人形机器人作为一个大的赛道,公众号也前前后后写了40多篇各模块及代表公司的分析对比文章,今天一起跟大家分享人形机器人大模型情况,如有对人形机器人相关产业链的公司感兴趣可以查看我的公众号主页下栏文章列表或直接点击最近几篇的文章链接参考如下,有志于人形机器人交流的小伙伴可以关注公众号一块交流分享人形机器人产业链发展和机会:
第二十五篇:人形机器人离商业化还有多久?从企业机器换人的回本周期预测推演
第四十五篇:揭秘:人形机器人核心部件之国内外头部空心杯电机参数大比拼
引言:在人工智能的浪潮下,人形机器人以其独特的魅力和广泛的应用前景,成为了科技领域的热点。然而,尽管市场需求巨大,人形机器人的商业化之路却步履蹒跚。本文将探讨人形机器人在商业化过程中面临的通用性挑战,并分析大模型如何成为解决这一问题的关键。
一、人形机器人商业化的痛点:通用性受限
1、通用性受限的挑战:
通用性是人形机器人商业化的关键。然而,当前的人形机器人往往需要高度专业化的用户操作,且只能在特定场景下工作。这种局限性使得人形机器人难以适应多变的现实世界,从而限制了其商业化的可能性。
来源:On the Opportunities and Risks of Foundation Models
二、机器人大模型在通用性拓宽方面扮演的角色
1、硬件与软件的不同步问题
在人形机器人的发展中,硬件的进步为人形机器人提供了强大的物理基础。然而,软件的升级才是实现商业化的关键。软件的智能化,尤其是大模型的应用,能够使机器人更好地理解和适应环境,从而实现更广泛的应用。
例如波士顿动力的Atlas 通过电液混合驱动结合 IMU、编码器、摄像头、激光雷达和力传感器实现了跳越、后空翻等高难度动作,在运动能力上绝对是行业标杆,但这些动作都源自提前创建的行为库,并没有真正适配的软件方面的大模型来做智能化通用化的适配。
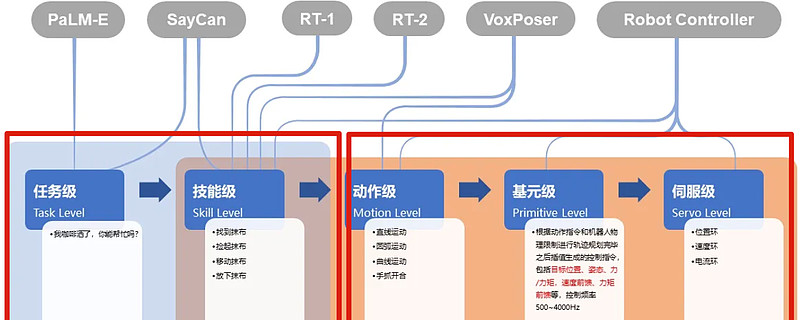
2、机器人的大脑与小脑:
在机器人的控制系统中,大模型扮演着“大脑”的角色,负责高层次的任务规划和决策。而“小脑”则负责低层次的运动控制。这种分层的控制策略,使得人形机器人能够在复杂环境中灵活地执行任务。
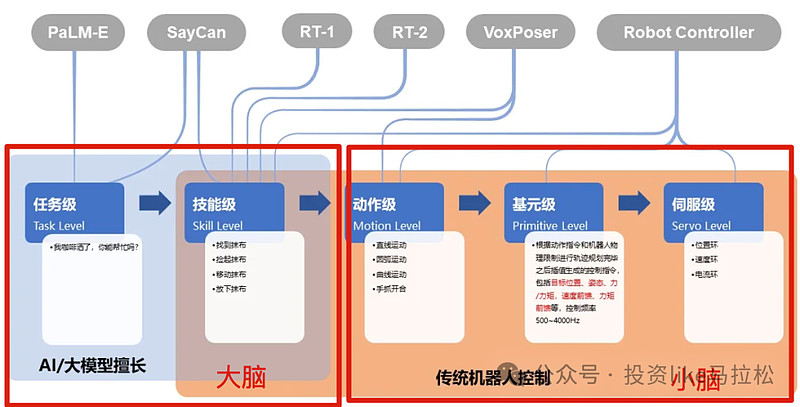
来源:珞石机器人 韩峰涛
3、人形机器人大模型的理想大脑:
大模型通过深度学习和强化学习,能够理解和执行复杂的任务。它们不仅能够处理视觉和语言信息,还能够理解物理世界的基本规律。这种强大的泛化能力,使得人形机器人能够在多种场景中执行任务,极大地提高了其通用性。
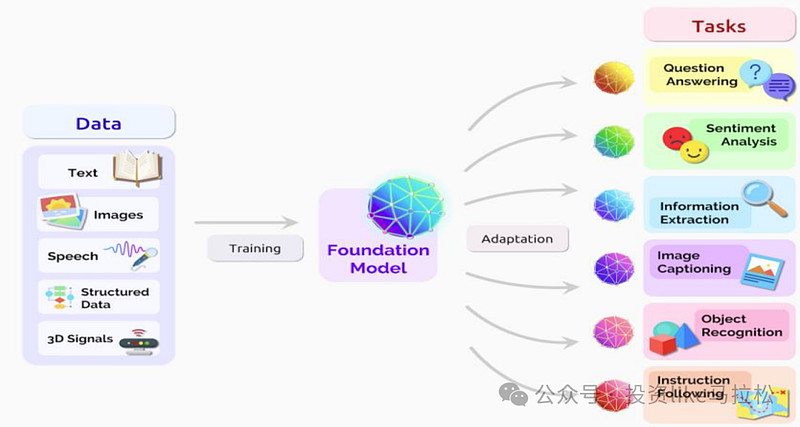
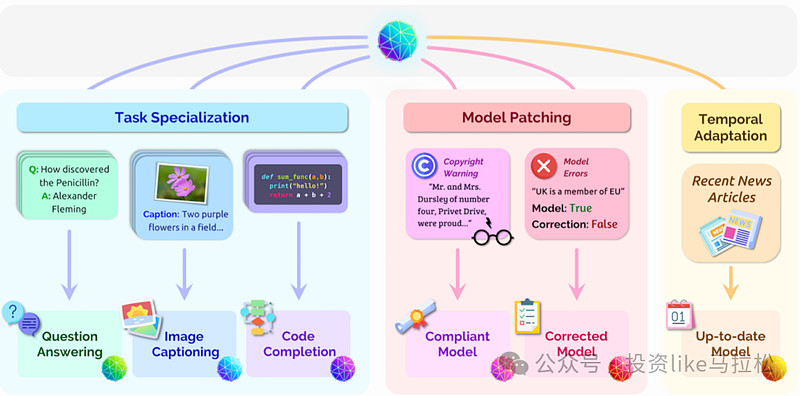
来源:On the Opportunities and Risks of Foundation Models
三、人形机器人大模型的需要具备的关键能力
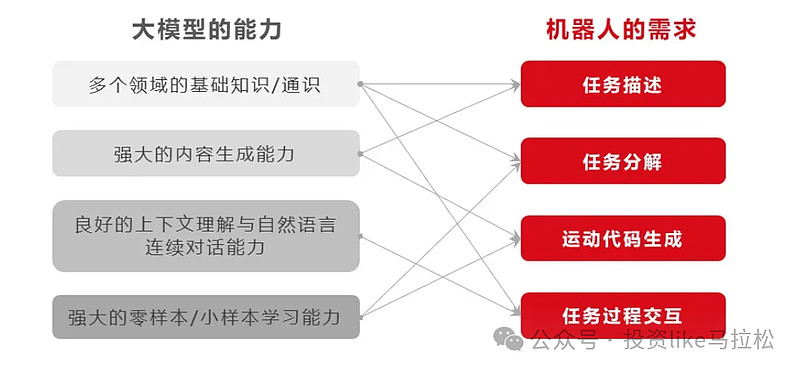
机器人大模型的最终目标是提高人形机器人在不同场景和任务下执行的成功率。对于限定的应用场景和任务,大模型需要具备自主可靠决策能力、多模态感知能力和实时精准运控能力;为了拓展到多样复杂的应用场景和任务,大模型还需要具备泛化能力和涌现能力。
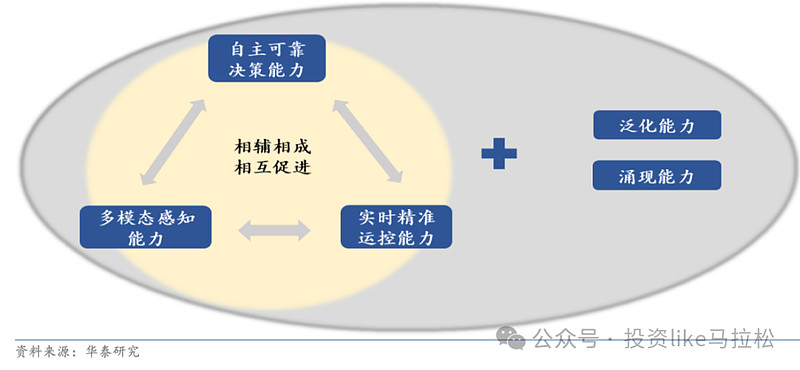
1、多模态感知能力:
为了在复杂环境中做出正确决策,人形机器人需要能够通过视觉、听觉、触觉等多种感官获取信息。大模型需要整合这些多模态感知数据,以实现对环境的全面理解。
2、自主可靠决策能力:
人形机器人在执行任务时,需要能够理解任务的复杂性,并将其分解为一系列可执行的子任务。这要求大模型具备强大的语言理解能力和对物理世界的深刻理解。例如,机器人可能需要理解“清理房间”这一任务,包括识别哪些物品需要移动,哪些需要丢弃。
3、实时精准运控能力:
在执行任务时,人形机器人需要实时调整其动作以适应环境变化。这要求大模型能够快速处理感知信息,并精确控制机器人的运动。例如,机器人在行走时需要实时调整步伐以避免障碍物。
4、泛化能力:
大模型需要能够在未见过的新环境中执行任务。这意味着模型不仅要在训练数据上表现良好,还要能够适应新的、未知的情况。
5、涌现能力:
除了在训练数据上的表现,大模型还应展现出超出训练范围的执行能力。这种能力使得机器人能够在面对新挑战时,展现出创新的解决方案。
四、人形机器人相关大模型介绍
人形机器人大模型当面国外主要是以谷歌DeepMind为主的RT相关的模型及特斯拉、英伟达、VoxPoser在机器人方面的布局,国内厂家主要以华为、中科院及科大讯飞等国内有大模型及硬件布局能力的厂家为主。
1、AutoRT:
由谷歌DeepMind提出的AutoRT系统,结合了大型基础模型(如大型语言模型LLM或视觉语言模型VLM)和机器人控制模型(如RT-1或RT-2),用于在新环境中部署机器人并收集训练数据。
2、PaLM-E:
PaLM-E是由谷歌DeepMind开发的大型多模态模型,它结合了强大的语言模型PaLM和视觉模型ViT。PaLM-E拥有5620亿参数,这使得它在处理语言、视觉和视觉语言任务时表现出色,并且在OK-VQA(Open-Domain Visual Question Answering)任务上达到了最先进的性能。其主要功能包括:1)自主决策: PaLM-E能够理解复杂的自然语言指令,并将其转化为具体的行动计划。2)多模态感知: 模型能够处理和理解图像和文本信息,实现跨模态的理解和推理。
来源:PaLM-E: An Embodied Multimodal Language Model
3、RT-2:
RT-2是DeepMind开发的端到端机器人具身大模型,它基于Transformer架构,模型是一个VLA(视觉-语言-动作)模型,它将自主决策、多模态感知、实时精准运控等多种能力有机结合,提高了机器人的整体性能。其主要功能:1)VLA(视觉-语言-动作):RT-2能够理解视觉信息,处理自然语言指令,并执行相应的动作。2)多能力结合: RT-2将视觉理解、语言处理和动作执行等多种能力有机结合,提高了机器人的智能水平。
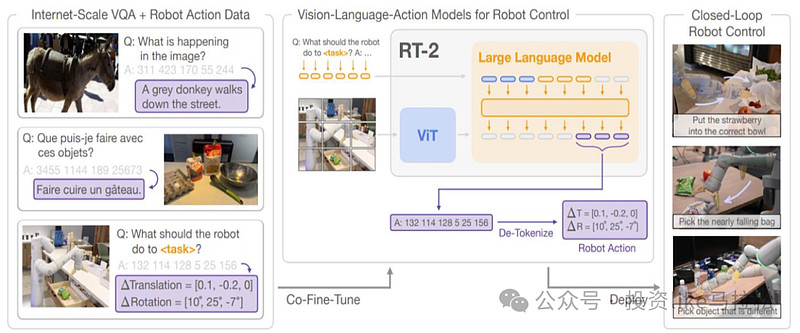
来源:RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
4、RT-X:
RT-X是DeepMind开发的机器人模型,它在多个数据集上进行了训练,以全面提升其能力。RT-X在视觉理解、语言处理、动作执行等方面都有所增强。模型经过多个数据集的训练,全面提升了多模态感知、自主可靠决策、实时精准云控能力以及泛化和涌现的能力。它代表了当前人形机器人大模型的最高水平,预示着未来机器人的发展方向。其主要功能包括:1)RT-X在多个任务上表现出更高的性能,包括视觉识别、语言理解、动作规划等。2)泛化能力: 经过多个数据集的训练,RT-X在新任务和新环境中的适应能力得到增强。
来源:Open X-Embodiment: Robotic Learning Datasets and RT-X Models
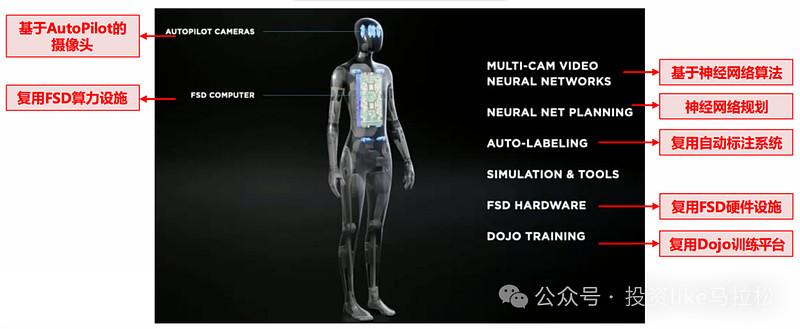
5、特斯拉的人形机器人大模型:
特斯拉在大模型领域的布局主要体现在其名为Optimus的人形机器人项目上。Optimus采用了与特斯拉汽车一致的计算机视觉、处理视觉数据、做出行动决策、支持通信交流的“大脑”,以及与特斯拉车辆相同的芯片。特斯拉正在利用其在自动驾驶技术上的积累,将其应用于人形机器人的开发。
在大模型的具体应用上: 特斯拉会将FSD系统中使用的大模型核心技术能力应用于Optimus,使其具备高级的感知、决策和执行能力。包括使用类似于DOJO的计算资源来训练和优化Optimus的AI模型。
6、VoxPoser大模型:
Google系的几个机器人大模型,总体思路都是侧重于任务理解、拆分和逻辑推理,对于机器人运动控制本身尤其规划问题涉及较少,只是用端到端训练的方式生成了简单且离散分布的机械臂末端位置和底盘移动指令,未考虑连续路径和轨迹规划等更偏机器人领域的内容。
VoxPoser是使用VLM和VLM的能力来将机器人的观测空间(一般为三维空间和待操作的对象)转换为一个3D值图,然后就可以使用成熟的路径搜索算法(VoxPoser使用了概率路线图Probabilistic RoadMap)在3D值图上搜索生成可用的机器人运动路径。有了可用路径,接下来做轨迹规划和控制机器人运动就是当前机器人领域解决的比较好的问题了。

来源:Composable 3D Value Maps for Robotic Manipulation with Language Models
7、NVIDIA ISAAC机器人平台(重要但非大模型)
确切的说NVIDIA ISAAC是一个开放式AI平台而不是大模型,是专为机器人设计,提供了大量的GPU加速算法和深度神经网络(DNN)模型。NVIDIA Isaac是一个集成了多种技术的平台,它提供了包括机器人操作系统(ROS)、人工智能(AI)框架、模拟工具、预训练模型和各类软件工具在内的全面解决方案,以支持机器人技术的开发和应用。Isaac平台支持大模型的训练和应用。
其功能分类:
1)3D物体姿态估计:ISAAC平台提供了精确的DNN模型,包括对象检测、3D姿态估计和使用深度传感器数据的姿态优化。这使得机器人能够在仓库等环境中进行高效的物体识别和操作。
2)导航与规划: ISAAC集成了多项操作、导航、规划和本地化新功能,使机器人能够在复杂环境中自主导航和执行任务。
3)实时仿真: Isaac Sim提供了一个强大的仿真环境,允许开发者在虚拟环境中测试和优化机器人的行为,从而减少实际部署时的风险和成本。
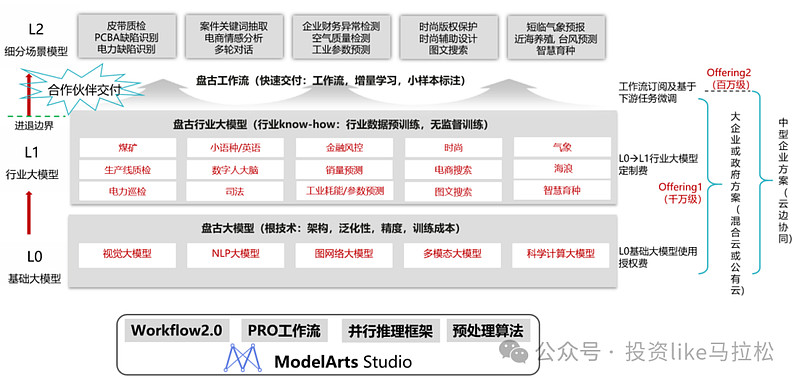
8、华为盘古大模型:
华为本身在自动驾驶方面拥有全行业领先的软硬件一体解决方案,同时华为推出了“盘古”大模型,华为的盘古大模型是一个面向行业的大模型系列,包括了多个层级和多种应用领域。盘古大模型的结构分为三层:L0层包括五个基础大模型,即自然语言、视觉、多模态、预测、科学计算大模型;L1层是行业大模型,涵盖政务、金融、制造、矿山、气象等多个领域;L2层则提供了更多细分场景的模型,如政务热线、网点助手、先导药物筛选等,但其强大的计算能力和多模态数据处理能力也为机器人大模型的开发提供了基础。
再者华为在23年发布的的机器人云平台,这是一个集成了人工智能、云计算和机器人技术的高度综合性的平台。这个平台的主要特点包括云原生机器人数据闭环系统、端云协同智能流程机器人方案,可以针对不同应用场景的定制化解决方案,相信在机器人领域也会有不错的表现。
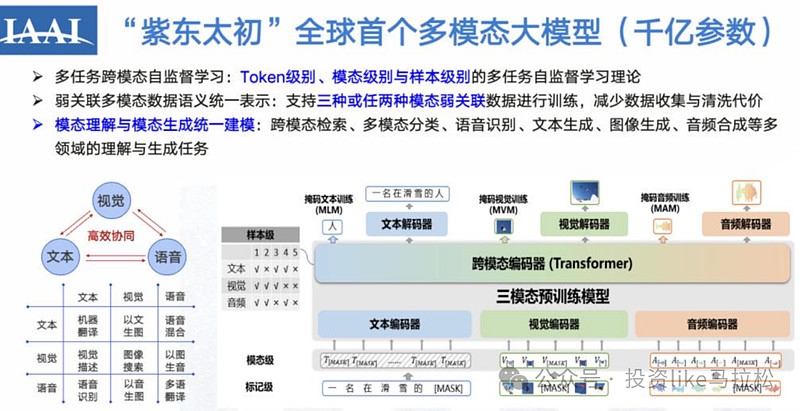
9、中科院紫东太初大模型:
中国科学院在机器人和机器人相关的大模型领域布局表现出色,特别是在其研发的“紫东太初”大模型是中国科学院自动化研究所研发的千亿参数三模态大模型,后来升级为全模态大模型。这个模型能够理解并处理语音、图像、文本等多种模态的数据,进而实现更接近人类智能的认知和决策能力。
紫东太初大模型采用了国产化基础软硬件平台昇腾AI,其算法由中科院自动化研究所自主研发。该模型不仅可以处理传统的图像和文本数据,还能理解视频、信号、3D点云等更复杂的数据类型。紫东太初大模型在神经外科手术导航、短视频内容审核、法律咨询、医疗多模态鉴别诊断、交通违规图像研读等多个领域展现了广泛的应用前景。例如,在医疗场景下,该模型可以与神经外科机器人MicroNeuro结合,实现术中实时融合视觉、触觉等多模态信息,协助医生进行手术。
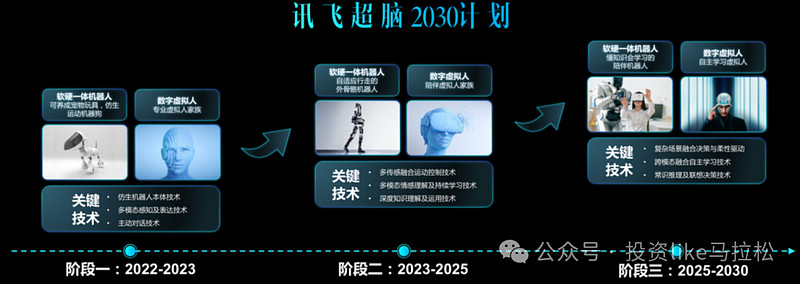
科大讯飞本身在语音识别和自然语言处理领域有着领先的技术,其大模型可以用于机器人的语音交互和理解。其拥有强大的自然语言处理(NLP)能力、多模态感知能力、深度学习和认知智能、具身智能、强化学习以及系统集成等方面具有明显优势,这些优势为其在人形机器人大模型构建上提供了坚实的基础。
科大讯飞的“讯飞超脑2030计划”提出了将认知智能、具身智能和运动智能结合起来的目标。这意味着科大讯飞的人形机器人大模型将具备在物理世界中导航、操作物体和执行复杂动作的能力。同时科大讯飞在人形机器人的研发过程中与宇树科技等合作伙伴共同研发,推进“视觉-语言-动作”多模态具身智能大模型的发展。这有助于构建一个支持人形机器人发展的生态系统,包括硬件供应商、软件开发商和行业应用合作伙伴。
五、人形机器人大模型的不足与未来展望
人形机器人作为人工智能的前沿领域,其发展速度令人瞩目。然而,要实现真正的智能化和自主化,现有的大模型仍需在多个方面进行改进。
来源:珞石机器人 韩峰涛
1、感知模态的局限性与多模态感知的发展趋势
1)感知模态的不足:
当前的人形机器人大模型主要依赖于视觉感知,这种单一的感知模态在处理复杂环境时显得力不从心。例如,在嘈杂的环境中,仅凭视觉信息,机器人可能难以准确识别和响应。
2)多模态感知的未来:
为了克服这一局限,未来的大模型需要整合视觉、听觉、触觉等多种感知模态。多模态感知能够提供更丰富的环境信息,使机器人在复杂场景中做出更准确的决策。例如,结合听觉和触觉信息,机器人可以更好地理解人类的指令和情感状态。
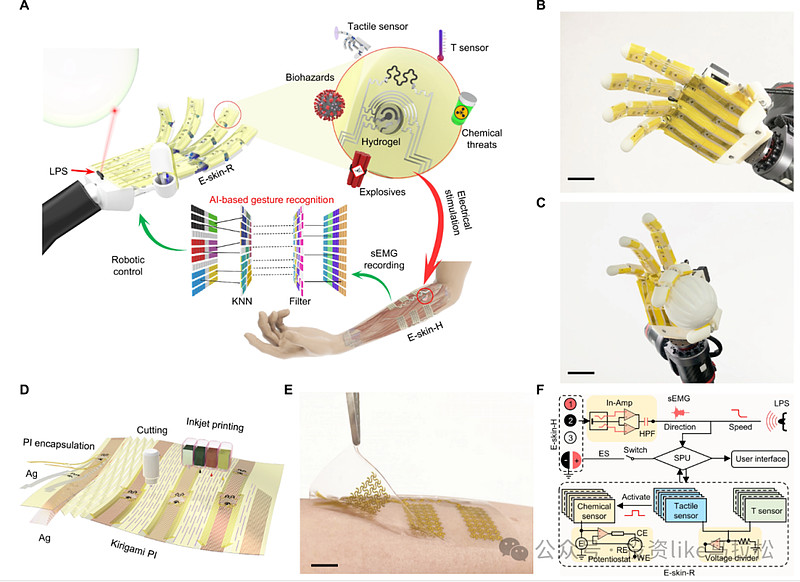
2、指令生成速度与复杂性的问题
现有的大模型在生成指令时速度较慢,且生成的结果往往过于简单。这在需要快速反应的场景中,如紧急救援或复杂操作任务,可能导致机器人无法及时作出正确响应。目前主流机器人大模型偏向于任务理解和拆分,对于机器人运动控制的涉及较少,只是用端到端的训练方式生成了简单且离散分布的机械臂末端位置和底盘移动指令,未考虑连续路径和轨迹规划等更偏机器人领域的内容。
3、泛化能力的提高与模型架构的改进
1)泛化能力的不足:
泛化能力是大模型在新环境和新任务中表现的关键。当前的模型在泛化能力上仍有待提高,尤其是在面对未知环境和任务时,模型的表现往往不尽人意。
2)模型架构与方法的创新:
为了提高泛化能力,未来的大模型需要在架构、训练方法和数据集方面进行创新。例如,通过引入元学习、迁移学习等技术,可以使模型更好地适应新任务。同时,构建更多样化的数据集,也有助于模型学习到更广泛的知识。
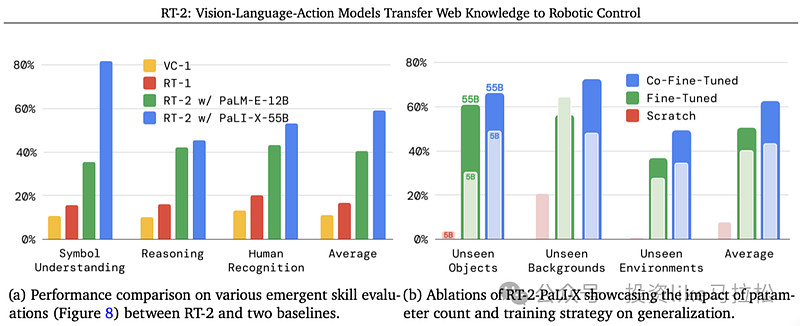
结论:
人形机器人大模型的发展正处于关键时期。但随着技术的不断进步,我们有理由相信,未来的大模型将更加智能、高效和通用性更强。这不仅将推动人形机器人在各个领域的应用,也将为具身智能和人工智能的发展开辟新的道路。
人形机器人或者说具身智能目前还在产业发展从0-1的阶段,更多的还是对行业相关技术能力的公司进行了解分析为后面布局安排,我们也欢迎机器人行业从业者和对人形机器人有一定理解的志同道合的朋友一块交流分享,谢谢。