 82.47 ZB 上升至 2026 年的 215.99 ZB,对应 CAGR 达 21.24%。其中,大规模张量运算、矩阵运算是人工智能在计算层面的突出需求,高并行度的深度学习算法在视觉、语音和自然语言处理等领域上的广泛应用使得算力需求呈现指数级增长。据 Cisco 数据,全球数据中心负载任务量预计由 2016 年的 241.5 万个上升至 2021 年的 566.7万个,对应 CAGR 达 18.60%;其中,云数据中心负载任务量 CAGR 预计达 22%。
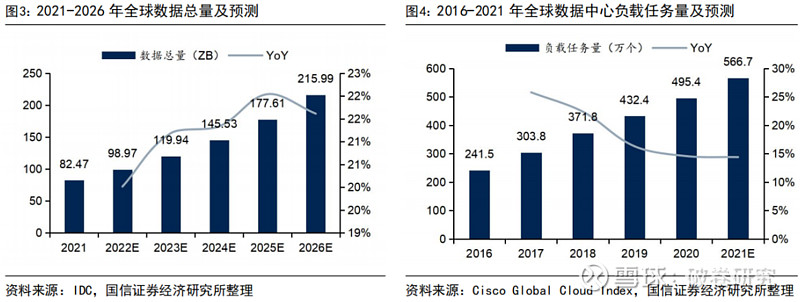
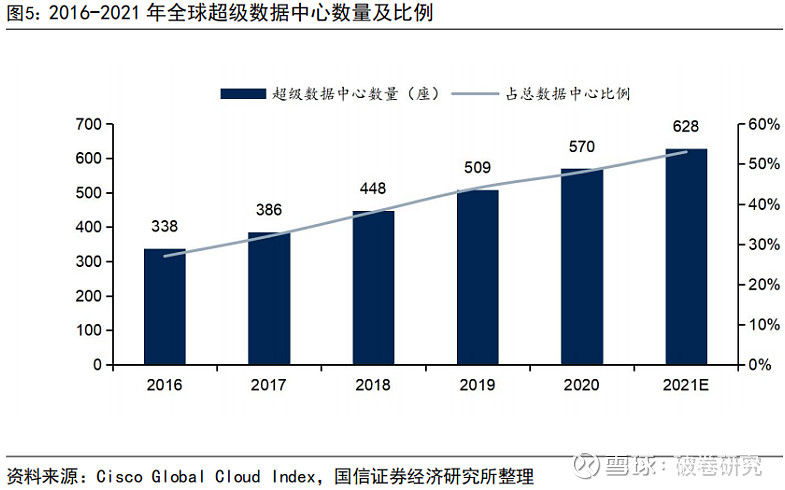
随着云计算的不断发展,全球范围内云数据中心、超级数据中心的建设速度不断加快。据 Cisco 数据,全球超级数据中心数量预计由 2016 年的 338 座增长至 2021年的 628 座,对应 CAGR 为 13.19%;占数据中心比例预计由 2016 年的 27%上升至2021 年的 53%。在云端,服务器及数据中心需要对大量原始数据进行运算处理,对于芯片等基础硬件的计算能力、计算进度、数据存储和带宽等都有较高要求。传统数据中心存在着能耗较高、计算效率较低等诸多发展瓶颈,因此数据中心中服务器的智能化将是未来发展趋势。
边、终端数据创建占比预计 25 年达到 60%以上,AI 需求下沉扩大市场空间。根据 IDC 预测,2025年64%的数据将在传统数据中心之外创建,意味着更智能的处理将在设备上完成,而 5G 将使来自边缘丰富的数据实时地与其他设备和云共享。互联智能边缘的出现正在加速应用创新的需求,高通预计未来十年内公司潜在的市场扩大七倍多,达到 7000 亿美元。云计算与边缘计算需要通过紧密协同才能更好地满足各种需求场景的匹配,从而最大化体现云计算与边缘计算的应用价值。

AI 芯片又称 AI 加速器或计算卡,是专门用于处理人工智能应用中大量计算任务的模块。随着数据海量增长、算法模型趋向复杂、处理对象异构、计算性能要求高,AI 芯片能够在人工智能的算法和应用上做针对性设计,高效处理人工智能应用中日渐多样繁杂的计算任务。
算力芯片等硬件基础设施是处理数据“燃料”的“发动机”,只有达到一定水平的算力性能才能实现人工智能的训练和推断以及存储、传输等相关配套功能。人工智能的云端训练和推断计算主要基于AI服务器,对算力/存力/运力/散热性能要求更高,带动算力芯片、配套硬件、机箱等设施不断升级。
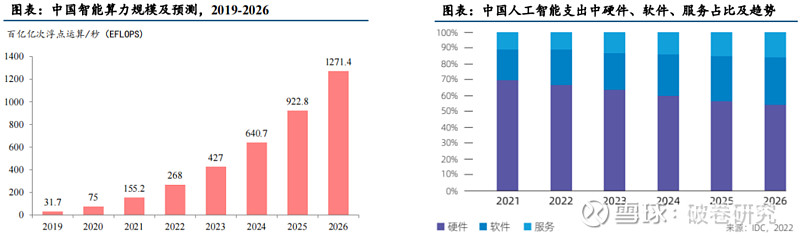
中国智能算力规模正在高速增长,算力芯片等硬件基础设施需求旺盛。根据IDC数据,2021年中国智能算力规模达155.2 每秒百亿亿次浮点运算(EFLOPS),2022年智能算力规模将达到268.0 EFLOPS,预计到2026年智能算力规模将进入每秒十万亿亿次浮点计算(ZFLOPS)级别,达到1,271.4EFLOPS,2021-2026年复合增长率达52.3%。预计中国人工智能支出中硬件占比将保持最大,未来5年将一直保持65%左右的份额。看好AI大模型训练及推理需求创造的算力芯片等硬件基础设施的增量市场空间。
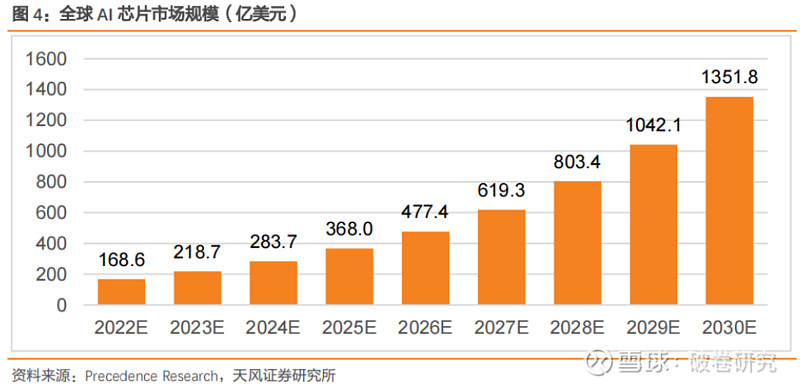
随着人工智能技术进步及应用场景多元化,全球及中国 AI 芯片市场将得到进一步发展。根据 Precedence Research 数据,2022 年全球人工智能 AI 芯片市场规模估计为 168.6 亿美元,预计 2030 年达到 1351.8 亿美元,2022 年至 2030 年的复合年增长率为 29.7%;按照类型可以分为 GPU、ASIC、FPGA、CPU 等,每种芯片类型皆有不同功能;基于处理类型,边缘处理类型细分市场主导 AI 芯片市场,并在 2022 年产生超过 75%的收入份额,由于边缘处理在接近数据实际位置的地方进行计算,最大限度地提高了运算效率。
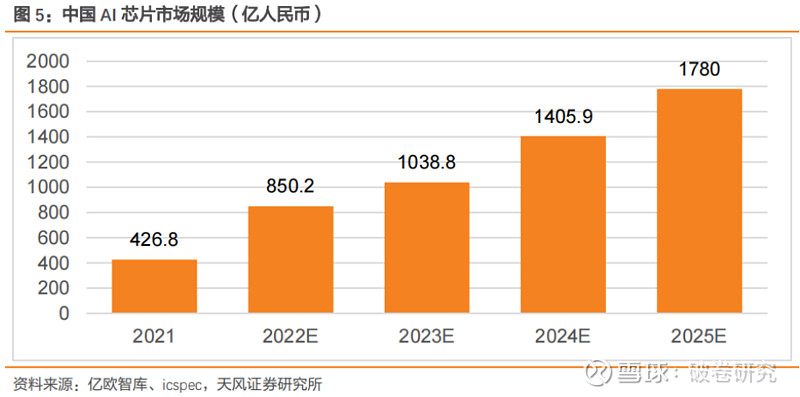
2025 年中国 AI 芯片市场规模预计超过 250 亿美金。随着大算力中心的增加以及终端应用的逐步落地,中国 AI 芯片需求也持续增加。根据亿欧智库预测,2021 年中国 AI 芯片预计达到 427 亿人民币(按 6.9 汇率测算,约 61.8 亿美金),预计市场规模将于 2025 年达到1780 亿元(按 6.9 汇率测算,约 258 亿美金)。
当前主流的 AI 芯片主要包括图形处理器(GPU)、现场可编程门阵列(FPGA)、专用集成电路(ASIC)、神经拟态芯片(NPU)等。
➢ CPU是AI计算的基础,负责控制和协调所有的计算操作。在AI计算过程中,CPU用于读取和准备数据,并将数据来传输到GPU等协处理器进行计算,最后输出计算结果,是整个计算过程的控制核心。根据IDC数据,CPU在基础型、高性能型、推理型、训练型服务器中成本占比分别为32%、23.3%、25%、9.8%,是各类服务器处理计算任务的基础硬件。
➢ GPU、FPGA、ASIC是AI计算的核心,作为加速芯片处理大规模并行计算。具体来看,GPU通用性较强,适合大规模并行计算,且设计及制造工艺较成熟,目前占据AI芯片市场的主要份额;FPGA具有开发周期短、上市速度快、可配置性等特点,目前被大量应用于线上数据处理中心和军工单位;ASIC根据特定需求进行设计,在性能、能效、成本均极大的超越了标准芯片,非常适合 AI 计算场景,是当前大部分AI初创公司开发的目标产品。

评价 AI 芯片的指标主要包括算力、功耗、面积、精度、可扩展性等,其中算力、功耗、面积(PPA)是评价 AI 芯片性能的核心指标:
①算力:衡量 AI 芯片算力大小的常用单位为 TOPS 或者 TFLOS,两者分别代表芯片每秒能进行多少万亿次定点运算和浮点运算,运算数据的类型通常有整型 8 比特(INT8)、单精度 32 比特(FP32)等。AI 芯片的算力越高,代表它的运算速度越快、性能越强。
②功耗:功耗即芯片运行所需的功率,除了功耗本身,性能功耗比是综合衡量芯片算力和功耗的关键指标,它代表每瓦功耗对应输出算力的大小。
③面积:芯片的面积是成本的决定性因素之一,通常来讲相同工艺制程之下,芯片面积越小良率越高,则芯片成本越低。此外,单位芯片面积能提供的算力大小亦是衡量 AI 芯片成本的关键指标之一。
除 PPA 之外,运行在 AI 芯片上的算法输出精度、AI 应用部署的可扩展性与灵活性,均为衡量 AI 芯片性能的指标。
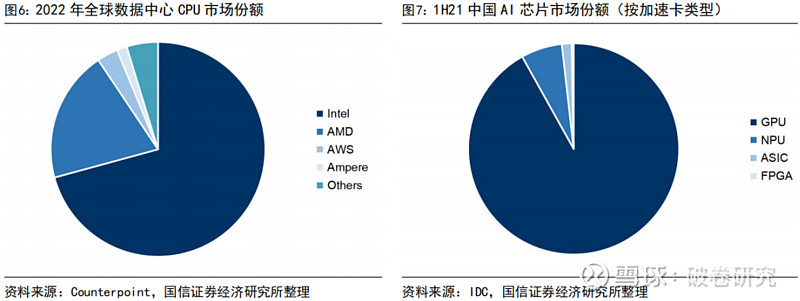
当前 CPU 市场主要被国际厂商垄断,Intel、AMD 合计市场份额超九成。据Counterpoint 数据,2022 年全球数据中心 CPU 市场份额中,Intel 占比达 70.8%,保持市场领先地位;AMD 占比达 19.8%,前两大巨头合计市场份额超过 90%。
GPU 在训练负载中具有绝对优势,未来 AI 芯片将更加细分和多元。据 IDC 数据,1H21 中国 AI 芯片市场份额中,GPU 占比高达 91.9%,依然是实现数据中心加速的首选;NPU、ASIC、FPGA 占比分别为 6.3%、1.5%、0.3%。随着非 GPU 芯片在各个行业和领域中被越来越多采用,高算力、低能耗且适应各类复杂环境的芯片将更受关注,IDC 预计到 2025 年其他非 GPU 芯片整体市场份额占比将超过 20%。
GPU 作为图像处理单元,其能够并行计算的性能优势满足深度学习需求。GPU 最初承担图像计算任务,目标是提升计算机对图形、图像、视频等数据的处理性能,解决 CPU 在图形图像领域处理效率低的问题。由于 GPU 能够进行并行计算,其架构本身较为适合深度学习算法。因此,通过对 GPU 的优化,能够进一步满足深度学习大量计算的需求。
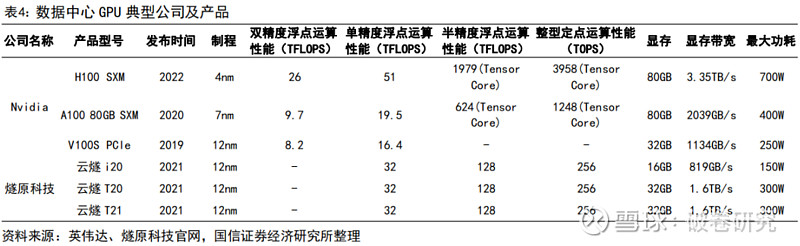
以NVIDIA GPU系列旗舰产品A100为例:根据NVIDIA公布的规格参数,A100的深度学习运算性能可达312Tflops。在AI训练过程中,2048个A100 GPU可在一分钟内成规模地处理BERT的训练工作负载;在AI推理过程中,A100可将推理吞吐量提升到高达CPU的249倍。
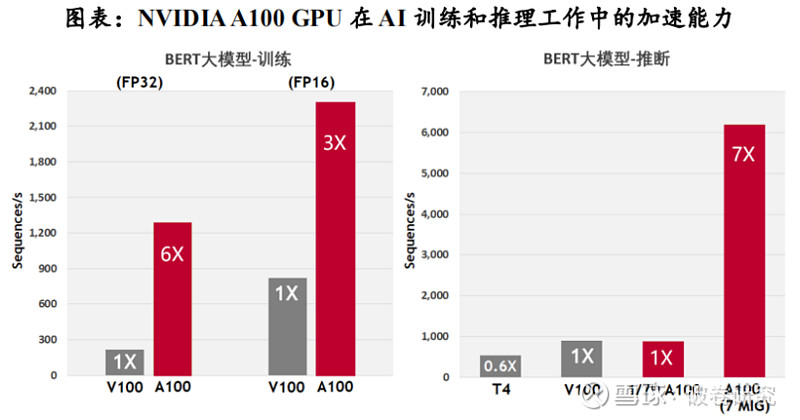
根据Verified Market Research数据,2021年全球GPU市场规模为334.7亿美元,预计2030年将达到4773.7亿美元,CAGR(2021-2030)为34.35%。从国内市场来看,2020年中国大陆的独立GPU市场规模为47.39亿元,预计2027年市场规模将达345.57亿美元,CAGR(2021-2027)为32.8%。
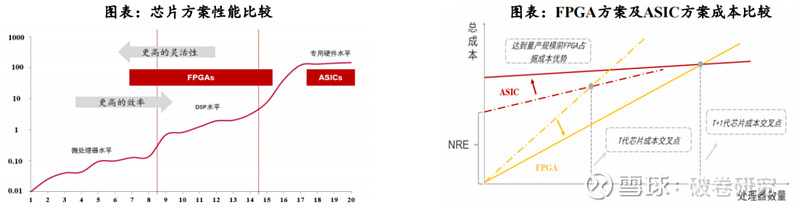
FPGA 是一种硬件可重构的集成电路芯片,通过编程定义单元配置和链接架构进行计算。FPGA 具有较强的计算能力、较低的试错成本、足够的灵活性以及可编程能力,在 5G 通信、人工智能等具有较频繁的迭代升级周期、较大的技术不确定性的领域,是较为理想的解决方案。

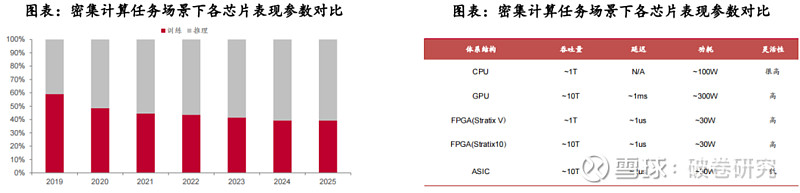
可编程性、高并行性、低延迟、低功耗等特点,使得FPGA在AI推断领域潜力巨大。FPGA可以在运行时根据需要进行动态配置和优化功耗,同时拥有流水线并行和数据并行能力,既可以使用数据并行来处理大量数据,也能够凭借流水线并行来提高计算的吞吐量和降低延迟。根据与非网数据,FPGA(Stratix 10)在计算密集型任务的吞吐量约为CPU的10倍,延迟与功耗均为GPU的1/10。
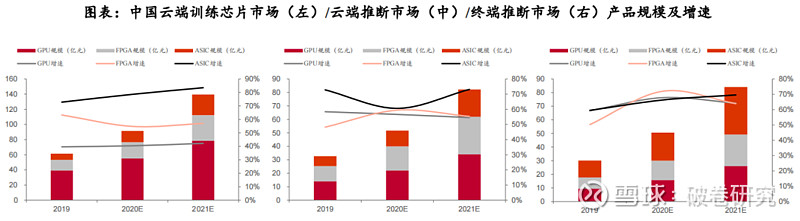
➢ 云端推断:在面对推断环节的小批量数据处理时,GPU的并行计算优势不明显,FPGA可以凭借流水线并行,达到高并行+低延迟的效果。根据IDC数据,2020年中国云端推理芯片占比已超过50%,预计2025年将达到60.8%,云端推断市场广阔。
➢ 边缘推断:受延迟、隐私和带宽限制的驱动,FPGA逐渐被布署于IoT设备当中,以满足低功耗+灵活推理+快速响应的需求。
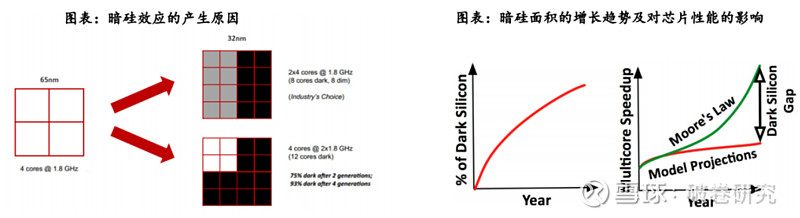
FPGA是AI时代下解决暗硅效应的有效途径。暗硅效应(Dark Silicon)指由于芯片工艺和尺寸的限制,芯片上只有一小部分区域可以同时运行,其余的区域被闲置或关闭,这些闲置或关闭的区域被称为“暗硅”。在AI计算领域,由于摩尔定律的限制和散热问题,先进高效的硬件设计会更容易导致暗硅效应,限制了芯片的计算能力和应用范围。据相关论文,在22nm制程下,暗硅面积将达21%。在8nm制程下,暗硅面积将提升至50%以上。由于暗硅效应,预计到2024年平均只能实现7.9倍的加速比,与每代性能翻倍的目标相比差距将近24倍。
FPGA的可编程性和可重构性使其能够灵活地部署和优化计算任务,从而在一定程度上缓解了暗硅效应的影响。简单来说,FPGA减少暗硅效应的方法有两个方向,一是通过优化电路结构,尽可能减少不活跃区域的数量;二是通过动态重构电路,使得不活跃区域可以被重用。
缺点:1. 价格较高,规模量产后的单价更是远高于ASIC。目前FPGA的造价相比GPU更为高昂,如果规模量产后,其不像ASIC可以分摊固定成本,存在单个芯片的编译成本,所以单价远高于ASIC。2. 计算能力和峰值性能不如GPU。3. 灵活性占优的同时牺牲了速度与能耗。效率和功耗上劣于专用芯片ASIC。4. FPGA的语言技术门槛较高。目前FPGA的设置要求用户用硬件描述语言对其进行编程,需要专业的硬件知识,具有较高的技术门槛。
FPGA没有极致的性能特点与量产单价高是其未来发展的瓶颈,更适合用于细分、快速变化的垂直行业,应用面上较为狭窄。
ASIC 是一种根据产品的需求进行特定设计和制造的集成电路,能够更有针对性地进行硬件层次的优化。由于 ASIC 能够在特定功能上进行强化,因此具有更高的处理速度和更低的能耗。相比于其他 AI 芯片,ASIC 设计和制造需要大量的资金、较长的研发周期和工程周期,在深度学习算法仍在快速发展的背景下存在一旦定制则难以修改的风险。一种算法只能应对一种应用;一颗AI芯片只能单一地解决一种问题;而算法在不断演变,每3~6个月就可能变一次;ASIC芯片或许尚未上市,算法就已经发生进化了。
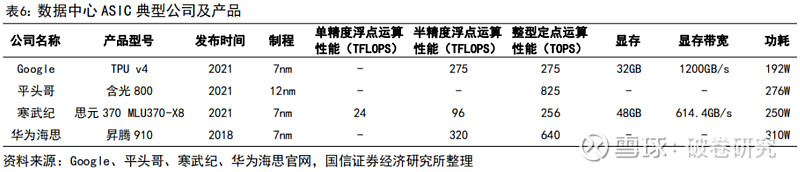
➢ 能效方面:由于ASIC是为特定应用程序设计的,其电路可以被高度优化,以最大程度地减少功耗。根据Bob Broderson数据, FPGA的能效比集中在1-10 MOPS/mW之间。ASIC的能效比处于专用硬件水平,超过100MOPS/mW,是FPGA的10倍以上。
➢ 算力方面:由于ASIC芯片的设计目标非常明确,专门为特定的应用场景进行优化,因此其性能通常比通用芯片更高。根据头豹研究院数据,按照CPU、GPU、FPGA、ASIC顺序,芯片算力水平逐渐增加,其中ASIC算力水平最高,在1万-1000万Mhash/s之间。
随着技术、算法的普及,ASIC将更具备竞争优势。ASIC在研发制作方面一次性成本较高,但量产后平均成本低,具有批量生产的成本优势。目前人工智能属于大爆发时期,大量的算法不断涌出,远没有到算法平稳期,ASIC专用芯片如何做到适应各种算法是当前最大的问题。但随着技术、算法的普及,ASIC 将更加具备竞争优势。
ASIC主要应用在推断场景,在终端推断市场份额最大,在云端推断市场增速较快。
➢ 训练:AI模型在训练过程中需要对模型参数进行不断调整,ASIC由于专用性强、灵活性低,因此不适用于云端训练。根据赛迪顾问数据,2019年GPU、FPGA、ASIC在云端训练市场占比分别为63.9%、22.6%、13.5%,云端训练仍以GPU为主。
➢ 推断:与训练场景不同,推断场景模型参数较为固化,ASIC在推断市场场景中的应用前景较为广阔。在早期,ASIC的下游应用场景主要为各领域智慧终端设备,因此在终端推断市场规模较大。目前,随着云端算力需求的不断增加,ASIC凭借出色的算力水平开始在云端推断领域快速渗透。根据赛迪顾问数据,2019年ASIC在终端推断的市场份额为41%,远超GPU与FPGA。2019-2021年在云端推断的市场年均增速均保持在60%以上,高于CPU与FPGA。
风险提示:本内容仅代表破卷研究的分析、推测与判断,登载于此仅出于传递信息之目的,不作为投资具体标的之依据。投资有风险,入市需谨慎!
版权声明:本内容版权归原创方或原作者所有,如转载使用,请注明来源及作者、文内保留标题原题以及文章内容完整性,并自负版权等法律责任。