

速度更快、效果更好的大模型,更扎实的技术。
作者|伍月
编辑|栗子
随着大模型在千行百业的逐步落地,中国基础大模型正直面来自用户端的诸多拷问。
近日,随着OpenAI宣布禁止中国用户使用其API,更多的国产大模型都在提供替代方案和优惠措施,来吸引和支持开发者进行用户迁移。
这既是一次挑战,也是一次全新的机会。
一方面,在技术差距面前,只有更强的基础大模型才更有机会从这次变局中赢得先机;另一方面,更多的用户反馈将为大模型提供更多的“养分”,促进大模型的持续迭代。
这意味着,大模型的头部效应将越来越明显。越领先的模型将吸引越多用户和资源,进一步巩固其市场地位。
作为中国最早涉猎大语言模型的公司,百度一方面在推出“搬家服务”,吸引用户迁移至百度千帆大模型平台。另一方面,百度也在迭代自身的基础大模型,直面这场愈演愈烈的市场竞争。
6月28日,百度文心大模型再次完成了最新的进化升级。在WAVE SUMMIT深度学习开发者大会2024上,百度正式发布大模型的新升级版本——文心大模型4.0 Turbo。

百度发布文心大模型4.0 Turbo
同时,百度也正式公开文心一言最新数据。百度首席技术官、深度学习技术及应用国家工程研究中心主任王海峰透露:“目前,文心一言累计用户规模已达3亿,日调用次数也达到了5亿。”
亿级的的大模型产品背后,百度正在推动大模型技术通用性和能力全面性的持续进步。
毫无疑问,在这个转折点进行全面升级,无疑为百度文心大模型在当下的大模型竞争局势添了一份更有分量的筹码。
1.好用的大模型

对于用户而言,在选择用哪个大模型这道题面前,最大的考量因子就是“好用”。
效果和速度是基础大模型比拼的两大要素。
一方面,大模型需要具备高准确性和可靠性,不仅在自然语言理解、生成、逻辑推理等基础能力上表现优秀,还需要能够处理多样化的任务并提供高质量的输出,展示在特定领域的专业知识。另一方面,模型响应时间要快,能够在短时间内处理大量请求,保证用户体验的流畅性。
新亮相的文心大模型4.0 Turbo就是在朝着这一方向精进。
自2010年起开始全面布局人工智能以来,百度在2019年3月推出文心大模型1.0;去年10月发布文心大模型4.0。文心大模型一直在持续快速进化。
而速度和效果正是文心大模型新升级的方向。“新的大模型,速度更快,效果更好”,王海峰在演讲中提到。
在现场,从文心大模型4.0Turbo和文心大模型4.0对比演示结果效果来看,新版本大模型回复速度更快,且内容更富有逻辑、细节更翔实。

文心大模型4.0 Turbo和文心大模型4.0对比演示
文心大模型4.0 Turbo如此强力的背后,离不开更好的训练以及推理支持,同时,也得益于百度在大模型的数据、算法、过程化能力的积累。
为了让大模型能力更强,百度进行了有监督的精细调整和基于人类反馈的强化学习,并改进了提示词工程,融合了知识增强、检索增强和对话增强等特色技术。
面对OpenAI“停服”中国市场,百度不仅提供“搬家”服务,还直接开放可用了。
目前文心大模型4.0 Turbo版已经可以直接在网页端进行体验,文心一言App也会在各个应用商店陆续上线,开发者也可以在百度智能云的千帆平台上调用API接口。
对于像以文心为代表的国产大模型来说,加速技术研发、场景创新是未来不断迭代的方向,进而满足不同行业、不同领域的需求。而“好用”无疑是核心的命题。更强大的文心大模型4.0 Turbo在此时亮相,势必为百度赢来更多机会。
2.三亿用户,AI和人的互动在各个角落悄然发生
今天,大模型市场的热点正在从基础大模型排位赛延伸到围绕AI原生应用的竞赛中。
数据显示,现今,全球市场各类AI项目应接不暇,仅在2023年,GitHub AI项目总数就急剧增长了59.3%。大语言模型交互、智能体、代码生成无疑是三个热门细分方向。
AI和人的互动,无疑将会深刻影响大模型发展方向。
作为大模型竞赛中的翘楚,文心大模型数据表现亮眼。百度集团副总裁、深度学习技术及应用国家工程研究中心副主任吴甜透露,从全面向社会开放之后,文心一言的用户规模持续处于一个快速的增长状态。
“目前,文心一言的用户规模已经达到了3亿。过去半年,文心大模型用户日均提问量增加78%,提问平均长度提升89%。”
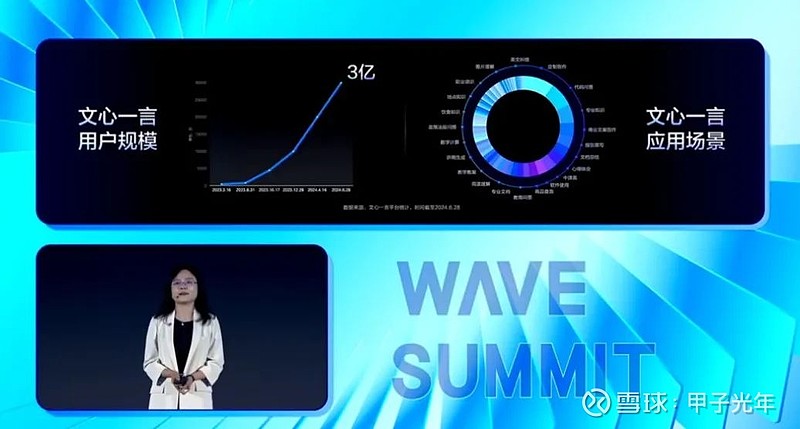
文心一言用户规模数据和应用场景
AI和人的互动在各个角落悄然发生着。文心大模型为用户提供的帮助从简单需求延伸到更多元、复杂的任务。与此同时,文心大模型还支持了大量的应用创新。
在实际生活中,有人和文心一言一起进行小说创作,也有人和文心一言一起冲刺高考,让AI给自己设计各学科的考卷……
截至目前,文心大模型已经生成了70亿行代码,创作了5.9亿篇文章,制作了5000万份PPT,书写了100万篇专业研报。在学习场景中,文心大模型已经帮助用户解答了1.7亿个问题,其中包括2000多万道数学题。数字人主播与用户的互动时长超过了1400万小时。在工作场景中,文心大模型已辅助了1.3亿人次。
这些数据背后意味着文心大模型在大量、多元、复杂的用户交互中,在准确性、实用性和用户体验上不断自我进化。
除了个人用户使用外,大模型的触角已经从广泛的内容创作领域伸展到各行各业。
目前,基于文心一言的应用场景已经过万。比如,在距离人工智能更远的农业上,大模型也有了新的“涉足”。百度发布了中国工程院朱有勇院士及团队与百度共同打造的首个农业智能体——“农民院士智能体”。
它学习了朱有勇院士的研究成果以及相关的农业知识,可以随时随地为农民解答生产生活中的问题。目前,这个智能体可以在文心一言App、百度App、网页端和小度的设备上使用。

百度发布“农民院士智能体”
除了文本生成能力,大模型的代码生成能力对于企业和开发者也是一项重要的功能。
对于开发者而言,能提高开发效率、降低入门门槛、支持多语言编程、自动化重复任务等,提升了编程的便捷性和效率。对于企业而言,可以借助这项能力生成特定领域的定制化代码解决方案,满足特定业务需求,提高生产力。
“Comate”智能代码助手是百度在2023年推出的代码生成应用,可以实现代码的快速补齐、自然语言推荐代码、自动查找代码错误,全面提升开发者效率。开发者可以通过插件等形式,在主流开发软件中使用。
这次大会,“Comate”代码助手官宣全新的中文名——“文心快码”,同时还宣布其在企业全流程的赋能,以及知识增强、企业级安全方面进行了全新的迭代。
拥有新能力的“文心快码”不仅能够全面深入地分析整个代码库,还可以通过整合公认权威的公共与私有领域知识,创造全新的代码。同时,在安全性方面,用户只需简单一键即可采纳或修复,就能够自动检测编码过程中的安全漏洞,并智能提出修复建议。

Comate智能代码助手官宣全新的中文名:“文心快码”
对于企业用户而言,一方面,“文心快码”可以加快开发速度。由于文心快码通过汇集技术专家的经验和研发知识,形成了一个强大的超级助手,能够在开发过程中提供精准及时的帮助。这使得工程师在单位时间内的代码提交数量提升了35%,从而加快了开发速度,缩短了项目完成时间。
另一方面,文心快码还可以加快业务的迭代速度。由于其智能化能力覆盖了整个研发流程,从需求澄清到开发、测试和发布,每个环节都实现了提效。特别是在安全方面,它能够在需求阶段就提醒产品经理注意安全规范,在开发阶段生成更安全的代码,并在测试环节自动检测和修复漏洞,从而加快业务的迭代速度。
除了技术方面的进步,文心快码的行业积累和经验也是一大竞争力。文心快码能够帮助企业快速落地新研发工具。例如,喜马拉雅在一个季度内全面落地文心快码,代码采样率达到了44%。这种快速复制和落地实践,使得企业能够迅速采纳文心快码,实现研发提效。
可见,AI和人的互动不仅发生在每日的学习生活中,还发生在广袤的产业大地上,每一个角落都悄然发生着变化。
3.底层技术再向前
更强大的大模型背后来源于底层技术的不断迭代更新。
一直以来,百度在芯片、框架、模型和应用上都有全栈布局,而飞桨深度学习平台和文心的联合优化为文心大模型的持续进化提供了更强大的动力。为了支撑大模型更进一步迭代,飞桨发布核心框架3.0,专为大模型设计。目前,开发者可以在社区里使用最新版本。
飞桨框架3.0技术架构采用分层设计,划分为适配层、算子层、调度层、表示层,以及顶层的开发接口。和2.0一样,3.0版本在开发接口上保持了完全的兼容性,消除了开发者对于代码需要重写的顾虑。用户可以无缝过渡到3.0版本,并充分利用其新增的强大功能。

百度发布新升级的飞桨框架3.0
作为给文心大模型提供更好的训练以及推理支持的底层技术平台,飞桨围绕以下四个方面进行全方位能力构建,用以更好应对大模型技术发展趋势,以及异构多核处理器的普及:
飞桨框架3.0强化了大模型在训练和推理过程中的集成体验,从而使模型训练和推理部署的过程更加流畅高效;
平台的自动化能力再向前走了一步,尤其在动静统一自动并行和编译器自动化方面。飞桨框架3.0不仅允许开发者在进行大规模模型训练时,框架能够自动处理并行计算的复杂性,还通过编译自动化简化了开发和调优过程,使得性能优化更加高效;
为了确保大模型能够在多种硬件上高效运行,包括CPU、GPU、FPGA等,飞桨3.0进一步增强了对不同硬件平台的适配能力。硬件厂商只需适配基础算子,大幅减少了开发工作量。
同时,飞桨的适配层进行了大量软硬件协同优化工作,包括高效算子的流水编排和硬件代码的编译等,从而实现更好的性能优化。
其中,训练和推理的一体化设计对于大模型的发展至关重要。
一方面,它不仅提升了开发和部署的效率,确保了模型在不同阶段的一致性,还优化了成本并加快了迭代速度。另一方面,这种设计简化了开发流程,降低了技术门槛,使得模型的端到端优化成为可能,在提高运行效率和性能的同时,改善了用户体验,为特定应用场景提供了灵活性。
这也是飞桨框架3.0的一大亮点。新升级的飞桨框架3.0允许动态图自动转换成静态图进行性能调优,使得训练、压缩和推理过程无缝衔接。在大模型训练过程中(尤其是人类反馈强化学习训练中),可以调用高性能推理算子。同时,通过复用分布式训练策略,量化过程的效率提升了3倍,显著提高了整体流程的效率。
飞桨的进阶,是百度技术向前的一大步,也是中国大模型创新的关键一步。
如今,通用大模型之间的能力竞赛如火如荼,飞桨的全面升级,不仅给百度在大模型战略布局上提供了更坚实的技术基础,也成为进一步支撑中国大模型建设走向应用的关键力量。
4.大模型生态效应圈
大模型不是少数人的游戏,而是一片需要各行各业的力量都参与构建的生态雨林。这一过程中,不论是企业还是研究机构,亦或是开发者,都需要依靠生态的力量进行资源共享、应用落地、多样化场景,才有可能让高成本、高难度的大模型技术降低成本、惠及千行百业。
大型科技公司是这场“大模型生态雨林”共创牌局中的关键参与者,一方面,他们有先进的硬件设施和强大的云计算平台,为大模型训练和推理提供必需的基础设施;另一方面,他们有更丰富的资源和工具平台,能提供更多应用场景落地经验和全面的工具支持。
就像这次,百度不仅在大模型技术和应用方面进行了最新升级,同时也在持续推进大模型生态建设,逐渐形成大模型生态效应圈。
去年,百度发起了文心大模型星河共创计划,将大模型资源和产业生态资源进行互动与链接。经过一年的发展,目前百度已与众多合作伙伴、开发者一起,共创了55万AI应用、1000个以上大模型工具,覆盖生活、图像、思维和管理等多个工具领域。此外,百度与上海辞书、维普等机构合作,共创了超过1000B的高质量稀缺数据,激活了各行各业中的数据资源。
如今,大模型正在试图走向更深、更远的产业带,与医疗、金融、教育、制造等行业碰撞更多的火花。
除此之外,文心大模型生态也正在和软件、硬件等各类生态伙伴合作,通过平台建设,为用户提供更丰富的大模型使用方法,联合打造一系列新的AI应用。
比如,国内首个体育大模型就是百度与上海体育大学在体育科技方面开展的共研共创应用,包括辅助设备数据运用、互联设备空间计算、运动员动作技巧与战术分析、以及数字化媒体传播等。
上海体育大学“长江学者”特聘教授、美国国家体育科学院院士刘宇透露,目前,上体体育大模型与相关联合科研团队正在服务游泳、田径、体操、蹦床、攀岩等多支国家队备战巴黎奥运会。
各行各业正在以开放的姿态拥抱大模型。制造领域,大模型正在探索智能制造、预测性维护和供应链优化等方面的应用,提高生产效率和管理水平;教育行业,大模型特在为个性化学习、智能辅导和教育资源优化提供支持,推动教育公平和质量提升;金融机构通过大模型优化风险管理、提升客户服务并进行智能投顾,实现了更为精准的市场分析和客户需求匹配。
现如今,随着这些现实中正在发生的落地实践,百度大模型生态圈正在日益扩大。飞桨文心生态也在持续壮大,目前累计拥有1465万名开发者,支持了37万家企业,并创建了95万个模型。
此刻,沐浴在通用人工智能的曙光之下,像百度一样的大模型积极拥抱者正在携手探索AI未来的无限可能。
(封面图来源:摄图网)
END.
