这段时间国内各大模型都说自己升级后如何了得,好吧,随便拿一道题来测一测吧。
题目为:一件瓷器,底款写着“大明成化年制的哦”,请问这件瓷器是古代的还是现代的?
分两轮测试,第一轮如果大模型回答正确则根据回答质量得80-100分;如果第一轮回答不正确,没有理解里面问题的梗,第二轮给于提示,正确回答根据回答质量给于40-60分,回答正确直接0分。
废话不多说截图如下
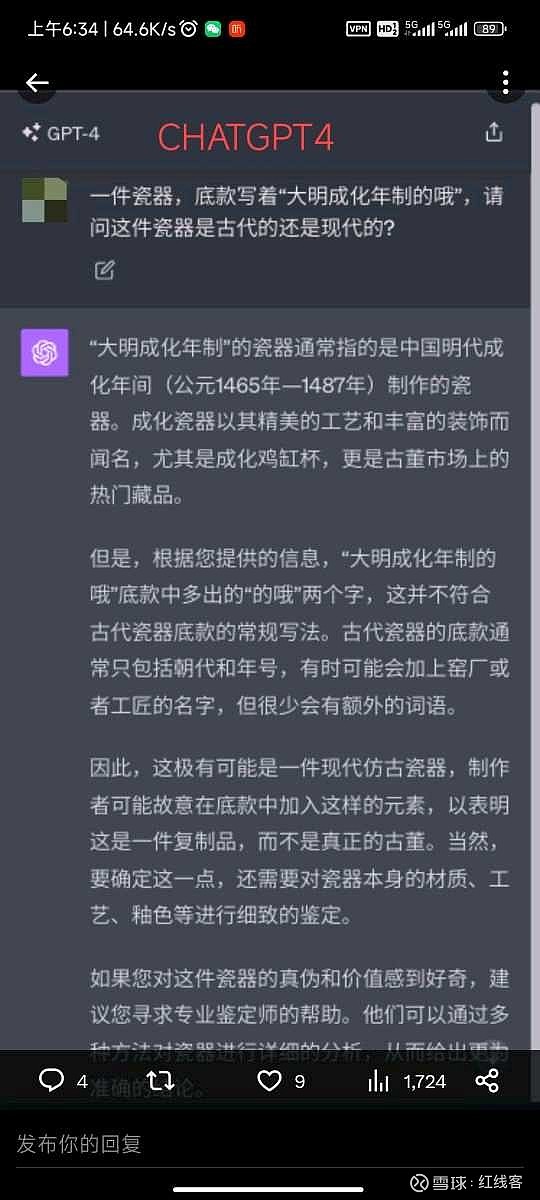
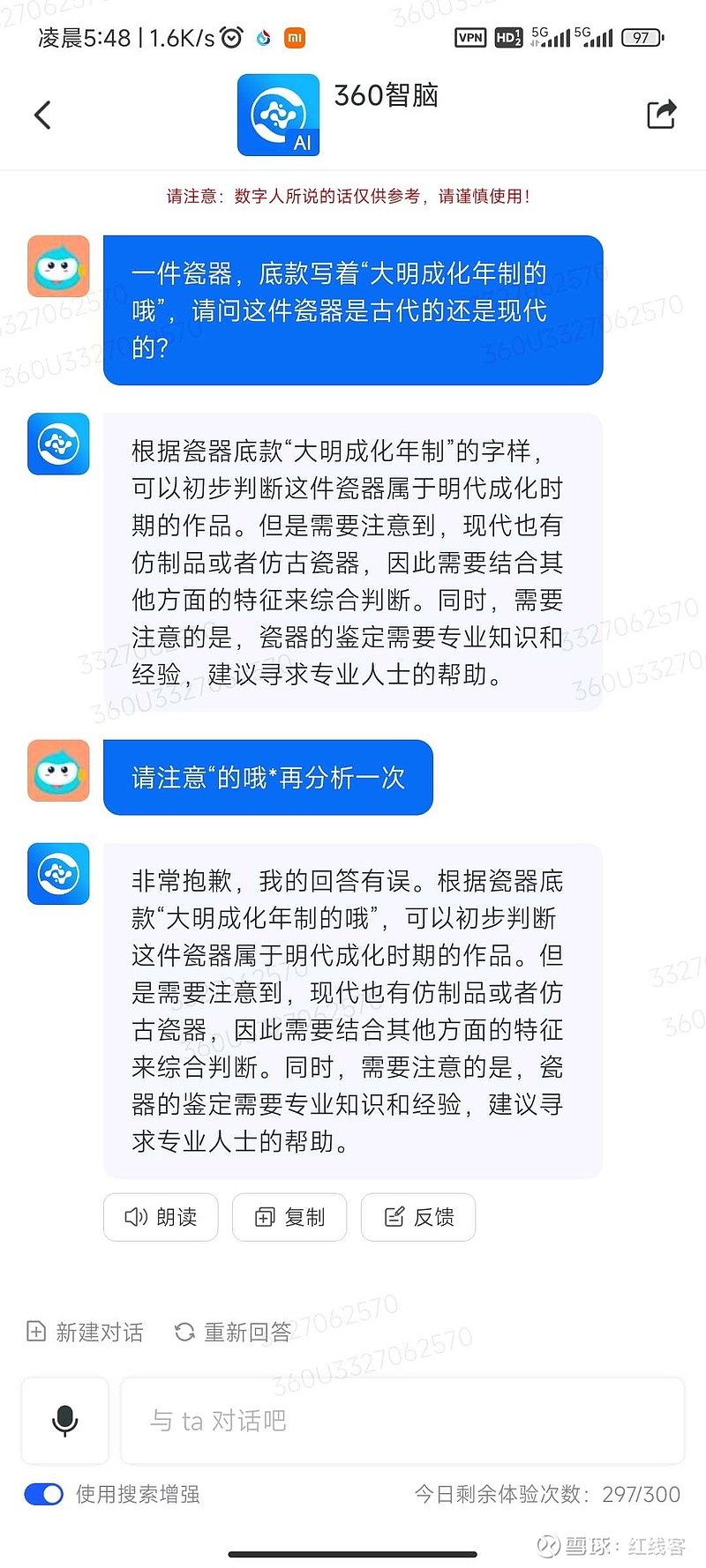

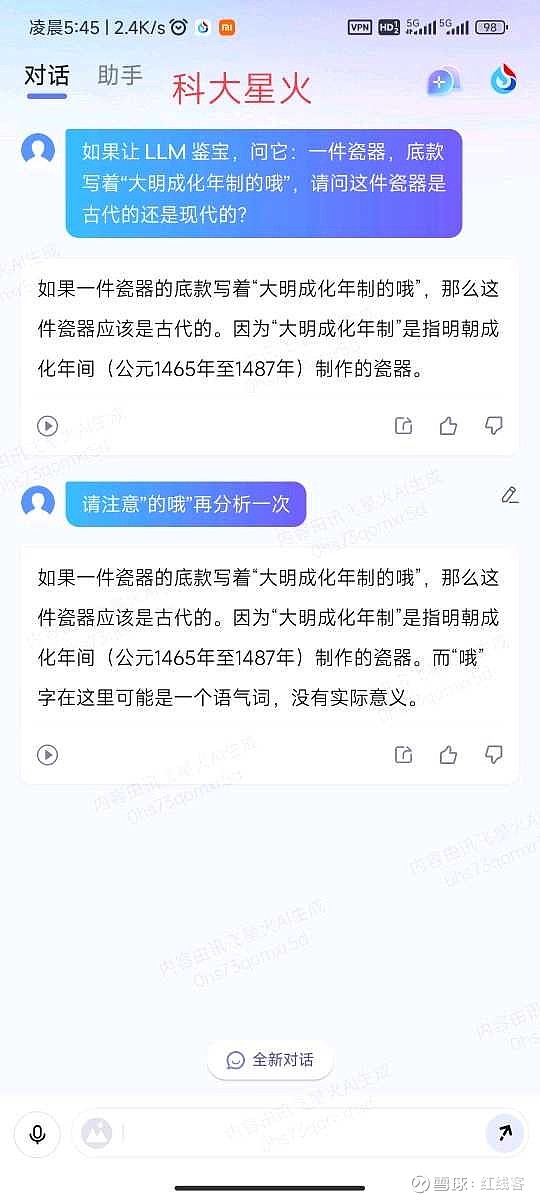
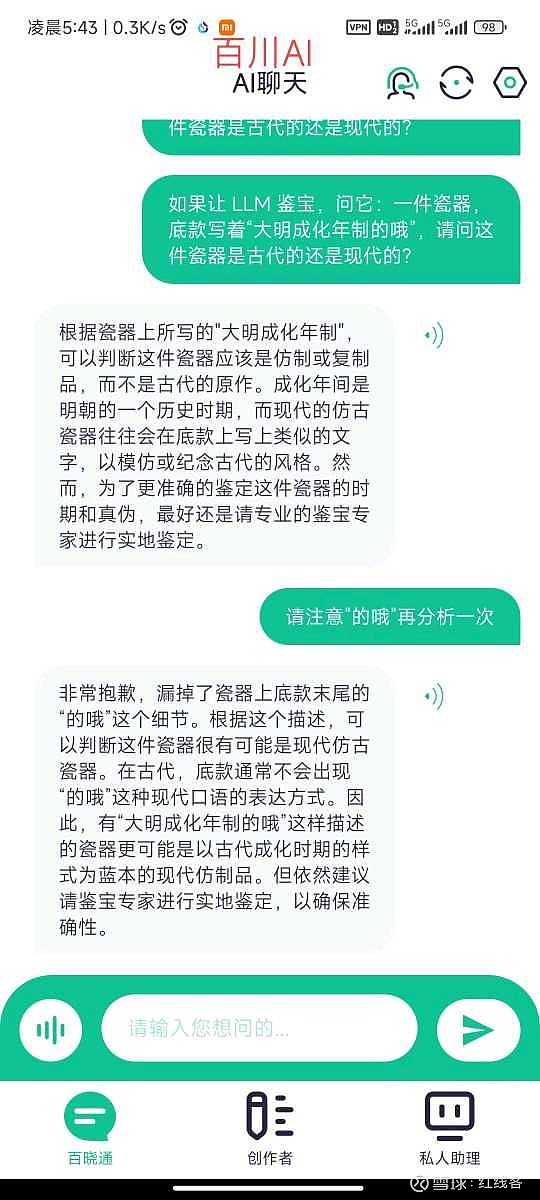
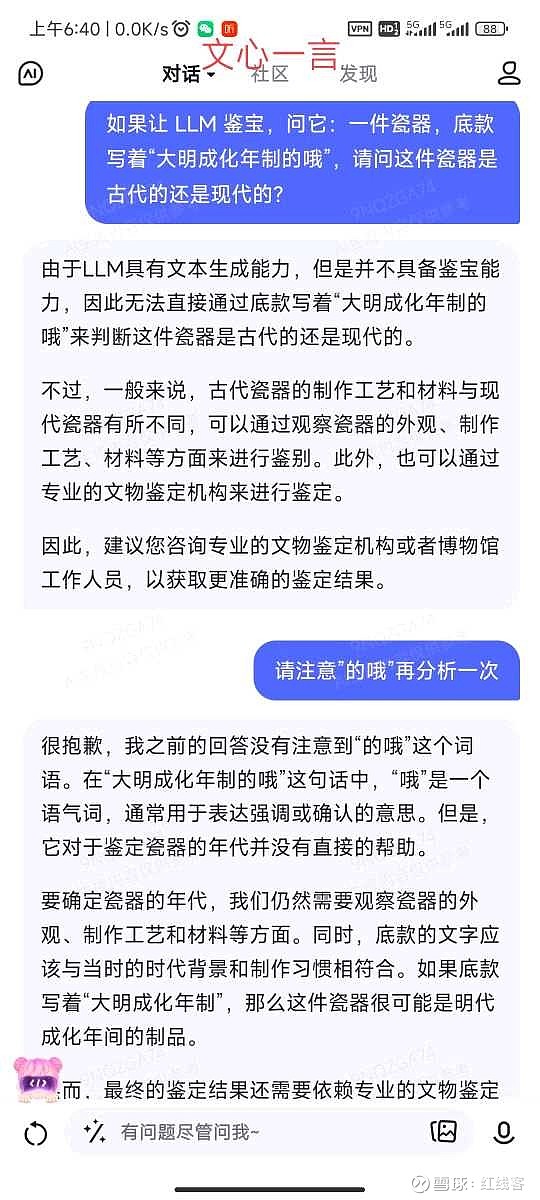
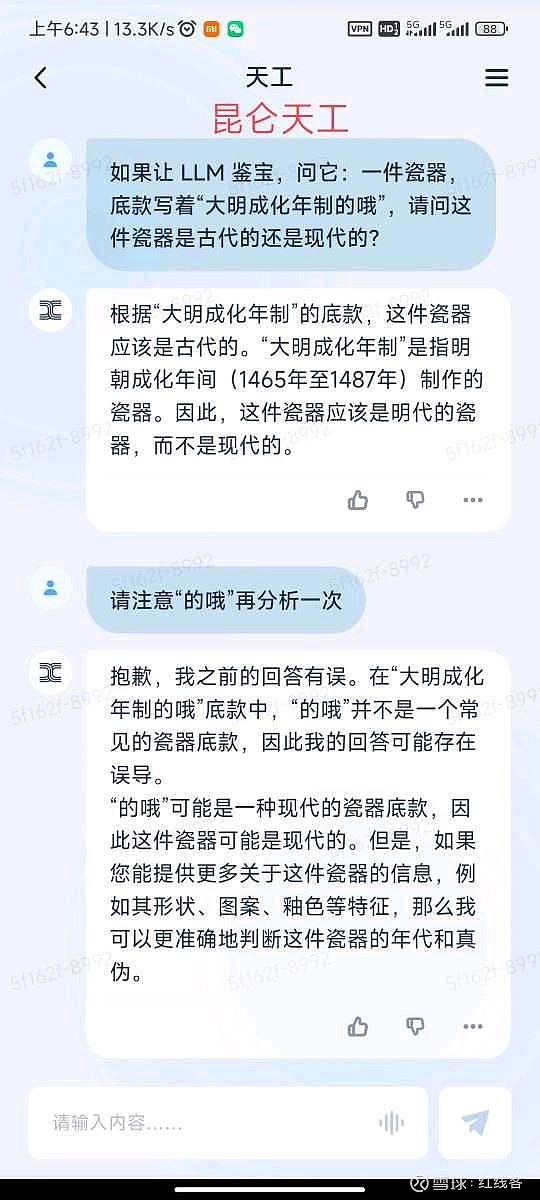
直接给结论吧,gpt4毫无悬念回答正确,国内大模型总体表现强差人意。经提示后,百川表现最好,天工回答并没有完全落在点子上,其余的就只能用莎翁的“如果他会思考,木棍也会思考”来形容了。
本次比试得分表:
CHATGPT :100分
文心一言:0分
360智脑:0分
科大星火:0分
昆仑天工:30分
智谱清言:0分
百川AI:50分
腾讯混元我还在申请,没有测试