AI创投周报是阿尔法公社推出的聚焦于以生成式AI为代表的人工智能新浪潮的创投资讯周报。阿尔法公社发现和投资非凡创业者(Alpha Founders),相信非凡创业者们在技术、商业和社会方面的巨大推动力,他们指引着创投生态的风向。

本图由“千象”(网址:网页链接)生成
本周,我们观察到以下AI领域的新动向和新趋势:
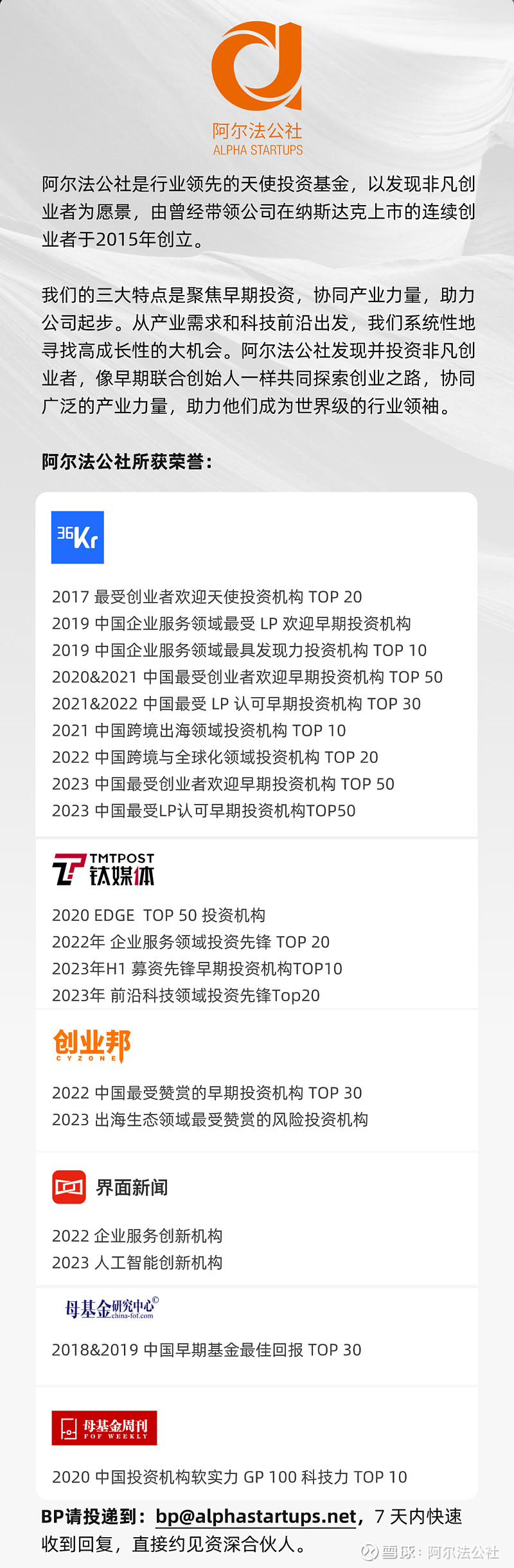
1.Anthropic发布全新大模型Claude 3.5 Sonnet,性能超越GPT-4o,Claude 3.5 Sonnet的运行速度是前代Claude 3 Opus的两倍,且成本仅为其五分之一,目前已在Claude.ai和iOS应用程序上免费提供。
2.OpenAI前首席科学家Ilya Sutskever创立SSI,专注安全超级智能,Ilya Sutskever在社交媒体上表示,构建安全的超级智能是当代最重要的技术难题,SSI公司将全力以赴解决这一问题。
3.增强型代码助手Poolside获得4亿美元融资,估值达20亿美元,该公司计划利用新资金进一步推进其AI模型的研发,这些模型能够在自然语言输入的指导下生成复杂的软件代码。Poolside的目标是通过其工具,非专业开发者也可以轻松创建应用程序,从而实现软件开发的普及化。
如果您对人工智能的新浪潮有兴趣,有见解,有创业意愿,欢迎扫码添加“阿尔法小助理”,备注您的“姓名+职位”,与我们深度连接。

人工智能产品和技术的新突破
1.Anthropic发布全新大模型Claude 3.5 Sonnet,性能超越GPT-4o
Anthropic公司近日推出了其大模型系列中的新成员Claude 3.5 Sonnet,这一模型在智能水平上达到了新的高度,成为目前最智能的AI模型之一。Claude 3.5 Sonnet在多项基准评估中超越了竞品大模型,包括OpenAI的GPT-4o,同时在速度和成本上也具有显著优势。该模型不仅在研究生水平推理、本科生水平知识以及编码能力方面设立了新的行业标准,还在理解细微差别、幽默和复杂指令方面表现出了显著的进步。
Claude 3.5 Sonnet的运行速度是前代Claude 3 Opus的两倍,且成本仅为其五分之一,目前已在Claude.ai和iOS应用程序上免费提供。此外,通过Anthropic API和亚马逊云科技Bedrock等渠道,用户可以以每百万输入token 3美元、每百万输出token 15美元的价格使用该模型,上下文窗口支持高达200k token。
Anthropic公司不仅在开发下一代大模型,还在探索新功能,如Memory功能,以实现更加个性化和高效的用户体验。Claude 3.5 Sonnet在视觉模型方面也展现了卓越能力,尤其在视觉推理任务中表现突出,这对于零售、物流和金融服务等行业尤为重要。
此外,Anthropic在Claude.ai上推出了Artifacts功能,允许用户在对话中实时查看、编辑和构建Claude生成的内容,进一步推动了AI向协作工作环境的演变。公司还对Claude 3.5 Sonnet进行了严格的安全测试,确保其在CBRN风险、网络安全等领域的安全性,并与外部专家合作,以提高模型的安全性和透明度。
来源:Anthropic官网
2.OpenAI前首席科学家Ilya Sutskever创立SSI,专注安全超级智能
Ilya Sutskever,OpenAI前首席科学家,宣布成立新公司——安全超级智能(Safe SuperIntelligence,简称SSI)。该公司以追求安全超级智能为唯一目标和产品,致力于通过一支顶尖团队实现革命性突破。SSI公司在美国帕洛阿尔托和特拉维夫设有办事处,旨在招募全球顶尖技术人才,专注于SSI的研发,不受管理开销或产品周期的干扰。
Ilya Sutskever在社交媒体上表示,构建安全的超级智能是当代最重要的技术难题,SSI公司将全力以赴解决这一问题。作为公司的使命、名称和整个产品路线图,SSI是公司唯一的关注点。他们计划在确保安全的前提下,尽可能快速地提升智能水平,以实现和平扩展。
联合创始人Daniel Gross和Daniel Levy也表达了对这一新事业的兴奋与期待。Daniel Gross曾是苹果AI高管和Y-Combinator合伙人,而Daniel Levy则是OpenAI技术团队的前成员。他们认为,与Ilya Sutskever共同开启这一新事业是一种荣誉。
Ilya Sutskever的背景同样引人注目。他曾与深度学习先驱Geoffrey Hinton合作,参与了AlexNet的开发,该项目标志着深度学习的突破。此后,他在谷歌担任研究科学家,参与了TensorFlow的研究,并是AlphaGo论文(Mastering the game of Go with deep neural networks and tree search)的作者之一。2015年,他加入OpenAI,并在GPT系列模型的发展中发挥了重要作用。
尽管ChatGPT取得了巨大成功,Ilya Sutskever和其他OpenAI成员对AI的可控性问题表示担忧,这促使他离开OpenAI,创立SSI公司。SSI公司的理念是将安全性和能力同步提升,通过革命性的工程和科学突破来解决技术难题,为人工智能的未来发展带来新的希望和方向。
来源:X
3.阿里云推出首个 AI 程序员,具备架构师、开发 / 测试工程师等岗位
在阿里云上海 AI 峰会上,阿里云推出首个“AI 程序员”,具备架构师、开发工程师、测试工程师等岗位技能,能完成任务分解、代码编写、测试、问题修复、代码提交整个过程,号称最快“分钟级”完成应用开发。在收到用户需求后,“AI 程序员”就可实现软件开发“一条龙”:理解需求-拆分任务-编写代码-识别并解决报错-提交代码。
来源:阿里巴巴
4.阿里通义Qwen2成斯坦福大模型榜单最强开源模型
斯坦福大学的大模型测评榜单HELM MMLU发布最新结果,斯坦福大学基础模型研究中心主任Percy Liang发文表示,阿里通义千问Qwen2-72B模型成为排名最高的开源大模型,性能超越Llama3-70B模型。
MMLU(Massive Multitask Language Understanding,大规模多任务语言理解)是业界最有影响力的大模型测评基准之一,涵盖了基础数学、计算机科学、法律、历史等57项任务,用以测试大模型的世界知识和问题解决能力。但在现实测评中,不同参评模型的测评结果有时缺乏一致性、可比性,原因包括使用非标准提示词技术、没有统一采用开源评价框架等等。

来源:阿里巴巴
5.吴恩达团队新作:多模态多样本上下文学习,无需微调快速适应新任务
在近期的多模态基础模型(Multimodal Foundation Model)研究中,上下文学习(In-Context Learning, ICL)已被证明是提高模型性能的有效方法之一。然而,受限于基础模型的上下文长度,尤其是对于需要大量视觉 token 来表示图片的多模态基础模型,已有的相关研究只局限于在上下文中提供少量样本。令人激动的是,最新的技术进步大大增加了模型的上下文长度,这为探索使用更多示例进行上下文学习提供了可能性。基于此,斯坦福吴恩达团队的最新研究——ManyICL,主要评估了目前最先进的多模态基础模型在从少样本 (少于 100) 到多样本(最高至 2000)上下文学习中的表现。通过对多个领域和任务的数据集进行测试,团队验证了多样本上下文学习在提高模型性能方面的显著效果,并探讨了批量查询对性能和成本及延迟的影响。
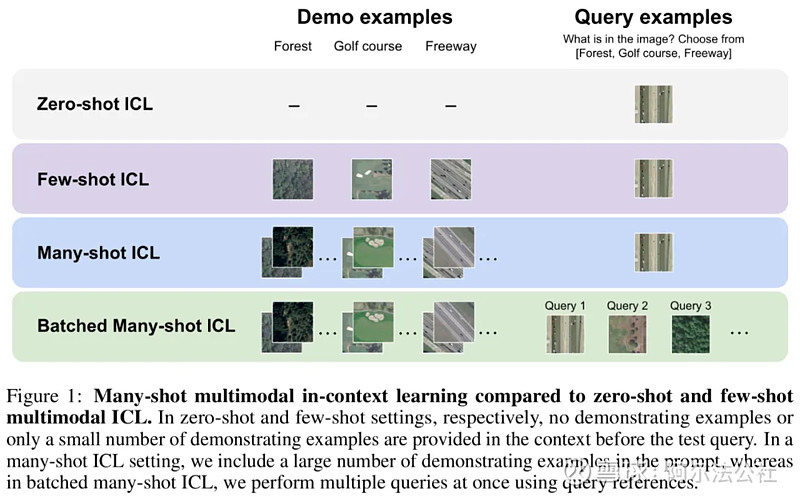
来源:网页链接
6.华人团队推出自增强技术CSR,突破多模态大模型瓶颈
多模态大模型在不同模态对齐时面临诸多挑战,如幻觉问题和细粒度感知不足。传统学习方法依赖外源数据,不仅成本高昂,且质量和多样性难以保证。针对这些问题,来自UNC-Chapel Hill、芝加哥大学、马里兰大学和罗格斯大学的研究团队联合推出了Calibrated Self-Rewarding(CSR)框架。该框架通过自我增强学习,利用模型自身输出构造更可靠的偏好数据,结合视觉约束来提高学习效率和准确性。
CSR框架的核心在于模型在beam search过程中的输出,通过自我生成概率和视觉约束奖励进行校准,形成偏好数据对。这些数据对在线通过DPO迭代学习,相较于传统数据驱动的偏好学习对齐方法和模型自我反馈方法,CSR在多个基准测试中显示出显著的性能提升。实验结果表明,CSR技术能够有效减少幻觉问题,并且随着多轮在线迭代,模型的自我能力逐步提升,表现在多个benchmark上的均分逐步提高。
值得注意的是,CSR框架不仅适用于特定的模型,而是具有普适性,能够应用于其他模型,如Vila。通过可视化分析,我们可以看到经过CSR迭代后的模型输出,其正样本和负样本的gap更小,模型的response更加符合图像信息,同时能缓解文本attention中存在的上下文依赖问题。这一突破性技术为多模态大模型的发展提供了新的可能性,有望进一步推动人工智能领域的进步。
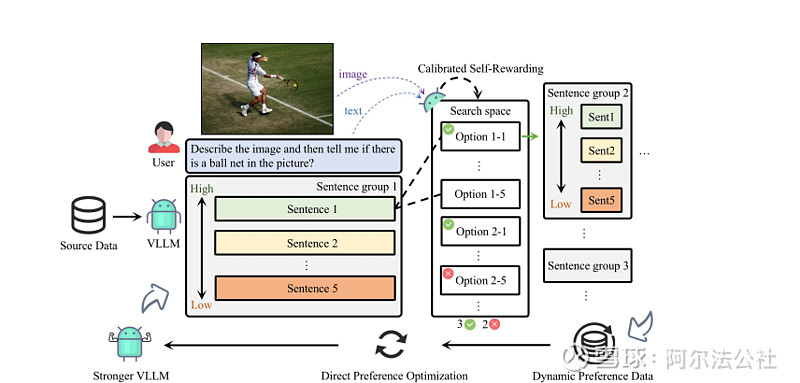
来源:网页链接
7.无问芯穹Qllm-Eva提出大模型压缩量化方案:多模型、多参数、多维度
大型语言模型(LLMs)在各种基准测试中表现出色,但巨大的参数量带来了高昂的服务成本。大模型压缩旨在减少模型的存储、访存和计算开销,使其适用于资源受限的场景,如物联网边缘设备和离线移动应用。清华大学电子工程系、无问芯穹和上海交通大学的研究团队进行了一项量化方案的综合评估,其成果《Evaluating Quantized Large Language Models》(Qllm-Eval)已被ICML'24接收。
Qllm-Eval项目对不同模型、不同张量类型、不同量化方法在不同任务上的性能进行了深入分析,提供了量化方案选择的指导。研究指出,大型模型对权重和键值缓存(KV Cache)量化的容忍度较高,而对激活量化的容忍度较低。此外,不同模型对量化的敏感性也因数据分布不同而有显著差异。在量化位宽选择上,W4、W4A8、KV4、W8KV4等量化位宽对多数基本自然语言处理任务几乎没有性能损失。
研究还发现,专家混合(MoE)技术虽然可以提高模型性能,但并不提高量化容忍度。在任务层面,多步推理和自我校准能力对量化的容忍度较低,而对话任务在量化位宽降低时首先出现句子级重复,随后是Token级重复和随机性。长文本任务对权重和KV Cache量化的容忍度更低,推荐使用W4、W4A8、KV8量化位宽。
Qllm-Eval项目不仅提供了量化效果的系统总结,还提出了应用量化技术的建议,并指出了未来发展方向。项目还包括了对不同量化张量类型、量化方法的评估,以及对大模型推理过程的分析,如Prefill阶段和Decoding阶段的计算速度和存储开销。此外,项目还提供了大量实验数据和绘图工具,以支持模型量化工作的实践和研究。
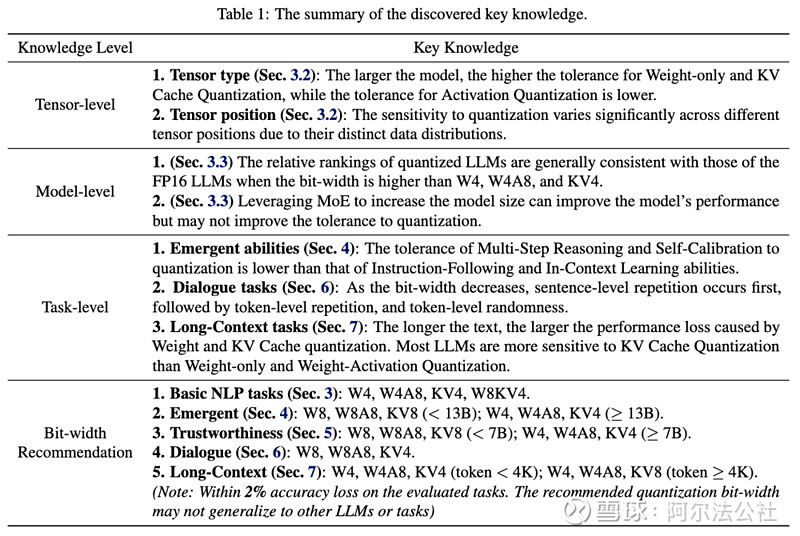
来源:网页链接
8.Runway发布Gen-3 Alpha,引领视频生成技术新高度
AI视频生成公司Runway推出其最新视频生成基础模型Gen-3 Alpha,以其高保真度、超强一致性和精细细节处理能力震撼业界。Gen-3 Alpha能够创造出具有复杂场景变化和多种电影风格的作品,标志着该公司在视频生成技术方面迈出了重要步伐。作为即将推出的系列模型中的首个,Gen-3 Alpha在保真度、一致性和动态表现上均较前代Gen-2有显著提升,为构建通用世界模型奠定了基础。
Runway在博客中强调,所有Demo视频均为Gen-3 Alpha生成,且未经过任何修改,这一声明引起了网友们的广泛关注和赞誉。Pytorch负责人Soumith Chintala甚至认为,其中一些生成质量达到了Sora级别,尽管他也表示希望看到该模型在处理大量人群或拥挤街道场景时的表现。
Gen-3 Alpha的特点包括细粒度的时序控制,能够实现富有想象力的场景过渡;在生成逼真的人类角色方面表现出色,能够创造具有多种动作、手势和情感的表达性角色;以及对艺术创作和电影术语的理解,能够诠释不同的艺术风格。此外,Runway还表示Gen-3系列模型的定制化能够实现更加风格化的控制和一致的角色,满足特定的艺术和叙事要求。
尽管目前许多视频生成模型尚未对公众开放体验,但可以预见,随着技术的发展和迭代,视频生成模型将越来越普及,人们将有更多机会自由尝试这些创新产品。Runway的Gen-3 Alpha无疑为视频生成领域树立了新的标杆,引领着行业向更高层次的发展。
来源:X

人工智能初创公司的新融资
1.增强型代码助手Poolside正在获得超4亿美元融资,估值达20亿美元
官方网站:网页链接
AI创业公司Poolside正在获得超4亿美元融资,估值达到20亿美元,在此之前,它已获得1.26亿美元融资。此轮融资的领投方尚未明确透露,可能为Bain Capial和DST Global,这表明市场对其创新技术的高度认可。Poolside专注于开发一个增强型编码助手,旨在利用人工智能大幅提升软件开发效率。
该公司计划利用新资金进一步推进其AI模型的研发,这些模型能够在自然语言输入的指导下生成复杂的软件代码。Poolside的目标是通过其工具,非专业开发者也可以轻松创建应用程序,从而实现软件开发的普及化。
此外,Poolside正在与云计算提供商合作,建立强大的GPU训练集群,以支持其大规模数据训练需求。这不仅有助于提升AI模型的性能,还表明了其对高性能计算资源的投入。
Poolside的技术不仅适用于专业开发者,还能为教育和医疗等领域的非专业人员提供定制化软件解决方案,使他们能够根据具体需求生成所需应用。这种创新性工具的普及,预计将显著降低软件开发的门槛,推动各行业的数字化进程。
此次融资也反映出AI领域基础技术开发的高成本,Poolside将利用新资金进一步扩展其技术和市场影响力。在全球AI技术竞争日益激烈的背景下,Poolside的这一举措无疑为其未来发展奠定了坚实基础。
2.Finbourne融资7000万美元,助力金融数据转化为AI金矿
官方网站:网页链接
Finbourne Technology,一家专注于金融服务的数据管理平台公司,近日成功筹集了7000万美元的B轮融资,旨在将金融数据转化为AI驱动的解决方案。此轮融资由Highland Europe和AXA Venture Partners(AVP)共同领投,旨在推动Finbourne的全球扩展和技术创新。
Finbourne成立于伦敦,其核心产品是一个云原生的数据管理平台,名为LUSID。该平台提供从前台到后台的完整功能,包括投资组合管理、基金会计、订单管理和合规性等。LUSID平台通过数据授权、血统和使用指标等功能,实现了数据的民主化管理,同时为AI和机器学习编程生态系统提供支持,从而大大提高了运营效率和决策能力。
此次筹集的资金将用于扩展Finbourne在美国、英国、爱尔兰、新加坡和澳大利亚的销售、产品和市场能力。公司计划利用这些资金进一步提升其在全球投资管理、银行和资本市场中的影响力,帮助更多企业获取和利用可信且综合的金融数据视图。
过去一年中,Finbourne已赢得了包括Northern Trust、Omba Advisory和Pension Insurance Corporation(PIC)在内的多个全球投资管理客户。Finbourne的首席执行官兼联合创始人Thomas McHugh表示,此次融资和顶级投资者的支持将有助于公司实现其增强的市场战略,并在关键细分市场中进行重大投资,从而进一步扩大业务范围和客户基础。
3.GrayMatter Robotics筹集4500万美元以推动基于物理模型AI的制造机器人
官方网站:网页链接
GrayMatter Robotics成功筹集了4500万美元,以加速其基于物理模型的人工智能在制造业中的应用。此次融资由Bow Capital和Lux Capital领投,其他参与者包括Clear Ventures、Stage Venture Partners和Calibrate Ventures。GrayMatter的技术通过将AI与物理模型相结合,提高制造过程中的效率和精确度,解决了许多传统制造方法中的瓶颈问题。
GrayMatter的核心产品是一系列智能机器人,这些机器人能够自动执行复杂的制造任务,例如打磨、抛光和喷涂。这些机器人不仅能显著提高生产速度,还能大幅减少材料浪费。例如,一个客户使用GrayMatter的打磨机器人,将原本1小时的手工打磨时间缩短到了6分钟,并节省了30-50%的耗材。
此外,GrayMatter的解决方案还大大简化了操作人员的培训过程。传统上,需要4-6个月的培训时间才能使新操作员熟练掌握技能,而GrayMatter的系统只需一天即可完成这一培训。这种大幅缩短的培训时间,以及高效的生产力提升,使得GrayMatter的机器人解决方案在各行业中得到了广泛应用,包括航空航天、海洋船舶制造、特种车辆、消费品以及通用制造等。
GrayMatter的首席执行官Ariyan Kabir表示,这笔融资将用于扩大公司的市场份额,继续开发和优化他们的智能机器人解决方案。他们计划进一步提升机器人系统的自我监控和维护能力,以确保在任何生产环境中都能稳定高效地运行。
总的来说,GrayMatter Robotics的技术正在重新定义制造业的自动化水平,通过结合人工智能和物理模型,不仅提高了生产效率,还大大降低了成本和浪费,推动了整个行业向智能制造的方向迈进。
4.Decagon融资3500万美元:利用AI变革企业客户支持
官方网站:网页链接
Decagon是一家致力于通过AI增强客户支持的初创公司,近日从隐身模式中走出,宣布完成总计3500万美元的种子轮和A轮融资。本轮融资由Accel领投,a16z及多位知名投资者如Box CEO Aaron Levie、Airtable CEO Howie Liu等参与。
Decagon由CEO Jesse Zhang 和CTO Ashwin Sreenivas创立,利用生成式AI技术,为企业提供类人化的客户支持服务。与市场上许多仅能进行简单交互的聊天机器人不同,Decagon的AI代理不仅能回答客户询问,还能执行诸如处理退款请求或推迟发货等具体操作 。该平台已被Eventbrite、Bilt、Webflow、Substack等多家企业采用,显示出其在复杂业务环境下的高效表现。
Decagon的AI解决方案结合了第三方大型语言模型和自有的优化算法,可以灵活地应对不同的客户服务任务。该系统还配备了一个全面的分析仪表盘,自动审查和分类客户互动,帮助企业识别主题和趋势,并建议更新知识库,以提高客户服务的响应能力。
在客户支持领域,竞争非常激烈,但Decagon通过提供独特的价值主张脱颖而出。其AI不仅支持客户服务,还能生成软件漏洞报告、分析客户邮件并建议产品改进,以及撰写内部文档,成为公司内部的支持联络人。
此轮融资将帮助Decagon进一步优化其AI技术,扩展业务版图。随着更多企业采用AI驱动的客户支持解决方案,行业将迎来效率和响应速度的大幅提升,而人类支持人员则可以专注于更复杂的任务。Decagon的成功不仅预示着客户支持的未来,也标志着AI技术在各个行业的深入应用。
5.语言学习应用Speak融资2000万美元,实现估值翻倍,投后估值达5亿美元
官方网站:网页链接
语言学习应用Speak在最近的一轮融资中筹集了2000万美元,使其估值翻了一番。这轮融资由OpenAI创业基金领投,其他著名投资者包括Dropbox的联合创始人Drew Houston和Arash Ferdowsi。此次融资将用于支持Speak的扩展计划,特别是在美国市场的扩张,以及雇佣新员工以支持其在新兴市场的可用性。
Speak由Connor Zwick和Andrew Hsu于2016年创立,旨在通过互动的对话体验帮助用户练习英语口语。应用程序中的“AI导师”能够引导用户进行开放式对话,并在发音、语法和词汇方面提供反馈。这种虚拟导师使用了先进的自然语言处理和语音技术,模拟了面对面人类导师的优势。
目前,Speak已经在包括日本、台湾、德国和巴西在内的20多个国家推广,并计划在今年年底前进入美国市场,并提供多语言选项。尽管面临如Duolingo等其他AI驱动的语言学习应用的竞争,Speak已经成为韩国最受欢迎的教育应用之一,拥有超过10万用户,并声称帮助了约6%的韩国人口(约300万人)学习英语。
与OpenAI的合作是Speak成功的关键。OpenAI的投资不仅提供了资金支持,还提供了早期访问其系统和微软Azure资源的机会。这使Speak能够利用OpenAI的AI技术开发新功能。今年3月,Speak的AI导师升级为使用OpenAI的GPT-4文本生成模型,提供高度个性化和上下文相关的反馈,提高了用户的参与度和学习效果。此外,公司还采用了OpenAI的Whisper API进行多语言语音识别,并合作开发了新的ChatGPT插件,这是其首次进入英语以外的语言教学领域。
此次融资标志着Speak在AI和教育交叉领域的进一步发展,并且公司致力于提供负担得起的语言教育,在竞争激烈的市场中脱颖而出。公司计划在年底前进军更多市场,包括美国,显然已将自己定位为该领域的重要玩家。
6.AI工程设计软件公司Neural Concept获2700万美元融资,旨在颠覆传统工程设计行业
官方网站:网页链接
Neural Concept,一家专注于工程设计软件的AI公司,近期宣布完成了2700万美元的B轮融资,累计融资额达到3800万美元。该公司利用3D深度学习技术,大幅简化了传统的CAE(计算机辅助工程)流程,为设计师提供了实时的AI仿真预测功能,显著加快了设计迭代周期。这一变革性技术在F1赛车、电动车、航空航天和动力电池等高端制造领域展现出巨大潜力,客户对于显著的时间节省和设计创新性表现出强烈的购买意愿。
Neural Concept成立于2018年,源自瑞士洛桑联邦理工学院(EPFL)的人工智能研究实验室。该公司的3D深度学习平台不仅加速了产品开发周期,还解决了多项工程挑战,尤其在空气动力学管理和碰撞分析方面提供了创新解决方案。Neural Concept的技术优势在于将原本耗时的CFD(计算流体动力学)模拟缩短至数十秒,提高了工程师工作效率,缩短了产品开发时间。
公司的商业模式和产品效果已得到市场验证,与包括空客、博世、通用电气、斯巴鲁以及四支顶级F1车队在内的一系列高端客户建立了合作关系。Neural Concept还与Nvidia合作,通过优化GPU和CUDA软件,进一步推动AI在工业设计领域的应用。
此外,Neural Concept的平台支持多种CAD格式,提供了一个端到端的实时设计仿真一体化体验,为工程师和设计师提供了一个交互式协作环境。随着AI技术的发展,Neural Concept正推动工业软件迎来新的交互和应用范式,预示着云端计算和部署的更多可能性,为工业设计领域带来革命性的变化。
本文由阿尔法公社综合自多个信息源,并在ChatGPT的辅助下写作,封面图片由Hidream.ai的Pixeling(千象)生成。
更多精彩内容


关于阿尔法公社