
来源 | OpenAI
译者 | 核子可乐,陈思
编辑 | Natalie
AI 前线导读: 时隔九个月,GPT-2 的阶段性开放终于进入尾声。北京时间 11 月 6 日,OpenAI 正式放出 GPT-2 最后一个部分的完整代码——包含 15 亿参数的最大版本。
按照 OpenAI 方面的说法:公开完整版本确实与模型滥用的调查结果有关。虽然经过多方求证发现,GPT-2 存在被极端组织恶意使用的可能,但是目前没有证据直接证明 GPT-2 已经遭到了滥用。更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
“最强 NLP 模型”GPT-2 完整开源
经历了被追捧为“最强 NLP 模型”、因为不开源遭到 全网吐槽、宣布 部分开源 等一系列大事件之后,今天,OpenAI 终于公开了 GPT-2 最大最完整的 15 亿参数版本。
照例先放上开源地址:网页链接
在此之前,OpenAI 已经发布了三种 GPT-2 模型:“小型的”1.24 亿参数模型(有 500MB 在磁盘上 ),“中型的”3.55 亿参数模型(有 1.5GB 在磁盘上 ),以及 7.74 亿参数模型(有 3GB 在磁盘上 )。
作为 GPT-2 分段发布中的最后一轮,此次公开的完整 GPT-2 包含 15 亿条参数,其中包含用于检测 GPT-2 模型输出的全部代码及模型权重。OpenAI 在官方博客上表示:
自今年 8 月以来,我们一直遵循初始分段发布计划,通过越来越大的语言模型帮助社区获取准确度更高的可测试案例。我们希望这一测试案例能够帮助开发人员构建起功能更强大的后续模型,同时也积极与 AI 社区就发布责任问题开展对话。
除此之外,OpenAI 还公布了有关 GPT-2 的一些新发现,其中包含了公众最为关心的滥用等问题。
有关 GPT-2 的新发现
1. 人们发现 GPT-2 的输出质量令人信服。
作为合作伙伴,康奈尔大学的研究人员对 GPT-2 使用受众进行了调查,希望根据不同规模的模型版本为 GPT-2 生成文本进行质量评分。人们给 1.5B 模型给出的“可信度得分”为 6.91 分(满分 10 分),略高于此前的 774M 模型版本(6.72 分),同时大大高于更早的 335M 模型版本(6.07 分)。正因为评分逐步提升,OpenAI 才决定发布最终的 1.5B 模型,将完整的 GPT-2 展现在公众面前。
2. GPT-2 经过微调后可能被滥用。
作为合作伙伴,米德尔伯里国际研究中心下辖的恐怖主义、极端主义与反恐中心(CTEC)研究人员们发现,极端主义团队可对 GPT-2 进行滥用,特别是结合四种意识形态立场对模型做出微调。
CTEC 的研究结果显示,微调后的模型足以为这些意识形态快速生成综合性宣传素材。他们还证明,尽管合成输出结果相当具有迷惑性,但基于 ML 的检测方法仍可帮助专家分辨出由 GPT-2 生成的伪造消息。
3. 检测难度颇高。
OpenAI 认为,对基于内容的合成文本进行检测将是一项长期挑战。为了测试机器学习方法是否有助于解决这个难题,研究者进行了内部检测研究,并开发出一种检测模型。面对由 GPT-2 1.5B 生成的文本,这套模型能够带来 95% 的检测成功率。(注 1)
具体来讲,OpenAI 选择立足 RoBERTaBASSE(1.25 亿条参数)与 RoBERTaLARGE(3.55 亿条参数)建立起序列分类器,并通过微调使其获得对 GPT-2 1.5B 模型与 WebText(用于训练 GPT-2 模型的数据集)输出结果的分类能力。
OpenAI 认为,对于单项检测而言,这样的准确率还无法令人满足,必须同时结合基于元数据的方法、人为判断以及常识教育才能进一步提高效果。为此,OpenAI 选择发布完整版模型,希望协助各方共同研究对合成文本的检测方法。当然,OpenAI 方面也承认全面发布同时也会让恶意人士有机会进一步提高检测逃避能力。
此外,OpenAI 发现,检测准确率在很大程度上取决于训练及测试中使用的具体采样方法,但同时,在使用多种采样技术进行训练时,检测结果将更加可靠。如下图所示,规模越大的模型,其输出结果越是难以分类。但是,利用这部分输出进行训练,则可提升检测结果的准确率与可靠性。OpenAI 预计这种趋势将长期存在,随着模型规模的增大,检测难度也将同步提升。
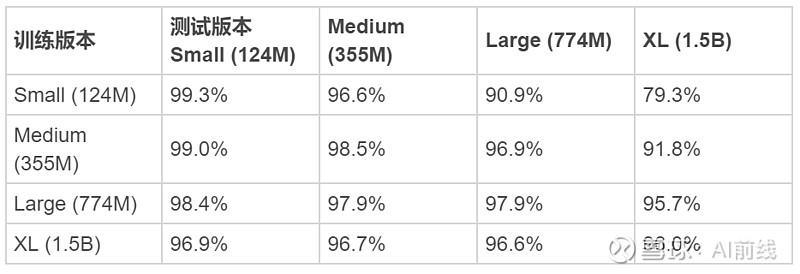
各模型版本检测准确率(核样本)
4. 到目前为止,尚未发现明确的滥用迹象。
尽管 OpenAI 的研究人员已经围绕 GPT-2 在大规模生成垃圾邮件与网络钓鱼信息等高批量 / 低收益操作方面的潜力进行了讨论,但 截至目前并未发现任何明确的代码、文档或者其他滥用实证。他们认为,随着合成许可证生成器在输出质量上的持续提升,遭到滥用的可能性确实会同步提高,同时也承认,OpenAI 无法及时发现所有潜在威胁,而有动机的参与者也不太可能发布自己的微调语言模型。
5. 在偏见研究方面,需要建立标准。
语言模型永远存在偏见。对于 AI 研究界而言,为此类偏见制定出研究方法、开展讨论并加以解决已经成为一项重要但难以克服的挑战。OpenAI 通过以下两种方式尝试解决偏见难题:
发布模型卡(注 2)这一模型卡以 Mitchell 等人提出的“用于模型报告的模型卡”理论为基础。我们同时在 GitHub 上发布模型代码,希望帮助大家对语言模型(例如 GPT-2)存在的固有问题建立理解。对 GPT-2 中存在的某些偏见做出内部定性评估:我们利用评估结果通过模型卡对 GPT-2 在性别、种族以及宗教方面的偏见作出探究。当然,这些调查并不全面,还需要配合其他偏见分析框架。
下一步计划
OpenAI 在博客中表示:
过去九个月以来,我们在 GPT-2 开发方面的经验,帮助我们为 AI 模型负责任发布工作中存在的挑战与机遇建立起宝贵的见解。我们也参与到 Partnership on AI 的“机器学习负责任发布规范”项目当中,希望通过合作关系与研究界的同行们共同讨论,为解决模型发布问题贡献力量。
讨论仍在继续:GPT-2 好用吗?安全吗?
HackerNews 网站上,有关 GPT-2 的讨论一直没有停止。在 15 亿参数版本发布后,更多参与者加入话题了。
讨论页面:网页链接
目前的讨论者分为两个主要阵营:
尝鲜派:GPT-2 好用吗?在哪儿用?
这一类讨论者主要在研究 GPT-2 的实用性,一些开发者也附上了自己的做的测试模型,感兴趣的读者可以前去体验:
当然也有一些讨论者提出:GPT-2 开放代码的可读性较差,有不少意义不明的内容,在生成文本的时候,甚至会出现一些常识性的错误等等。这些问题让部分讨论者质疑 OpenAI 放出的有可能是微调过的“阉割版”。
激辩派:GPT-2 安全吗?
这一派讨论者主要将目光聚焦在 GPT-2 的安全性上。毕竟官方也已经承认:确实存在安全隐患。大部分讨论者的观点都认为:GPT-2 完全开放后,必然会引发一阵滥用风潮。其中不乏一些激进人士的观点。
AI 前线早先发布的 一篇文章 中,作者曾对 GPT-2 的威胁论进行过探究,他认为 GPT-2 被滥用的可能性遭到了过分夸张。当然,作者当时测试用的也并非是完整版本,不知道在使用过完整版一段时间后,他的看法会不会有所改变。
注释
具体来讲,OpenAI 立足 RoBERTaBASSE(1.25 亿条参数)与 RoBERTaLARGE(3.55 亿条参数)建立起序列分类器,并通过微调使其获得对 GPT-2 1.5B 模型与 WebText(用于训练 GPT-2 模型的数据集)输出结果的分类能力。这一 模型卡 以 Mitchell 等人提出的“用于模型报告的模型卡”理论为基础。
参考链接:
活动推荐
机器学习、NLP、知识图谱、搜索推荐等技术有哪些最新落地案例?我们邀请到了来自 AWS、微软、BAT、华为等 50+国内外一线 AI 技术专家,带来智能金融、电商、物流、AI 芯片等领域的干货分享,更有贾扬清、李沐、颜水成等大牛现场助阵,部分精彩议题抢先看:
【蚂蚁金服】金融知识图谱在蚂蚁的业务探索与平台实践
【菜鸟网络】人工智能在智慧交通物流的技术演进之路
【阿里妈妈】工业级深度学习在阿里广告的实践、创新与最新进展
【微软小冰】人格化对话机器人的构建及在语音场景当中的实践
【百度】AI 大生产时代下的 NLP 技术创新与应用实践

11 月 21-22,AICon 北京等你来!目前大会 9 折售票倒计时进行中,购票页面输入优惠码“aicon”还可享折扣价,抢票咨询:18514549229(同微信),点击“阅读原文”了解更多大会详情。
今日荐文
点击下方图片即可阅读

苹果等四家科技巨头坐拥硅谷千亿地产,员工却还是买不起房
你也「在看」吗?