
作者 | 方勇
一、摘要
好大夫在线已经收录了超过69万医生信息,其中有24万医生在平台上实名注册,服务用户累计6700万。随着业务快速发展,伴随而来的系统复杂性和多样性也越来越多,我们发现原先的服务架构已经跟不上业务的迭代速度了。All-in-one发版时间过长,服务耦合在一起,一出问题很容易波及全站。2018年公司开始推进微服务拆分,由php转向java,前端开始转型node,迎来了服务快速增长的阶段,目前我们有350多个微服务,每隔几周会上线一个新服务。随着服务的逐渐增多,我们发现编织的微服务大网越来越大,面临微服务治理的挑战也越来越多。微服务治理包含范围非常广,主要有服务发现,服务注册,服务编排,服务配置,服务网关,服务监控预警,日志分析等等等等。其中遇到问题最多的是围绕服务的稳定性和可用性,比如如何快速定位问题和评估影响范围。接下来就针对服务的稳定性和可用性聊一下我们的应对措施,主要是日志分析和应用画像平台化。
二、聚焦微服务治理痛点
主要从应用,中间件的稳定性和可用性两个方面分析。解决方案:构建平台,包括日志全息分析、实时告警,应用画像、配置管理。随着业务日趋复杂,All-in-one笨重的系统很难适应敏捷开发的节奏,应用按不同的维度进行微服务架构拆分成为趋势。然而庞杂的业务系统由不同语言开发,不同团队维护,微服务治理也迅速带来新的挑战。
曾经的痛
曾几何时,几个人关在“小黑屋”排查问题的场景历历在目。记得2019年初夏,一个周五,马上就要欢度周末了,临近下班的时候,有用户反馈支付失败,紧接着越来越多的用户开始投诉,医患交流失败,很多方向的业务开发围到系统组,我们如临大敌,大家一起找个会议室排查问题。一开始我们觉得是网络抖动,因为出问题就在那一分钟内,有接口超时,有接口失败。各种查登录机器,各种猜测,最后定位到一台mq节点内存有波动,导致部分生产者被夯住。最后发现是是新加的一台mq没有切割日志,导致程序内存使用过高。从开始排查问题到最后定位出问题,足足花了一晚上。这种痛只有经历过才知道,也促进我们成长,这就是所谓成长总是痛苦的。我们开始整合中间件日志,让应用和中间件产生联动。诸如此类的还有很多很多。
我们面临的问题到底是什么
如何快速定位故障?告警事件爆炸,如何判断业务方异常,还是中间件异常,亦或是某个机器异常?
如何追踪调用链路?一条调用链路涉及几十个应用,异步处理的请求如何溯源?
如何评估应用容量?机器资源配比多少合适,产品推广落地页如何规划各应用容量?
如何分析应用潜在风险?应用慢接口,循环调用,依赖不合理,找出潜在的风险SQL?
应用的可用性和稳定性越来越重要,如何降低排查问题的成本越来越重要,我们需要一双眼睛帮忙观察,一个大脑帮我们分析。
如何衡量服务的稳定性和可用性?
衡量服务稳定性,首要任务就是寻找合适的SLI,设置合理的SLO。选择衡量的标准至关重要:监控项太多,图表看不过来,出问题了不知道看哪个图表,大部分时候一出问题就蒙圈,能查问题的也就那么几个人。因此指标设计原则一定要精简精简直到无法精简。配合全局画像让大家一眼就能知道哪个环节出了问题。我们主要参考的是《Google的SRE运维揭秘》,和借鉴蘑菇街赵诚老师的经验,从以下五个方面设置SLO:
应用的容量;
可用性;
时延;
错误率;
人工介入次数。
还有花哨的图表也只是辅助,大原则还是监控告警明确,快速定位出异常应用或故障节点,尝试自动故障转移或及时止损,最后通过分析画像或分析日志寻找根因。
我们来一起看一下这五条黄金法则是如何指导我们设计SLO的:
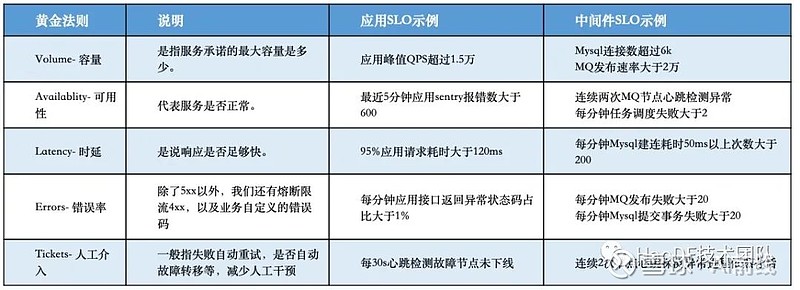
这五条法则是指导意见,希望能帮助大家。
三、最初的愿景
平台构建最初的愿景,主要是随着微服务的推进,服务稳定性越来越重要,服务间调用出的问题越来越难以定位,排查的次数多了,各种工具脚本/Dashboard/小系统越来越多,这些经验很难传承,定制化高,推广成本大,更新迭代也不及时,普及度也是非常的低,能查问题的就那么几个人。
为了提高效率,面向全公司开发、测试全员,因此我们开始打造服务治理平台:
方便开发快速定位问题;
风险前移,对潜在风险生成任务,打造开发->测试->线上验证的闭环,后面会重点介绍;
打通数据流,告警与画像结合,能大大提高排查效率;
配置统一管理,设置熔断限流,配置故障转移策略,设置告警阈值,处理中间件事件等等,让开发能有一个统一的平台进行操作。
四、平台化演进过程
我们服务治理平台化演进,也经历了:人工 -> 工具化 -> 系统化 -> 平台化:

1、调研
应用层、中间件的稳定性和可用性,是我们关注的两个大维度。包括节点资源信息,应用间调度信息。业内比较成熟的有:
面向虚拟机,物理机机器资源的监控有zabbix,面向容器的有prometheus;
针对链路分析的主要有基于ELK体系的APM,开源的还有韩国的pinpoint,Twitter的Zipkin,国内阿里有ARMS,腾讯的有天机阁等等,他们大多都受2010年谷歌发表了Dapper论文的影响;
中间件层大部分中间件都提供了自己的一套监指标,或者配备自己的监控报表,有些呢还得提供了相关的API。
2、我们当时的情形
应用层
我们应用有多种语言开发,链路分析开源的方案不能直接满足我们的需求,大部分具有代码侵入性,对接开源软件,我们依然需要二次开发;
我们当时是有一些日志nginx日志/链路日志,只是日志不够精细,中间件用户侧日志缺少,如中间件的连接耗时,执行耗时,mq发布成功状态等,我们需要细化补全;
我们入口除了Http协议以外,还有AMQP协议入口,以及分布式任务调度入口,我们需要进行打通,生成全局唯一TraceID。
中间件
已有的自研的shell脚本,基于zabbix调度,比较笨重,维护成本比较高,部署比较麻烦;
各个中间件都是高度定制化,随着中间件的升级兼容性问题也很多;
Prometheus生态的完善,很多中间件官方支持对接Prometheus,这样的话减少了我们的维护成本,对接也非常的方便。
我们的解决方案
机器资源监控依托Prometheus生态,逐渐由Zabbix向Prometheus迁移;
应用间调用链分析基于已有的日志收集流程,自研一个分析大脑;
中间件指标收集我们提供统一的接口和数据格式,方便统一对接;
中间件的维护管理,如熔断限流设置,告警阈值设置,告警规则设置等都收拢到统一平台。
3、技术选型
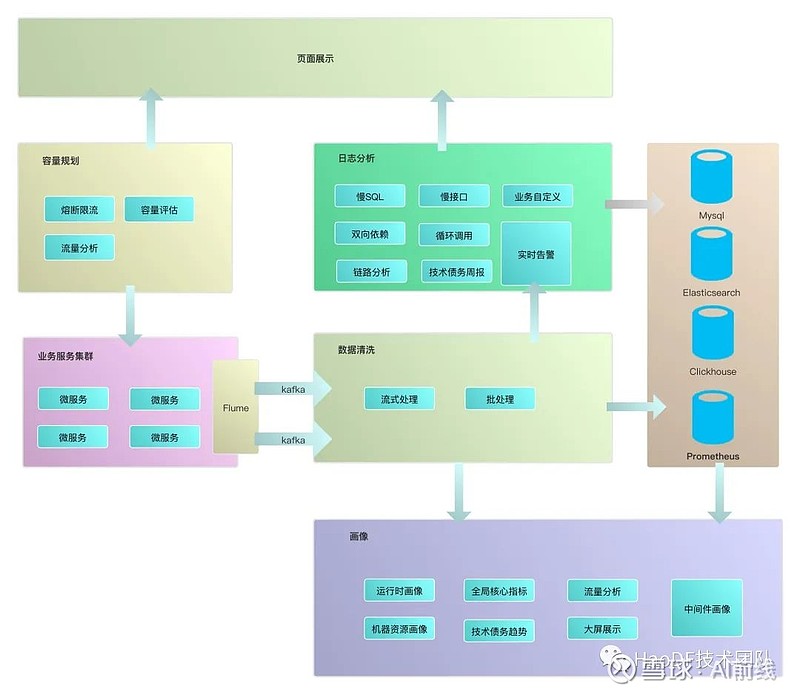
我们的平台采用分布式前后端分离架构,可视化前台Dany是基于vue(element-ui/element-admin),后端主要基于Golang和Python,目前已监控352个业务应用,1200多个节点,链路日志量级30亿左右。主要模块如下:
应用运行时画像:
数据源主要包括Promethues、Elasticsearch和Clickhouse,展示基于Grafana。数据存储正逐步从Elasticsearch迁移到Clikhouse,基本流程是Gohangout订阅Kafka清洗后持久化到Clickhouse。
应用机器资源使用画像:
目前大部分服务依然部署在虚拟机上,有些指标我们通过写shell脚本让zabbix触发。随着容器化的推进,Prometheus的生态更加适合我们,因此我们逐渐用prometheus替代原有的zabbix职责。
日志全息分析:
主要分析应用潜在风险,应用异常诊断 采用Golang自研系统(Snow)流式分析Kafka数据持久化到Mysql。
APM链路分析:
链路追踪日志埋点我们集成到服务框架(php/node/java)中。记录所有http协议和amqp协议的请求,记录上下游,请求耗时,机器信息等,日志信息落盘本地,基于ELK持久化。
实时告警:
告警事件判定,记录告警事件处理工作流,告警应答(Ack)升级,我们基于Python开发了Dolphin系统。
4、拓扑图
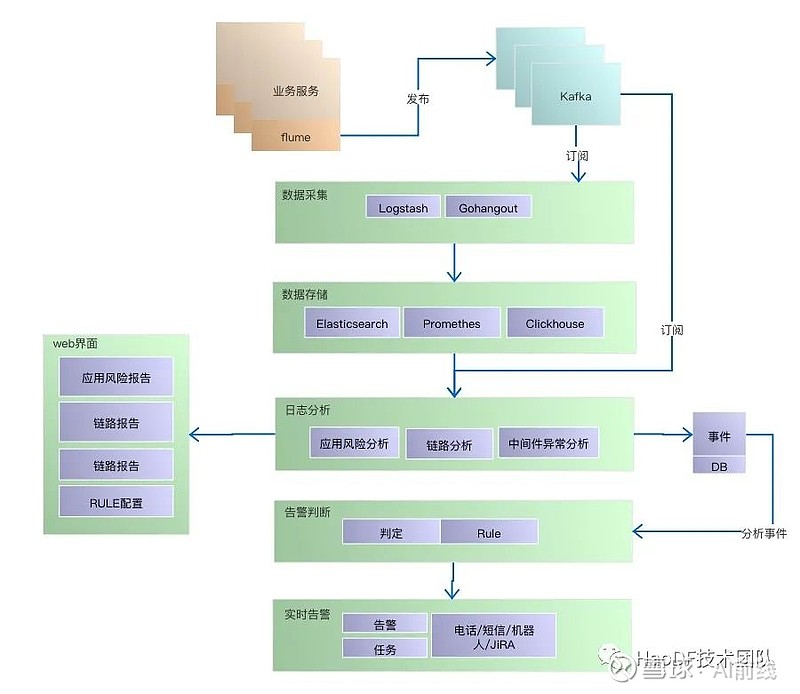
5、流程图
五、日志全息分析
1、APM链路分析
应用场景:
生成的风险任务需要配合链路分析,如循环调用,在最近的一次链路中被调用了几次,请求耗时是怎样,上下游依赖是怎样等;
在排查故障的时候,开发根据自己感兴趣的trace_id分析整条链路的情况,方便快速定位问题;
应用QPS异常波动的时候分析上下游接口调用量,可以分析出是入口流量激增还是命中特殊数据产生了循环调用
设计思路:
我们目前记录链路的入口采用AOP模式植入到已有的框架中(php/node/java),业内还有无侵入解决方案类似sidecar模式,代理请求记录全链路。随着微服务的演进,为了加速请求,链路会同时并发请求,需要识别和准确标记时间线,推动着APM链路分析的演进。



2、应用风险分析
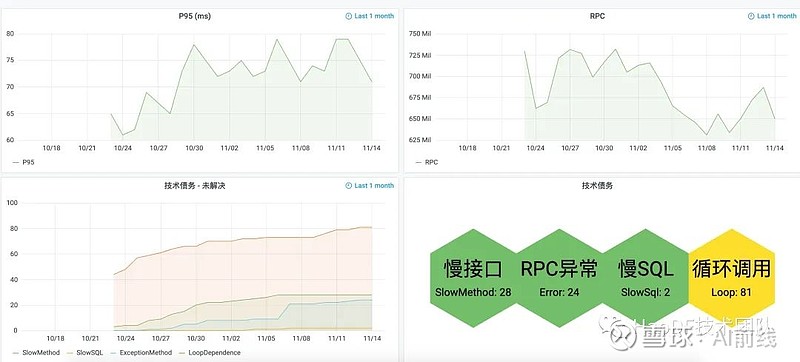
微服务架构带来链路越来越深,随着业务增长慢接口,循环调用,双向依赖,慢SQL成为应用四大杀手,令无数开发闻风丧胆,血的教训迫使我们不能放过这些杀手。微服务架构另外的一个问题就是产生海量的日志,目前我们大约每天30亿次内网请求日志。为了分析四大杀手的特征,我们订阅Kafka日志流,分析过滤。得益于Golang的协程(goroutine)能力,每秒分析5w+日志,目前只有两台虚拟机在分析,可以水平扩展分析能力。应用开发负责人会收到风险任务推送,通过给风险任务打上优先级,及时跟进解决,测试进行线上验证环节,最终平台会验证风险是否解除。分析后生成任务展示效果如下:


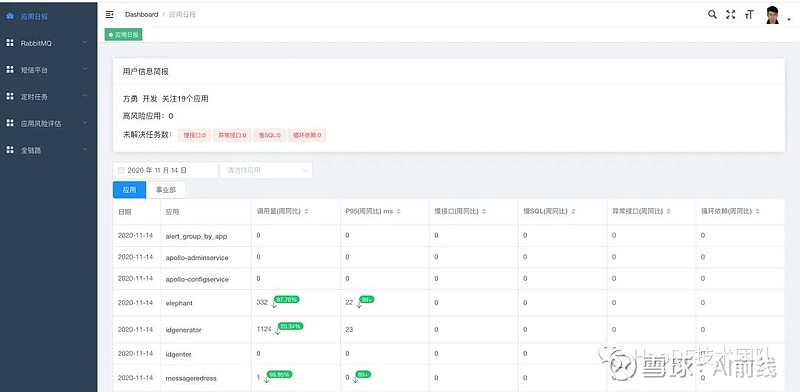
3、风险任务报告
应用场景:
培养风险意识,开发、测试都能直观感受各自应用面临的风险情况;
风险趋势,能纵向看单应用的风险趋势,也能横向看整个公司其他事业部的风险趋势 :
4、容量评估
应用场景:
自然增长流量的线性预测,对核心服务,繁忙的服务压测,计算出单机QPS峰值,设置预警水位线;
针对推广的页面,产品预估流量,我们对当前链路分析依赖的应用容量,评估是否需要扩容 设计思路:全链路压测实施与验证顺序 单接口压测->单应用压测->全链路压测,压测系统目前还在孵化中,前期我们通过调节单应用的机器流量分布模拟压测。

5、业务自定义分析
应用场景:
辅助应用精细化运营,如分析推送到达率,推送落地页点击率等;
A/B测试,业务可以分析不同的页面的转化率,或页面区域按钮点击事件;
业务打点标记自己领域事件,异常标记等;
抽样分析接口的参数等
设计思路:整体流程依然是基于日志收集模式,业务方通过模板定义数据格式记录到日志,采集程序分析日志,映射到数据表中。
6、实时告警
触发预设的告警规则后,按优先级提供不同告警形式:邮件,微信群机器人,短信,电话。
兜底监控规则的确定
由于目前大部分开发还处于监控意识培养的初期阶段,目前核心应用规模还是可控的,于是我们基于全应用做了兜底监控。如每秒全站请求异常状态,消费者处理异常,mysql提交事务异常等。系统组默默的承担着全站SRE的职责。
业务方主动订阅与兜底规则复写
为了告警的及时响应和快速处理,我们基于应用给出告警规则通用模板,业务设置相应的阈值即可,如每分钟请求异常数,应用程序产生的sentry异常数,MQ发布、消费异常数等。
主/副OnCall机制
随着业务工程师逐渐加入,需要处理各种不同优先级的告警,一有告警就全员All-in排查。为了优化告警响应机制,引入主副值班on-call机制,按应用模块每周设置一个主值班, 主值班必须及时应答告警(ACK),尝试定位分析问题,必要的时候进行告警升级,通知团队负责人或请求其他团队协作。
六、应用画像
1、应用运行时画像
我们监控核心指标,触发实时告警,推出趋势截图。精简的指标能比较客观的反映应用运行情况。画像数据来源Clickhouse,大部分SQL执行都能在1s内返回。
流量饱和度,每个应用能承载的峰值流量是不一样的,我们需要监控每个应用节点的QPS波动及增长趋势;
响应耗时p95线,RPC请求耗时符合长尾效应,越慢的接口越有可能拖垮整个应用,我们采用耗时百分位第95的时间作为应用健康衡量的指标;
异常监控,主要监控RPC请求错误率,业务系统自定义异常(sentry),依赖的中间件异常等;
核心接口监控,这部分是业务主动订阅核心接口每秒请求成功率。

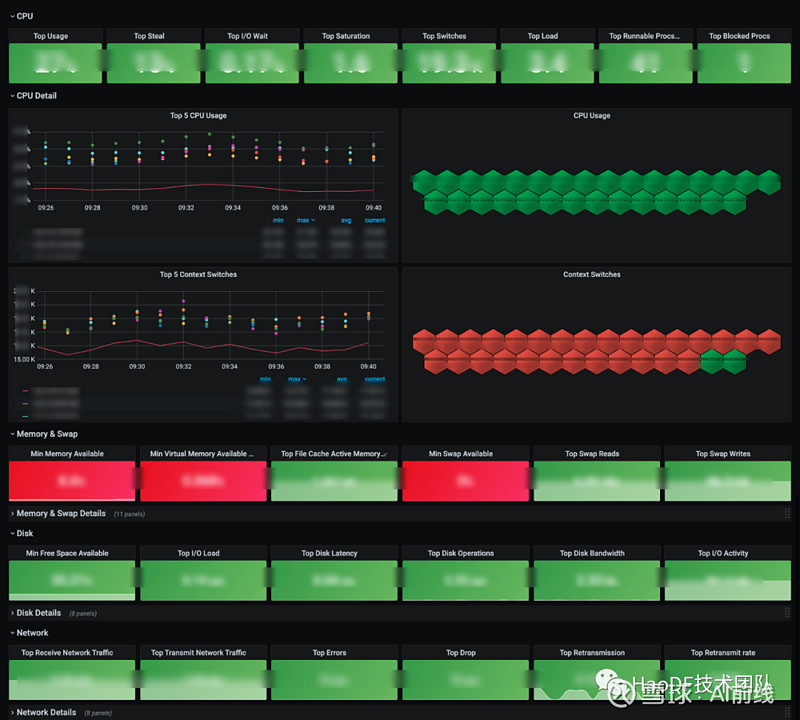
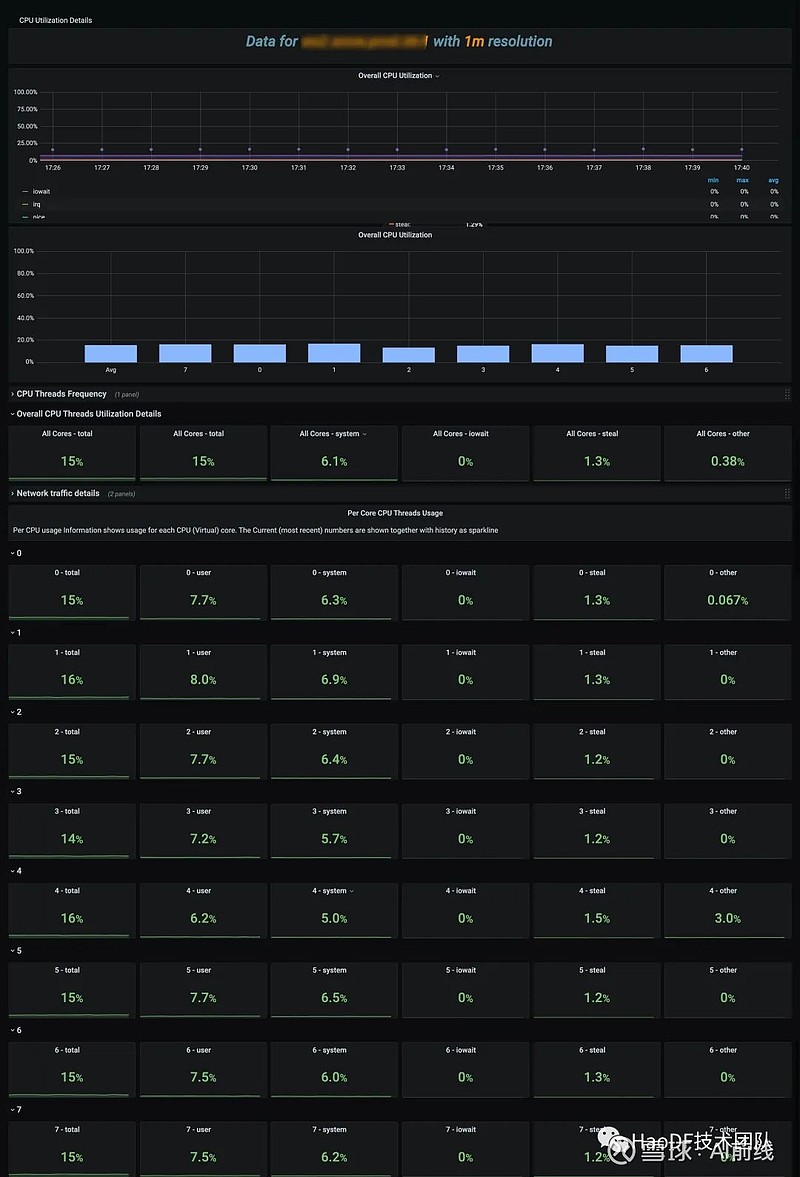
2、机器资源画像
机器资源饱和度也是非常关键的一项指标,应用吞吐能力根据自身情况有CPU密集型,有I/O密集型而有所不同。这些指标主要还是辅助作用,一般会反应在应用吞吐能力上。给应用容量评估提供指导意见。数据源来自Prometheus采集node-exporter。
3、中间件客户端画像
除了RPC请求入口,还有基于APMQ协议的请求,分布式任务调度中心的请求。应用依赖的中间件使用不规范,或者执行异常我们都能通过画像系统反映出来,给出优化意见。

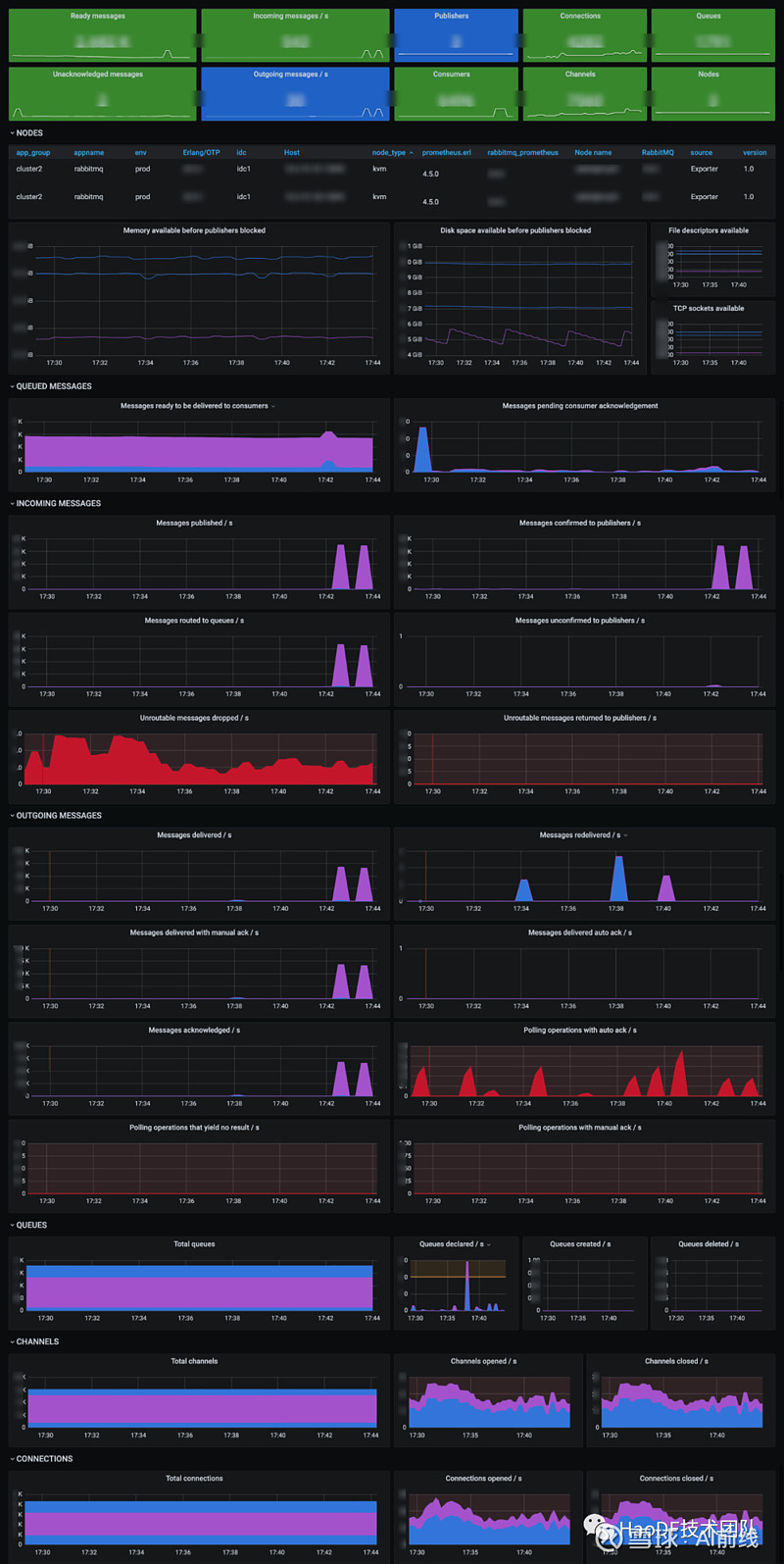
4、中间件服务端画像
中间件自身的稳定性也是非常重要的,可用性考核需要达到四个9。大部分我们依赖Prometheus生态,如Mysql-exporter,RabbitMQ 3.8版本以后官方支持prometheus指标。针对Mysql/MongoDB等我们采用了percona的pmm2。
七、遇到的挑战
1、数据存储从ES迁移到Clickhouse
随着微服务的拆分,局域网日志越来越大,每天大于30亿左右,对这些日志进行提炼分析时效性越来越低,加上膨胀的日志占用磁盘越来越大,从原先保留半个月到后来的6天。每天大约产生800G。国内很多企业也遇到类似的问题,也尝试落地Clickhous替换Elasticsearch,便捷的查询,数据压缩比高。迁移后Dashboard数据渲染基本上都在秒级,数据压缩比1:4.2。

2、Prometheus和Zabbix的抉择
应用监控最初是基于Zabbix的,更多的是机器资源维度,最大的痛点是告警分组不友好,值班运维沦为了告警中转站,人工联系各业务方处理相关问题。再加上云原生的推进,Prometheus的生态强大,接入开发成本低,成为我们现在监控的首选。
3、SLO的确定我们进行了多轮头脑风暴
我们从蘑菇街赵诚老师那取了不少经,主要还是从应用的容量,可用性,时延,错误率,人工介入次数几个方面设计SLO。关于SLO选定可以参考Google的设定模板。
4、SRE落地离不开公司上层的加持
大部分互联网公司,产品迭代速度是非常快的,应用技术质量和迭代速度相互竞争,代码质量有时候能决定产品的生死,越来越慢的接口会拖垮应用服务质量。从遇到故障问题才关心,慢慢关注点往前移,从代码坏味道,潜在风险分析,告警响应处理时长,应用稳定性和中间件稳定性都设置考核指标。好大夫实时监控告警大屏也逐渐成为一道风景线。

八、未来的规划
平台可用性:画像和日志分析界面整合,提供统一的平台入口;
熔断限流:熔断限流管理平台化;
全链路压测:模型识别更加精准,更精准的瓶颈判断;
智能容量评估:应用节点自动扩缩容。
如有意愿加入好大夫团队,可访问以下链接:
你也「在看」吗?