
核心观点
利用供应链原始数据构建了供应链基础网络,并在基础网络的基础上利用第三方关系构建了供应链扩展网络,扩展网络中的关系提升了一个量级,更突出了大量非上市公司在经济中所扮演的角色,也提升了 A 股覆盖度;
基础网络和扩展网络内,有关联的股票对都比无关联股票对表现出更强的相关性;而扩展网络中基于第三方的间接关系下的相关性略低于基础网络中的直接关系下的相关性;扩展网络的间接关系中,供应商-供应商、客户-客户的相关性略强于供应商-客户;但供应商-供应商、客户-客户的差异并不明显;
对供应链基础网络进行社群检测,集群内部股票对也比集群外股票对表现出更强的相关性,供应链集群的划分是有效的,能区分相关性强的股票和相关性弱的股票;
基础网络的直接关系、扩展网络的间接关系、供应链社群关系,在行业内部也都有效,能带来有异于行业关系的增量信息。
一、前言
Frédéric Abergel, Adrien Akar 在 Supply chain and correlations (2022) 中利用彭博的供应链数据深入研究了供应链网络本身以及供应链网络社群对股票之间相关性的影响,发现存在供应链关系或位于供应链社群内部的股票之间有更高的相关性,即使在极端行情下也成立,这为能将供应链关系引入风险模型中提供依据。具体内容可以参考公众号之前的文章:基于供应链网络的股票收益分析
本文借鉴作者的研究思路,利用国内的供应链数据(数库科技提供),对 A 股市场进行实证研究,探究供应链网络和供应链社群对股票之间相关性结构的影响。
二、供应链基础网络
2.1 供应链原始数据
研究所用的供应链原始数据来自数库科技 Chinascope 提供的供应链数据,部分字段如下所示:

供应链原始数据中既包含公司节点,也包含人物节点,在后续研究中需要将人物相关的节点和边剔除,只保留公司之间的供应关系。下表是供应链原始数据中节点和边的统计表,所有数据中大约 1% 的节点为人物,大约 0.8% 的边包含人物。
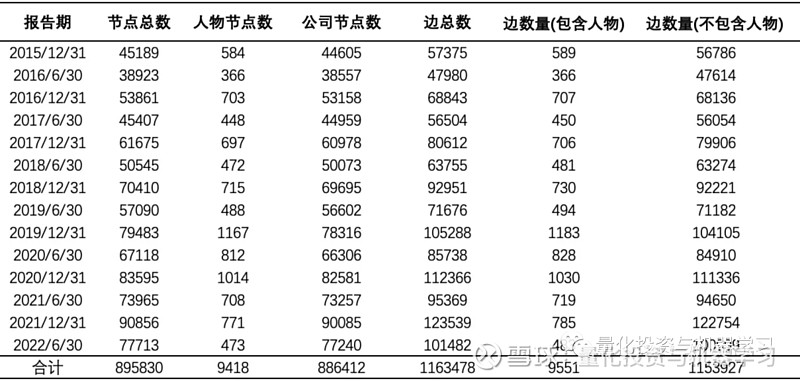
2.2 构建供应链基础网络
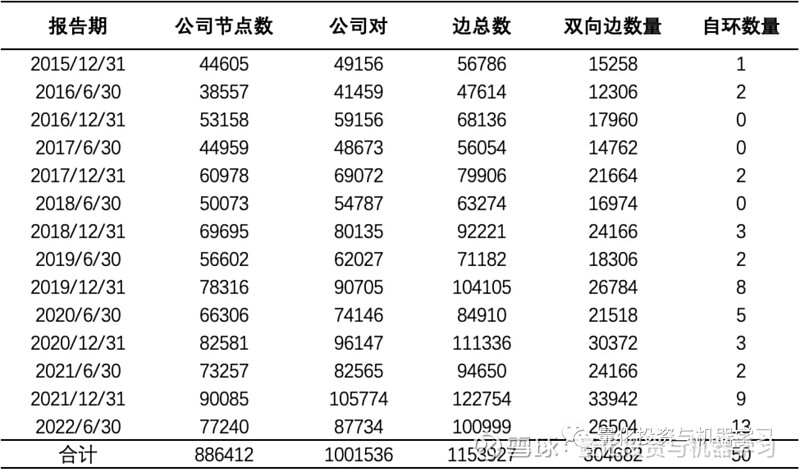
从供应链原始数据中剔除掉人物数据后,就可以进一步构建供应链基础网络了,下表是供应链中公司关系的相关统计结果。从表中可知,边 edge 的数量总是大于公司对 pair 的数量,那是因为大约 15.18% 的公司对拥有双向边,即配对公司互为对方的供应商和客户;此外还有个别公司的供应商和客户都为公司本身,形成节点自环。
在构建供应链基础网络时,对于双向边的选择,主要遵循如下规则:① 保留金额更高的那个方向,金额优先级为交易金额>期末余额>坏账准备;② 如果 ① 无法满足,则选历史上出现次数更多的那个方向;③ 如果 ② 无法满足,则随机选一个方向。最终的供应链基础网络为只包含公司节点、经过双向边筛选、不包含节点自环的网络;以 2022 年半年报披露情况为例,供应链基础网络的规模为包含 77240 个节点,87734 条边。
2.3 供应链基础网络在报告期上的延续
从上文各报告期的供应链网络规模统计结果中可知,由于年报通常比半年报披露的更为详实,半年报的网络规模普遍小于年报的网络规模。为了弥补数据的相对缺失,我们对供应链关系进行报告期上的延续,延续几个报告期较为合理呢?下面对供应链关系在历史上的延续性进行了简单分析。
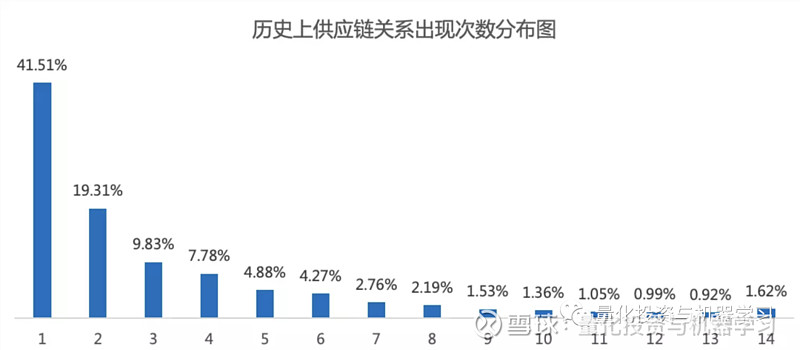
下图统计了 2015-12-31 至 2022-06-30 报告期内,1001536 条供应链关系中所有唯一关系出现次数的分布占比情况,有 41.51% 的关系在历史上只出现过一次,但有 68.49% 的关系在历史上出现 2 次及以上,而且有 1.62% 的关系每个报告期都会出现。供应链关系在历史上重复出现的可能性较高。
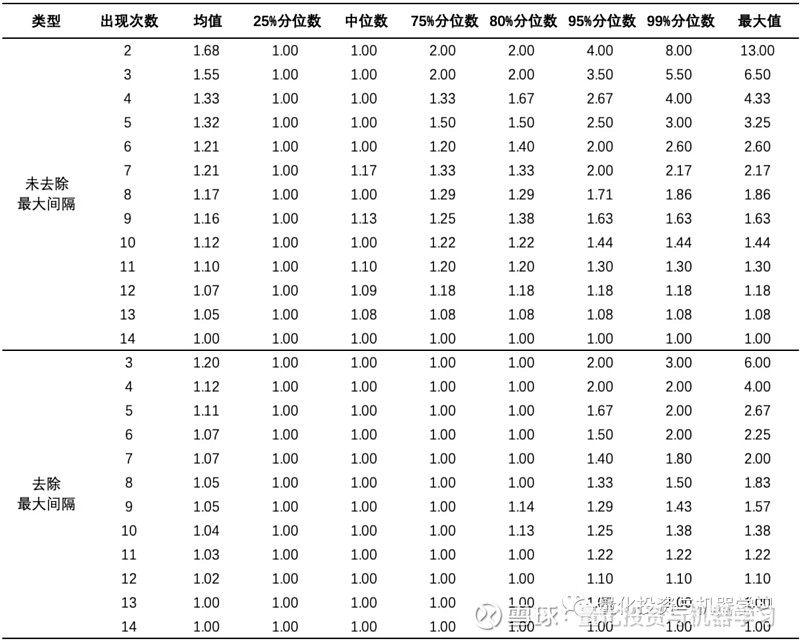
下图统计了供应链关系各重复出现次数下间隔报告期数的描述性统计指标。重复出现次数越高,间隔报告期数相对越少;各重复出现次数下间隔报告期数的均值和中位数都未超过 2 个报告期。为了减少连续出现的间断性(比如关系 1 在 2015-12、2016-06 连续出现,在 2021-12、2022-06 连续出现,但两次连续出现之间有间断)的影响,剔除最大间隔后再做统计,间隔未超过 2 个报告期的样本从 80% 提高到了 95%,说明对于出现多次的供应链关系,在下一报告期继续出现的可能性是很高的。由此可知,将供应链关系延续 1-2 个报告期(半年至一年)是较为合理的,而且实际中供应链关系发生后对两家公司的影响本身具有一定的持续性(不管是否披露在财报中)。
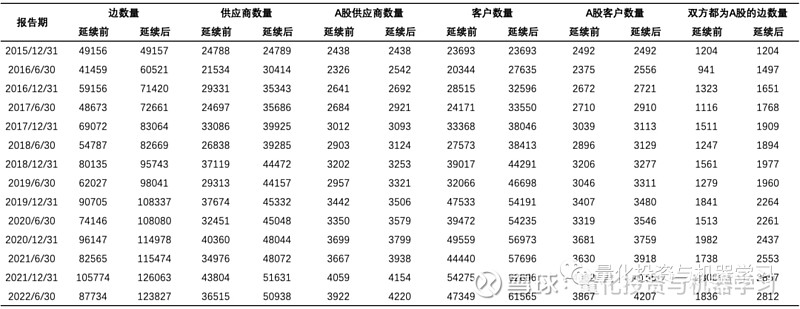
本文选择将供应链关系延续 1 个报告期,供应链关系延续一个报告期后的基础网络规模如下表所示:将上一年报数据延续至半年报,相应半年报的基础网络的边数量平均增长了大约 47.28%,双方都为 A 股的边数量平均增长了大约 53.16%;将上一半年报数据延续至年报,相应年报的基础网络的边数量平均增长了大约 19.77%,双方都为 A 股的边数量平均增长了大约 24.66%。后文所有的研究都基于报告期延续后的基础网络展开。
三、供应链扩展网络
在基础网络的基础上,考虑与第三方公司相关的两个公司之间存在关联,即当公司 A 和 B 都和公司 C 之间相关,那么可以将公司 A 和公司 B 加入供应链网络之中,从而衍生出供应链扩展网络。衍生出的 A 和 B 之间的关系主要有 3 大类,分别是:
供应商-客户:A 和 B 是供应链的上下游,C 处于它们中间,即 A 供应 C 供应 B 或 B 供应 C 供应 A;
供应商-供应商:C 是 A 和 B 的共同供应商;
客户-客户:C 是 A 和 B 的共同客户。
下面分别统计了 3 大类扩展关系的规模以及 A 股相关的数量:
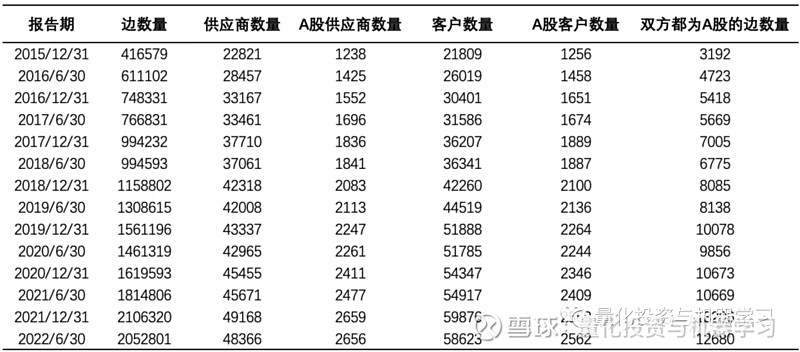
① 扩展的 “供应商-客户”关系规模
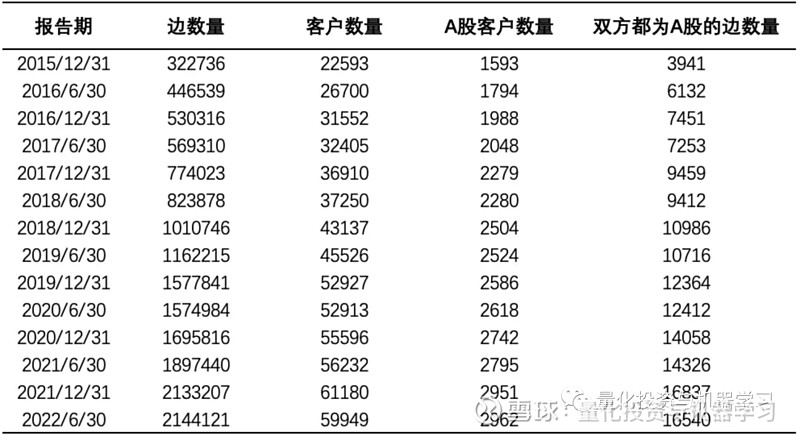
② 扩展的“供应商-供应商”关系规模( AB 双方都是 C 的客户)
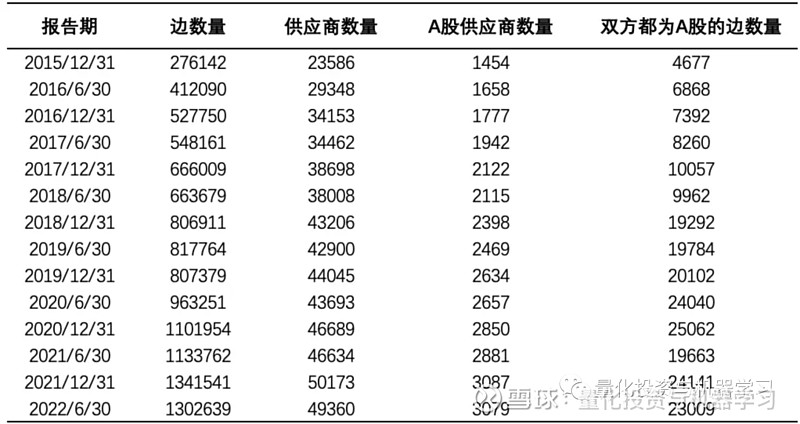
③ 扩展的“客户-客户”关系规模( AB 双方都是 C 的供应商)
四、供应链社群检测
4.1 社群检测算法
为了更深入探究供应链中公司与公司之间的关系,可以引入基于图论的社群检测算法。社区检测算法是一种网络聚类算法,用于发现大型复杂网络之间紧密联系的集群,在集群内部节点连接紧密,在集群与集群之间节点则连接松散。模块度 (modularity) 是用来衡量社区网络结构强度的指标,模块度越高,说明社区网络划分集群的质量更好,即集群内部是强连接,集群外部是弱连接。常用的基于模块度的社区检测算法有 louvain 算法和 leiden 算法,其中 louvain 算法的缺点是划分得到的社区内部可能是不连通的,而 leiden 算法在 louvain 算法的基础上进行了改进,保证了社区内部的连通性且计算速度更快。因此,下面的研究主要选用 leiden 算法对供应链网络进行社群检测。
4.2 社群检测结果展示
在对报告期延续后的基础网络进行社群检测时可以发现,整个基础网络是由一个大连接组件和许多小连接组件构成的,小连接组件内的公司数量很少,但组件间划分明显,如下图所示:

统计 2022 年中报的供应链网络初始聚类后的连接组件的规模分布情况(如下图所示),横坐标代表集群规模,纵坐标代表该规模下集群的数量,最大组件的规模为97885,其余组件的规模均小于 220,因此,后面只对供应链网络中的最大组件进行集群检测,这是因为大组件以外的较小的连接组件只包含少量的公司,对研究基本没有帮助。
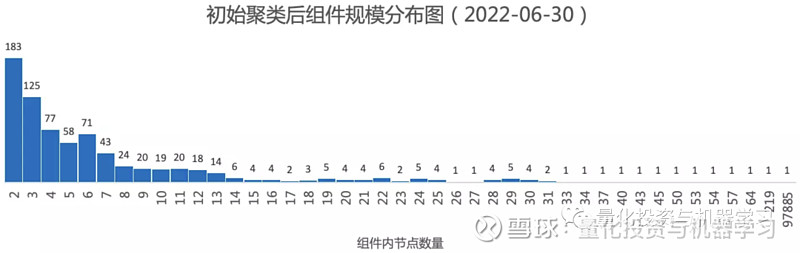
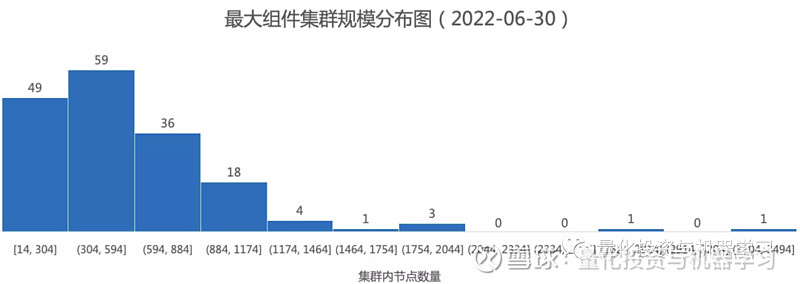
对最大组件应用 leiden 算法进行社群划分,共划分成了 172 个集群,各集群规模大小分布如下图所示,其中横坐标代表集群的规模范围(即拥有的公司数量),纵坐标代表该集群规模下集群的数量,前几大集群的规模并不小。
下图展示了最大组件下规模 top50 的集群内部非上市公司和上市公司的数量,上市公司在集群中的分布比较均匀,占比不高,这是由于非上市公司的数量远超于上市公司,而将上市公司和非上市公司一起进行社群检测,才能更真实完备反应公司之间的商业关系,并从非上市公司中挖掘出增量信息。

4.3 社群检测与行业分类的差异
供应链社群检测与行业分类是相似的,两者都是对公司做归类,但归类依据不同,前者是基于公司间的供应链关系进行归类。供应链社群检测相比行业分类,是否相对独立的?是否能提供新的增量信息?下面几幅图分别绘制了数库 GICS 一级行业和中信一级行业(针对集群内的 A 股)在最大组件集群内部(规模 top50 的这些集群)的分布和占比情况,从图中可知,集群内部的行业分布相对分散,没有出现一个集群内部全为某一行业成分公司的情况。
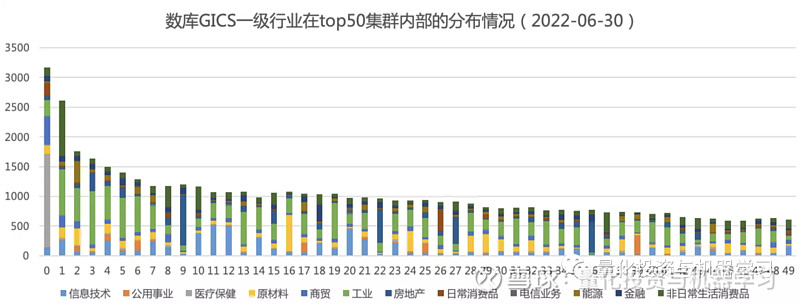

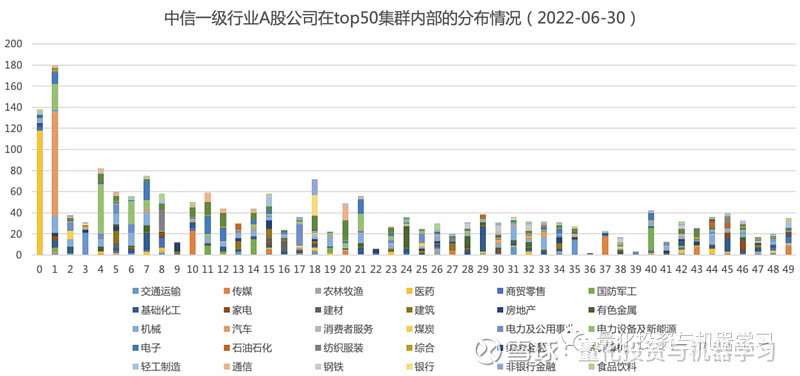
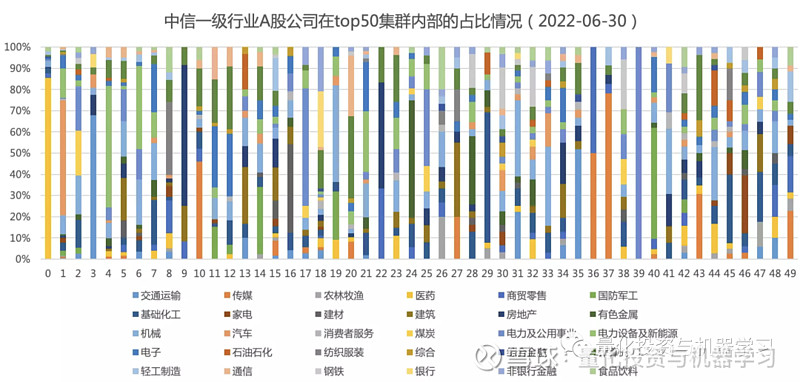
为了更精准的评估供应链的集群划分与行业划分的不一致性,统计了集群内成分公司与各行业成分公司的重叠率,集群 i 对行业 j 的重叠率 = 集群 i 内属于行业 j 的公司数量 / 所有集群内属于行业 j 的公司总量,重叠率也可看作是行业成分公司在所有集群的分散度的衡量指标,重叠率越小,供应链集群与行业划分的差异越大,重叠越少,行业成分公司在集群内越分散,供应链集群提供的新信息也更多。
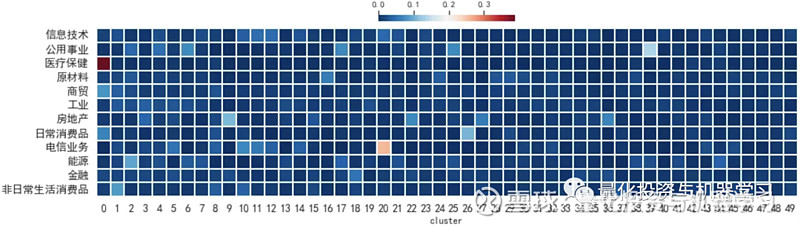
下图绘制了规模 top50 的供应链集群与数库 GICS 一级行业的重叠率。个别集群内单个行业重叠率较高,如集群 1 内医疗保健重叠率高达 38.84%,集群 21 内部电信业务的重叠率有 25.69%,但整体低的重叠率很低,在 1.2% 左右,说明供应链集群能提供行业以外的新信息。
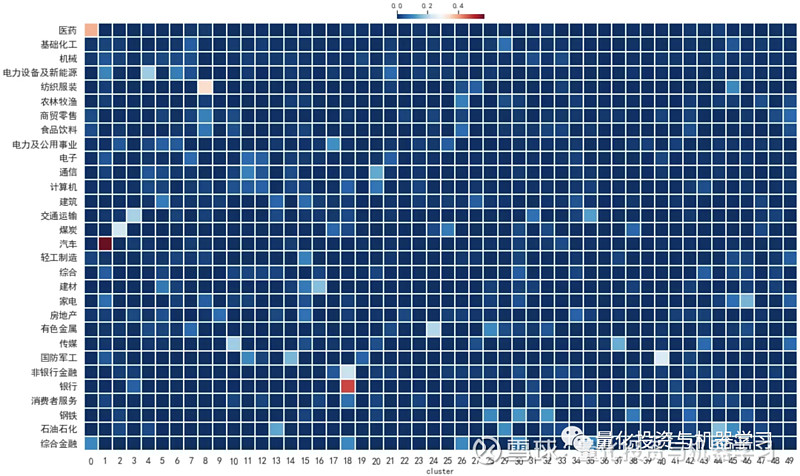
下图绘制了规模 top50 的供应链集群内的 A 股公司与中信一级行业成分股的重叠率。整体重叠率也很低,在 1.06% 左右;同样存在个别集群内单个行业重叠率较高的情况,如集群 1 在医药上的重叠率有 38.56%、集群 2 在汽车上的重叠率有 56.98%、集群 19 在银行上的重叠率有 47.5%,但仍然可以说明供应链集群是不同于行业划分的一种新划分方式。
五、收益率相关性分析
供应链数据描述了公司之间存在的商业关系,越来越多的研究表明供应链关系与上市公司股价的表现存在一定的相关性。相比无关联的 A 股,供应链中存在关联的 A 股之间股价相关性是否更强?直接关联和间接关联下的相关性是否存在差异?不同的供应链关系下的相关性是否存在差异?对供应链网络进行社群检测后,社群内外的相关性又有何特点?为了分析上述问题,我们对不同关系下股票对的日度收益率序列计算 Pearson 相关系数,通过比较相关系数的分布来体现不同关系下的股价相关性的特点。
在计算收益率相关系数时,需要确定收益率序列的时间区间,划分时间点选用的是报告期的最晚披露截止日:对于 t 年的半年报,收益率序列的时间区间为 [t年的8月30日,t+1年的4月30日);对于 t 年的年报,收益率序列的时间区间为 [t+1年的4月30日,t+1年的8月30日)。由于半年报和年报收益率序列长度存在不一致,下文在绘制收益率相关系数分布时,会同时展示 2021-12-31 和 2022-06-30 两个报告期的表现。
5.1 基础网络的收益率相关性分析
基础网络中的供应链关系是最直接的,基础网络中存在关联的股票对 connected,即为供应链网络中每条边两端的节点对;不存在关联的股票对 unconnected,即为供应链网络所有 A 股节点两两配对后剔除掉前面那部分关联股票对后剩余的股票对。下图绘制了年报和半年报下,关联股票对和非关联股票对的收益率相关系数分布图,可以发现前者的相关性更强,分布更偏向于横坐标的右侧。
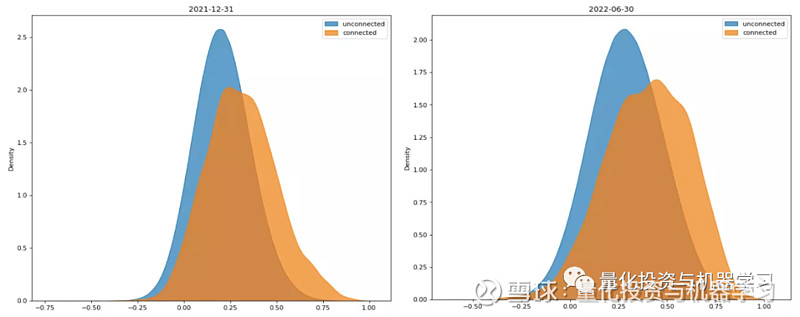
下表统计了各报告期下关联股票对和非关联股票对的收益率相关系数的描述性统计指标,可以发现上图规律在时间上并非随机,各报告期下都呈现出“关联股票对相关性强于非关联股票对”的特点:
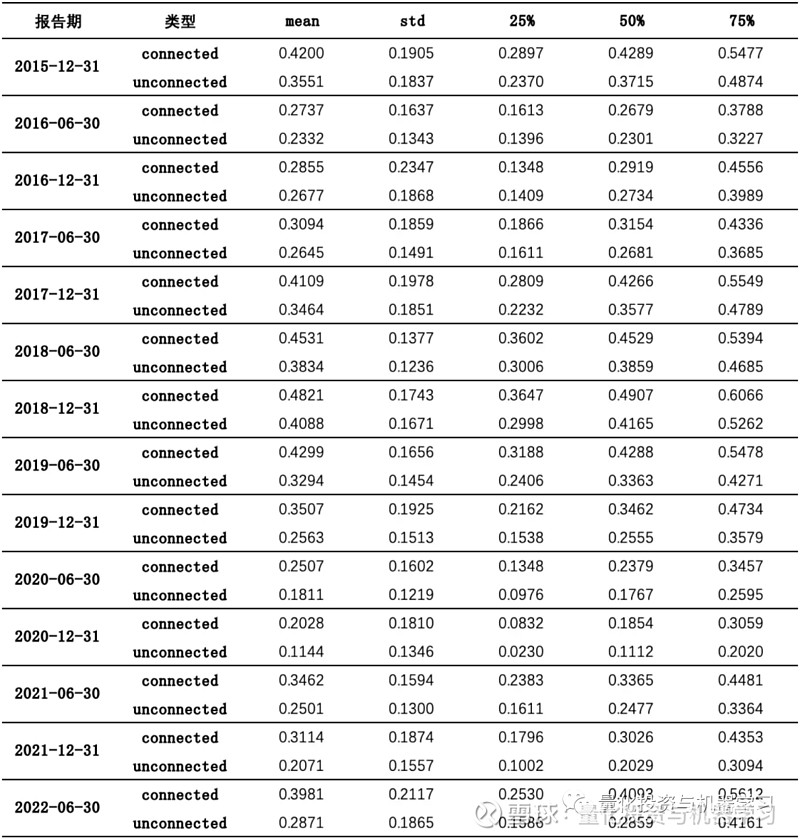
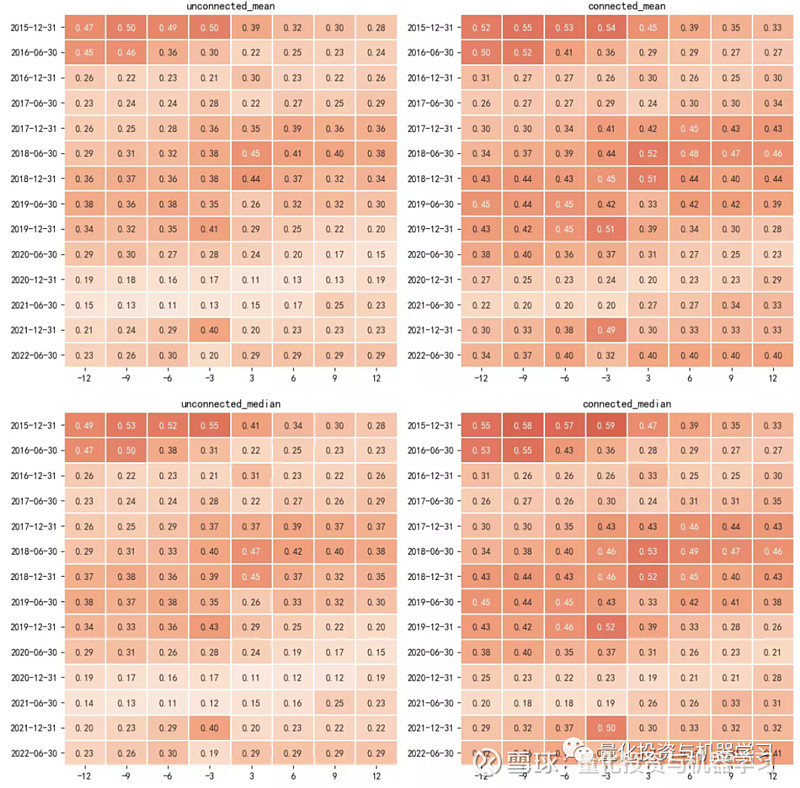
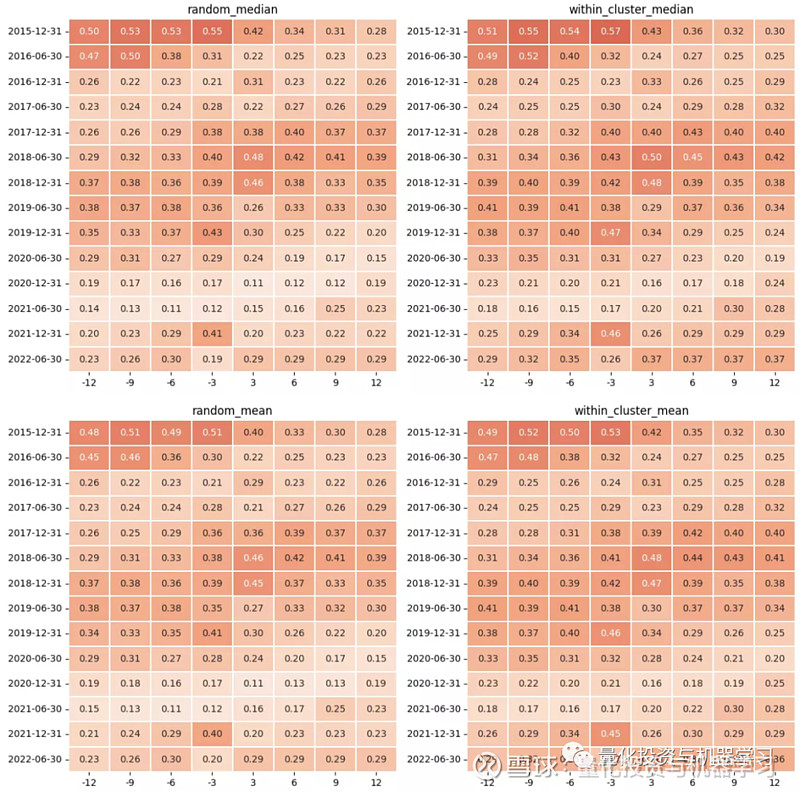
为了进一步探究基础网络中供应链关系披露前后收益率相关性的特点,对收益率序列的时间区间进行前置和后置处理,分别取报告期最晚披露时间 t(8月30日、4月30日)前置 i 个月的时间区间 [t-i*30, t] 和后置 i 个月的时间区间 [t, t+i*30],其中 i = 3,6,9,12 个月,计算各区间下股票对的收益率相关系数的均值和中位数,并绘制得到下面的热力图。从图中可以发现:无论是关系披露前还是关系披露后,关联股票对的相关系数都要高于非关联股票对(右图的颜色比左图深);关系披露后的相关性并不一定比关系披露前高;距离披露截止日近的相关性也并不一定比距离披露截止日远的相关性高。
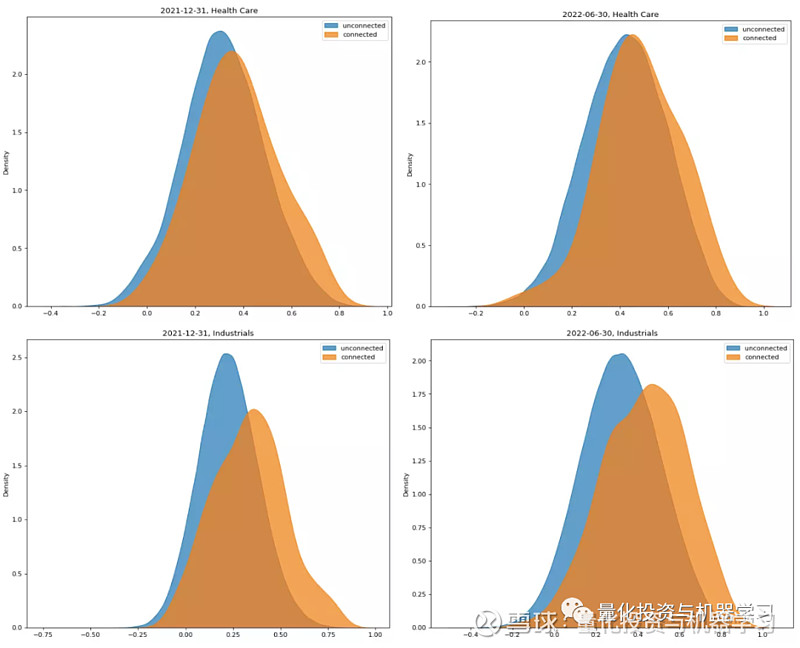
为了探究行业内部是否也存在“关联股票对相关性强于非关联股票对”的特点,计算了医疗保健 Health Care 和工业 Industrials 内部的股票对收益率的相关系数(对行业内成分股两两配对,并划分成关联股票对和非关联股票对两部分,行业划分方式为数库GICS一级行业)。相关系数分布图如下所示,可以发现行业内部也呈现同样的特点,关联股票对的分布更偏向于横坐标的右侧,而且工业的差异更明显。
5.2 扩展网络的收益率相关性分析
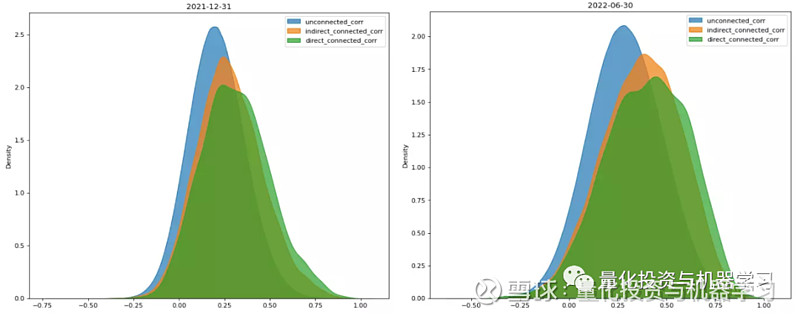
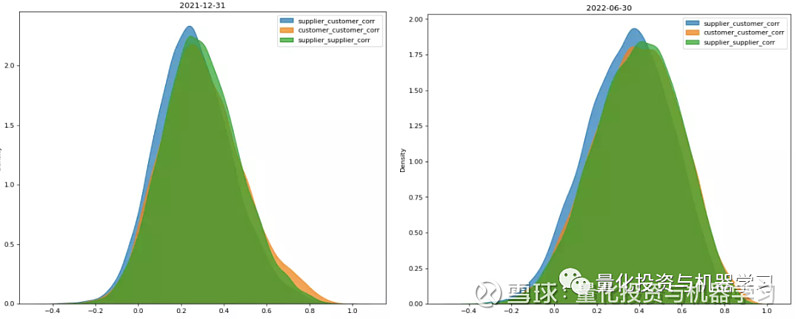
供应链扩展网络除了包含基础网络中的直接关系外,还包含基于第三方得到的间接关系,可以进一步比较间接关系和直接关系下收益率相关系数孰强孰弱。将供应链扩展网络的所有 A 股节点进行两两配对,得到所有股票对;筛选出属于基础网络的直接关联股票对,作为direct_connected;筛选出只属于扩展网络的间接关联股票对(包括供应商-客户、供应商-供应商、客户-客户),作为 indirect_connected;剩余的股票对即为无关联的随机股票对,作为unconnected,分别计算 3 类股票对的收益率相关系数,并绘制如下分布图。从下图可知,来自扩展网络的间接供应链关系下的相关性同样强于无关联下的相关性,而且间接关系下的相关性只是略低于直接关系下的相关性。
在相关性同样理想的情况下,相比基础网络,扩展网络中的关系比基础网络提升了一个量级,更突出了大量非上市公司在经济中所扮演的角色,而且也大大提高了供应链关系在 A 股上的覆盖度。
下图对比了扩展网络的 3 种扩展关系下股票对的收益率相关性的差异:供应商-供应商、客户-客户的相关性略强于供应商-客户;但供应商-供应商、客户-客户的差异并不明显,客户-客户的右尾略厚于供应商-供应商。
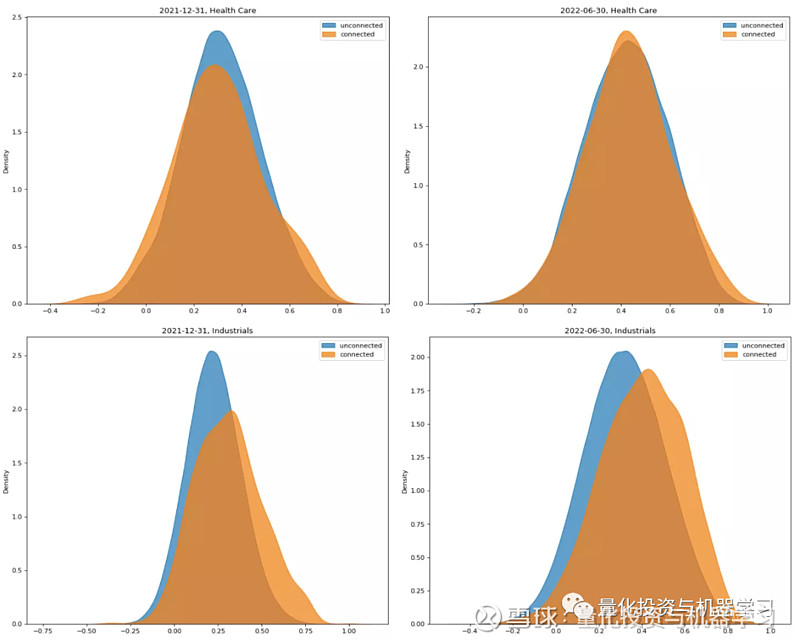
下图同样探究了供应链扩展网络在医疗保健 Health Care 和工业 Industrials 内部的股票对收益率的相关系数分布图,行业内关联股对的相关性同样高于无关联股票对的相关性,而且同样是工业 Industrials 内部差异更明显。
5.3 社群内外的收益率相关性分析
对供应链数据进行社群检测,得到的 n 个集群可以看作是类似行业、概念、地域分类的一种新的划分方式。供应链集群是否能带来新的增量信息?集群内外股票的相关性是否存在显著差异?对上文社群检测得到的所有集群内部的 A 股进行两两配对,然后将这些股票对求并集,得到集群内的股票对集 within_cluster ;将所有 A 股进行两两配对,剔除上一步的 within_cluster 股票对集,就得到了集群外的股票对集 random;分别计算两个股票对集的收益率相关系数。
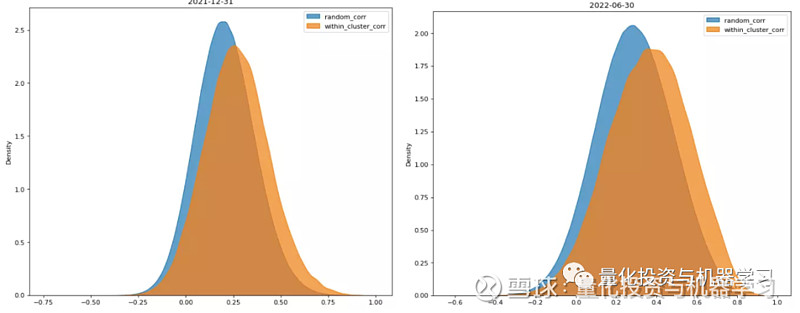
下图是年报和半年报下的集群内外股票对的相关系数分布图,可以看到集群内部股票对的相关性高于集群外股票对的相关系数,前者分布更偏向于横坐标的右侧,供应链集群的划分是有效的,能区分相关性强股票和相关性弱的股票。
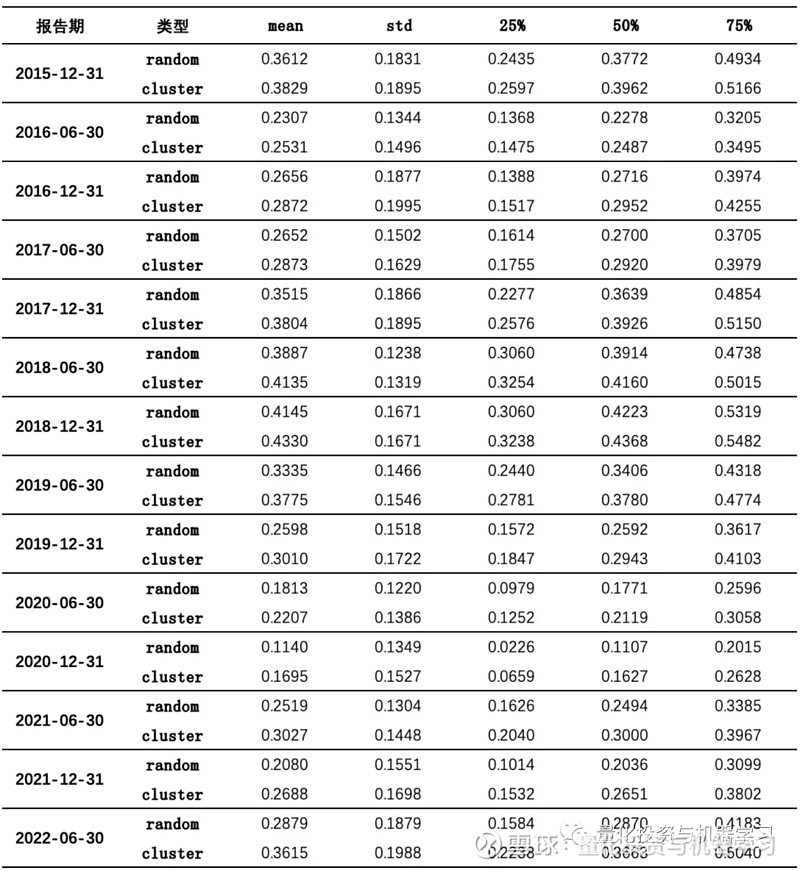
为了避免出现时间上的随机性,下表展示了所有报告期下集群内外相关系数的描述性统计指标,可以发现,各报告期下也都呈现出“集群内股票相关性强于集群外”的特点:
对于集群内外的相关性差异,同样考察了供应链关系披露前后收益率相关性的特点,对收益率序列的时间区间进行前置和后置处理,绘制了如下热力图,从图中可知:无论是披露前还是披露后,集群内股票对的相关系数都要高于集群外的股票对。
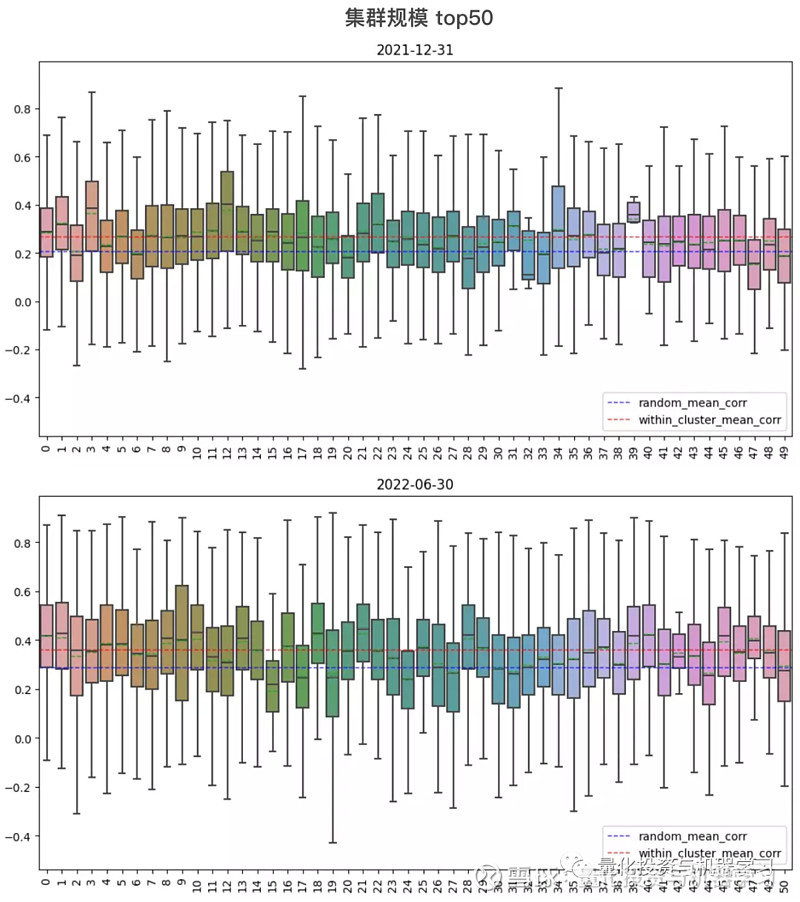
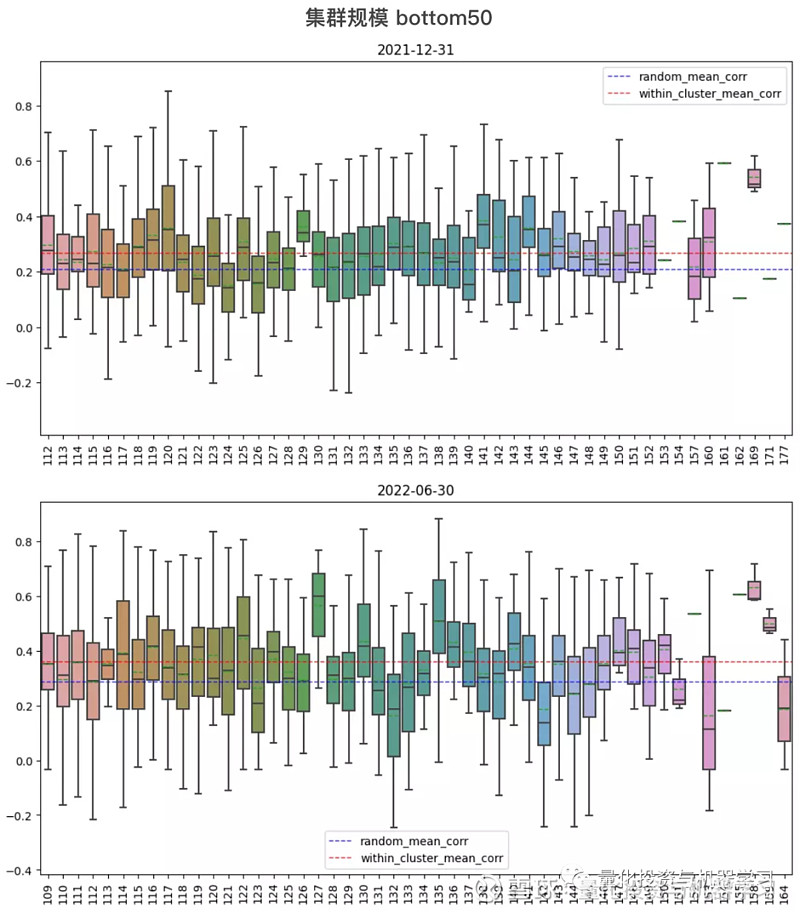
上文统计的是所有集群内股票对合集的相关性表现,下文则分别计算了每个集群内部的两两股票对的相关系数,并绘制了箱线图,X 轴为集群编号,编号越靠前,集群规模越大,分别绘制了集群规模前 50 和最后 50 的相关系数箱型图。各集群对比下来,集群规模大小与相关性强弱并没有绝对的联系。
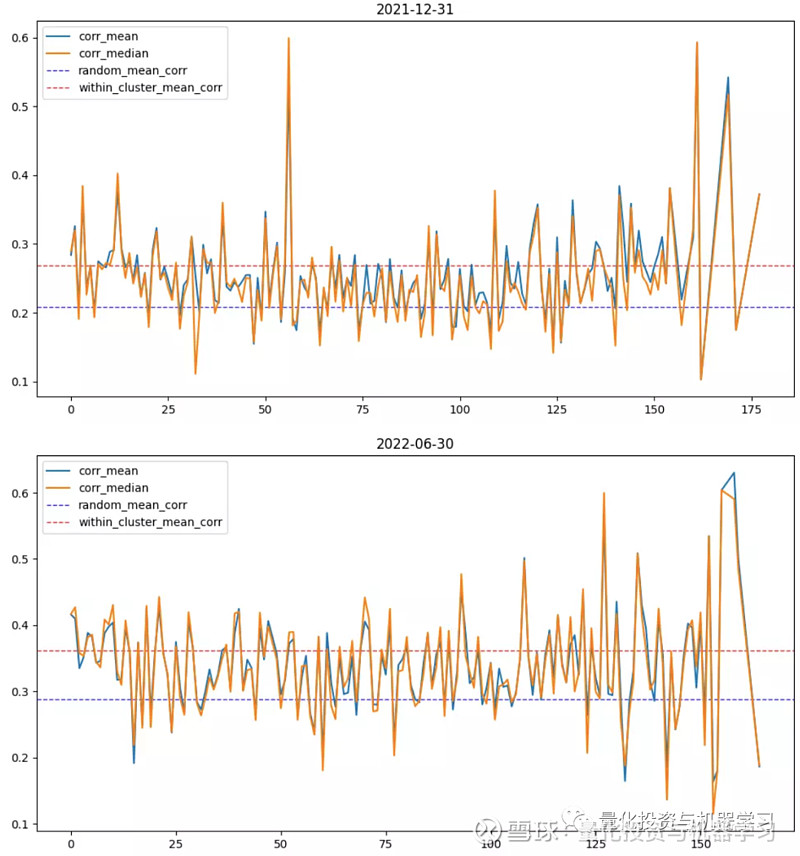
下图绘制的是所有集群内股票对相关系数的均值和中位数,也没有发现相关性强弱与集群规模有关系,比较弱的现象是集群规模小的相关性差异较大(波动大),这可能是因为股票对数量较少导致的。
下图同样探究了医疗保健 Health Care 和工业 Industrials 行业内部,集群内外股票对收益率的相关系数的差异。行业内,集群内股票对的相关性同样高于集群外股票对的相关性,而且同样是工业 Industrials 内部差异更明显。

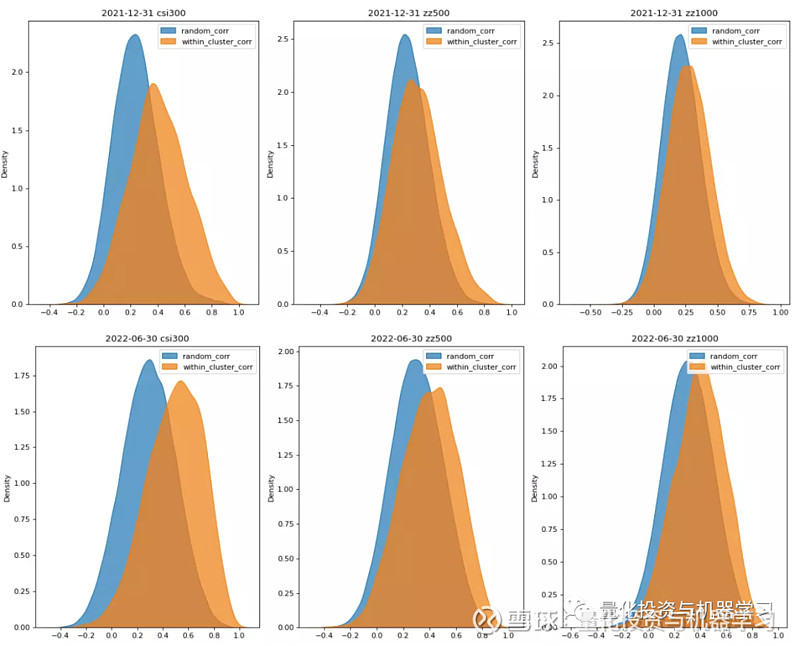
为了探究股票市值是否对集群内外关系有影响,分别在沪深300、中证500、中证1000 板块内部,计算集群内股票对和集群外股票对的收益率相关系数,并绘制如下分布图,可以发现,各板块内部,同样都呈现了“集群内股票对的相关系数都要高于集群外的股票对”,而且在沪深300 内的差异更明显,即使沪深 300 内股票对更少。由此可知,供应链社群划分确实是有效的,且不受行业和市值的影响。
六、总结
本文利用供应链数据,应用社群检测算法进行聚类,对供应链网络和供应链社群对A 股之间相关性结构的影响进行了实证分析发现:相比无关联的股票,无论是有直接或间接供应链关系的股票之间,还是有供应链网络社群关系的股票之间,都表现出更强的相关性,供应链网络确实能提供有异于行业、板块的增量信息。在验证了有影响后,后期将进一步研究供应链关系在风险模型中的应用。@今日话题 @雪球基金 @雪球私募