作者 | Mark Needham
译者 | Tianyu、Shawnice
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
图算法不是一个新兴技术领域,在开源库中已经有很多功能强大的算法实现。近两年,业内的学者与科学家都在积极探索可以弥补深度学习不可解释性,无法进行因果推断的这个缺陷,而图神经网络(GNN)成为备受关注和期待的“宠儿”。随着学界和业界越来越关注GNN,各种新工作不断被提出,基于图神经网络的框架随之产生,如大家现在都已经熟悉的DGL,两大深度学习框架PyTorch和TensorFlow中也开始支持相应的功能,大家对图(Graph)、图计算、图数据库、图机器学习等研究的关注度越发高涨。
基于图数据的优秀性质,吸引越来越多的企业在基于图数据的机器学习任务中开始投入研究与使用,将图数据与机器学习算法结合,弥补算法缺陷,赋予新一代图数据库新的使命。有不少企业内部自研图数据库与图分析计算平台,但是可直接使用的开源或成熟工具并不完善,对没有能力自研的企业来说,基于图数据的机器学习该怎么做?工程师在自己的研究中有什么可行的尝试方法?
今天的文章中,通过大家都非常熟悉的两个工具——图数据库 Neo4J和Scikit-Learning 提供一种解决思路。我们将以构建一个机器学习分类器任务为例,从基础背景知识、算法原理到算法代码实现进行全面的讲解与指导。
数据库 Neo4J
数据库 Neo4J 是一种图形数据库,目前几个主流图数据库有 TigerGraph、Neo4j、Amazon Neptune、JanusGraph和ArangoDB,近年来,Neo4J一直位列图数据库排行榜榜首,随着这几年知识图谱的火热发展,让数据库 Neo4J受到广泛关注。
Neo4J 主要基于Cypher语言,基于Graph Algorithm 实现图分析算法。获取安装Neo4j Desktop也非常容易,只需一键。
Neo4j Desktop 地址:
这里再给大家推荐主要基于 Neo4J实现的案例算法书《Graph Algorithms》,其作者 Amy Holder 和 Mark Needham也是 Neo4j的员工。

在线阅读地址:
图数据库对于分析异构数据点之间的关系特别的有用,例如防欺诈或Facebook的好友关系图,以在社交网络关系的预测任务为例,复杂的(社交)网络一个最重要的基本构成是链接,在社交关系网络中基于已有节点和链接构成的网络信息,预测潜在关系,这背后一个核心的算法就是链路预测算法。这也是我们今天文章中的核心算法,Neo4J图算法库支持了多种链路预测算法,在初识Neo4J 后,我们就开始步入链路预测算法的学习,以及如何将数据导入Neo4J中,通过Scikit-Learning与链路预测算法,搭建机器学习预测任务模型。
链路预测算法
(一)什么是链路预测?
链路预测已经被提出很多年了。2004年,由 Jon Kleinberg 和 David Liben-Nowell 发表相关论文之后,链路预测才被普及开来。他们的论文为《The Link Prediction Problem for Social Networks》
论文地址:
随后,Kleinberg 和 Liben-Nowell 提出从社交网络的角度来解决链路预测问题,如下所述:
若给定一个社交网络的快照,我们能预测出该网络中的成员在未来可能出现哪些新的关系吗?我们可以把这个问题看作链路预测问题,然后对网络中各节点的相似度进行分析,从而得出预测链路的方法。
后来,Jim Webber 博士在 GraphConnect San Francisco 2015 大会上介绍了图算法的发展历程,他用图理论讲解了第二次世界大战。
演讲视频:
除了预测世界大战和社交网络中的朋友关系,我们还可能在什么场景用到关系预测呢?我们可以预测恐怖组织成员之间的关系,生物网络中分子间的关系,引文网络中潜在的共同创作关系,对艺术家或艺术品的兴趣等等,这些场景都可能用得上链路预测。
链路的预测都意味着对未来可能发生的行为进行预测,比如在一个引文网络中,我们是在对两个人是否可能合作写一篇论文进行预测。
(二)链路预测算法
Kleinberg 和 Liben-Nowell 介绍了一系列可以用于链路预测的算法,如下图所示:
 Kleinberg 和 Liben-Nowell 在论文中所介绍的算法
Kleinberg 和 Liben-Nowell 在论文中所介绍的算法
这些方法都是计算一对节点的分数,该分数可看作为那些节点基于拓扑网络的“近似度”。两个节点越相近,它们之间存在联系的可能性就越大。
下面我们来看看几个评估标准,以便于我们理解算法的原理。
(三)算法评估标准
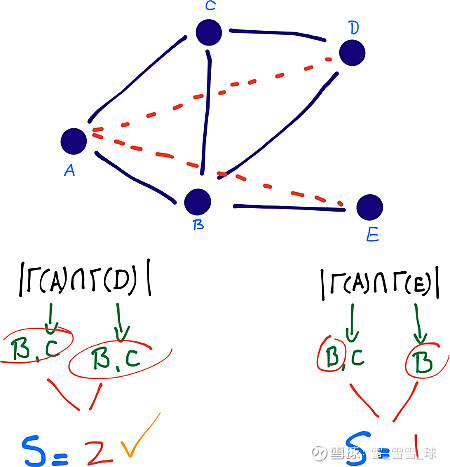
1、共同邻居数
最简单的度量方法之一是计算共同邻居数,对这个概念,Ahmad Sadraei 的解释如下:
作为预测因子,共同邻居数可以捕捉到拥有同一个朋友的两个陌生人,而这两个人可能会被这个朋友介绍认识(图中出现一个闭合的三角形)。
这个度量标准计算了一对节点所共享的相同邻居数目。如下图所示,节点 A 和 D 有两个共同邻居(节点 B 和 C),而节点 A 和 E 只有一个共同邻居(节点 B)。因此,我们认为节点 A 和 D 更相近,未来更有可能产生关联。
2、Adamic Adar(AA 指标)
早在2003年,Lada Adamic 和 Eytan Adar 在研究社交网络的预测问题时,提出了 Adamic Adar 算法。AA 指标也考虑了共同邻居的度信息,但除了共同邻居,还根据共同邻居的节点的度给每个节点赋予一个权重,即度的对数分之一,然后把每个节点的所有共同邻居的权重值相加,其和作为该节点对的相似度值。

节点的度指它的邻居数,该算法的初衷是:当图中出现一个闭合的三角时,那些度数低的节点可能有更大的影响力。比如在一个社交网络中,有两个人是被他们的共同好友介绍认识的,发生这种关联的可能性和这个人还有多少对朋友有关。一个“朋友不多”的人更有可能介绍他的一对朋友认识。
3、优先连接
对于图算法研究者来说,这应该是最常见的概念之一,最初由 Albert-László Barabási 和 Réka Albert 提出,当时他们正在进行有关无尺度网络的研究。该算法的设计初衷是,一个节点拥有的关系越多,未来获得更多关联的可能性就越大。这是计算起来最简单的度量标准,我们只需要计算每个节点的度数的乘积。
(四)链路预测 - Neo4j 图算法库
目前,Neo4j 图算法库涵盖了6种链路预测算法:Adamic Adar 算法、共同邻居算法( Common Neighbors)、优先连接算法(Preferential Attachment)、资源分配算法(Resource Allocation)、共同社区算法(Same Community)、总邻居算法(Total Neighbors)。
快速学习一下以下五种算法的原理:
(1)Adamic Adar:计算共同邻居的度数的对数分之一,并求和。
(2)优先连接算法:计算每个节点的度数的乘积。
(3)资源分配算法:计算共同邻居的度数分之一,并求和。
(4)共同社区算法:利用社区发现算法,检查两个节点是否处于同一个社区。
(5)总邻居算法:计算两个节点所拥有的不同邻居的数目。
现在来看一下如何使用库中的共同邻居函数,以之前提到的图关系作为例子。
首先执行 Cypher 语句,在 Neo4j 中创建一个图:
UNWIND [["A", "C"], ["A", "B"], ["B", "D"], ["B", "C"], ["B", "E"], ["C", "D"]] AS pairMERGE (n1:Node {name: pair[0]})MERGE (n2:Node {name: pair[1]})MERGE (n1)-[:FRIENDS]-(n2)
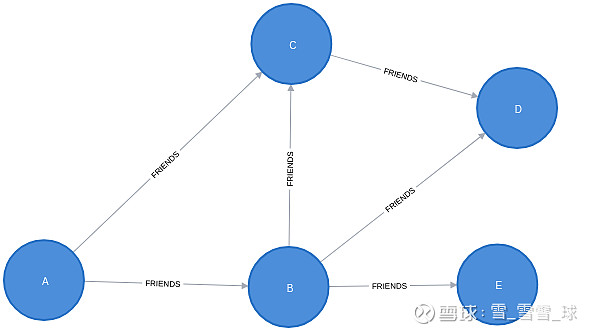
然后用下面的函数来计算节点 A 和 D 的共同邻居数:
neo4j> MATCH (a:Node {name: 'A'}) MATCH (d:Node {name: 'D'}) RETURN algo.linkprediction.commonNeighbors(a, d);+-------------------------------------------+| algo.linkprediction.commonNeighbors(a, d) |+-------------------------------------------+| 2.0 |+-------------------------------------------+1 row available after 97 ms, consumed after another 15 ms
这些节点有两个共同邻居,所以它们的得分为2。现在对节点 A 和 E 进行同样的计算。因为它们只有一个共同邻居,不出意外我们得到的分数应该为1。
neo4j> MATCH (a:Node {name: 'A'}) MATCH (e:Node {name: 'E'}) RETURN algo.linkprediction.commonNeighbors(a, e);+-------------------------------------------+| algo.linkprediction.commonNeighbors(a, e) |+-------------------------------------------+| 1.0 |+-------------------------------------------+
如我们所料,得分确实为1。该函数默认的计算方式涵盖任意的类型以及指向。我们也可以通过传入特定的参数来进行计算:
neo4j> WITH {direction: "BOTH", relationshipQuery: "FRIENDS"} AS config MATCH (a:Node {name: 'A'}) MATCH (e:Node {name: 'E'}) RETURN algo.linkprediction.commonNeighbors(a, e, config) AS score;+-------+| score |+-------+| 1.0 |+-------+
为了确保得到准确的结果,我们再试试另一种算法。
优先连接函数返回的是两个节点度数的乘积。如果我们对节点 A 和 D 进行计算,会得到 2*2=4 的结果,因为节点 A 和 D 都有两个邻居。下面来试一试:
neo4j> MATCH (a:Node {name: 'A'}) MATCH (d:Node {name: 'D'}) RETURN algo.linkprediction.preferentialAttachment(a, d) AS score;+-------+| score |+-------+| 4.0 |+-------+
(五)链路预测所得的分数有何用?
现在我们已经了解有关链路预测和相似度指标的基本知识了,但还需要弄明白如何使用这些指标进行链路预测。有以下两种方法:
1、直接使用指标
我们可以直接使用由链路预测算法得到的分数,即设置一个阈值,这样就可以预测一对节点是否可能存在关系了。
在上面的例子中,我们可以设定每一对优先连接分数在3分以上的节点都可能存在关联,而那些得分小于或等于3分的节点对则不存在关联。
2、有监督学习
我们可以把分数作为特征去训练一个二分类器,从而进行有监督学习。然后用这个二分类器去预测一对节点是否存在关联。
参考阅读文章《Link Prediction In Large-Scale Networks》中有对这两种方法的详细介绍:
在这个系列教程中,我们会重点介绍有监督学习的方法。
构建机器学习分类器
既然我们决定使用有监督学习的方法,那么就需要考虑有关机器学习工作流的两个问题:
(1)具体要使用什么机器学习模型?
(2)如何将数据分成训练集和测试集?
(一)机器学习模型
前面提到的链路预测指标都是对相似的数据进行计算,但如果选择使用机器学习模型,意味着我们需要解决特征间的关联问题。
有些机器学习模型默认其处理的特征都是相互独立的。若一个模型得到的特征不满足该假设,则会导致预测结果的准确度很低。无论我们选择什么模型,都需要去除掉那些高度相关的特征。
我们还可以选一个简单方案,使用那些对特征相关性不那么敏感的模型。
一些集成方法是行得通的,因为他们对输入数据没有这样的要求,比如梯度提升分类器(gradient boosting classifier)或者 随机森林分类器(random forest classifier)。
(二)训练集和测试集
比较棘手的问题是训练集和测试集的切分,我们不能只进行随机切分,因为这可能导致数据泄露。
当模型不小心用到训练集以外的数据时,就会发生数据泄露。这在图计算中很容易发生,因为训练集中的节点可能与测试集中的节点存在关联。
我们需要把图切分成子图作为训练集和测试集。如果图数据有时间这个概念,那我们的工作就容易多了,我们可以以某个时间点进行分割点,该时间点之前的数据作为训练集,之后的数据作为测试集。
这仍然不是最好的解决方案,我们需要进行尝试,确保训练集和测试集中子图的大致网络结构是相近的。一旦做好这一步,我们就拥有了由若干存在关联的节点对所组成的训练集和测试集。它们都属于机器学习模型中的正样本。
接下来看什么是负样本。
最简单的情况是,全部节点对之间都不存在关联。但问题是,很多场景中存在关系的节点对数目远大于那些没有关系的节点对。
负样本的最大数目如下:
# negative examples = (# nodes)² - (# relationships) - (# nodes)
如果我们将训练集中的全部负样本都代入模型,就会导致严重的类别不均衡问题,即负样本数远大于正样本数。
若基于这种不均衡数据集进行模型的训练,只要我们预测任何节点对都不存在关联,就可以得到非常不错的准确度,但这当然不是我们想要的。
所以我们需要尽量减少负样本的数目。有一种方法被多篇论文提及过,那就是选择那些彼此间距相等的节点对。这种方法可以有效地减少负样本数,虽然负样本数仍然远大于正样本数。
为了解决样本不均衡的问题,我们也可以对负样本进行欠采样,或者对正样本进行过采样。
(三)代码教程:链路预测实战
基于上面对链路预测背景知识的学习,准备好实际数据集后,下面我们就开始实操教程,教程将完成一个判断是否是论文合著者关系的机器学习预测模型。
1、录入引用数据库
我们将使用来自DBLP引文网络的数据,其中包括来自各种学术来源的引文数据,这里我们还要重点关注一些软件开发会议上的数据。
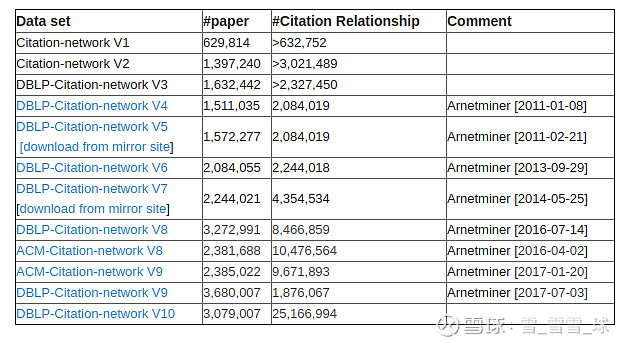
通过运行以下Cypher语句来导入该数据子集。只要在Neo4j浏览器中启用多语句编辑器,就可以一次全部运行。
// Create constraintsCREATE CONSTRAINT ON (a:Article) ASSERT a.index IS UNIQUE;CREATE CONSTRAINT ON (a:Author) ASSERT a.name IS UNIQUE;CREATE CONSTRAINT ON (v:Venue) ASSERT v.name IS UNIQUE;// Import data from JSON files using the APOC libraryCALL apoc.periodic.iterate( 'UNWIND ["dblp-ref-0.json", "dblp-ref-1.json", "dblp-ref-2.json", "dblp-ref-3.json"] AS file CALL apoc.load.json("网页链接 + file) YIELD value WITH value RETURN value', 'MERGE (a:Article {index:value.id}) SET a += apoc.map.clean(value,["id","authors","references", "venue"],[0]) WITH a, value.authors as authors, value.references AS citations, value.venue AS venue MERGE (v:Venue {name: venue}) MERGE (a)-[:VENUE]->(v) FOREACH(author in authors | MERGE (b:Author{name:author}) MERGE (a)-[:AUTHOR]->(b)) FOREACH(citation in citations | MERGE (cited:Article {index:citation}) MERGE (a)-[:CITED]->(cited))', {batchSize: 1000, iterateList: true});
下图是数据导入到Neo4j后的显示:
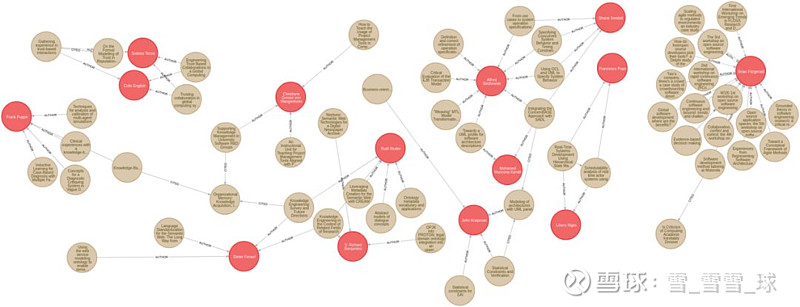
2、搭建共同作者图
该数据集不包含描述他们的协作的作者之间的关系,但是我们可以根据查找多个人撰写的文章来推断他们。以下Cypher语句在至少撰写过一篇文章的作者之间创建了CO_AUTHOR关系:
MATCH (a1)(a2:Author)WITH a1, a2, paperORDER BY a1, paper.yearWITH a1, a2, collect(paper)[0].year AS year, count(*) AS collaborationsMERGE (a1)-[coauthor:CO_AUTHOR {year: year}]-(a2)SET coauthor.collaborations = collaborations;
即使在多篇文章中进行过合作,我们也只能在合作的作者之间创建一种CO_AUTHOR关系。我们在这些关系上创建几个属性:
(1)年份属性,指合作者们共同完成的第一篇文章的出版年份
(2)合作属性,指作者们合作过多少篇文章
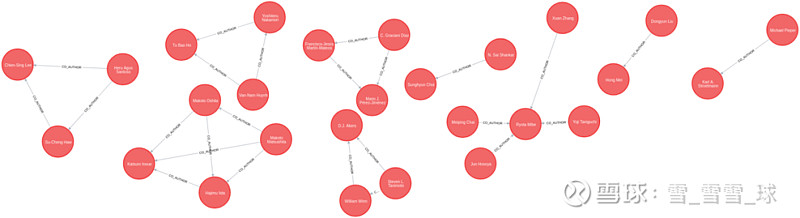 Neo4j 中的共同作者
Neo4j 中的共同作者
现在已经有了合著者关系图表,我们需要弄清楚如何预测作者之间未来合作的可能性,我们将构建一个二进制分类器来执行此操作,因此下一步是创建训练图和测试图。
3、训练和测试数据集
根据上面的介绍,我们不能将数据随机分为训练数据集和测试数据集,因为如果不小心将训练数据之外的数据用于创建模型,则可能会发生数据泄漏。这很容易发生在使用图形的时候,因为训练集中的节点对可能与测试集中的节点相连。
为了解决这个问题,我们需要将我们的图分为训练图和测试子图,幸运的是引文图中包含我们可以分割的时间信息。我们可以通过拆分特定年份的数据来创建训练图和测试图。但是,我们应该分开哪一年呢?先来看看合作者共同合作的第一年的分布情况:
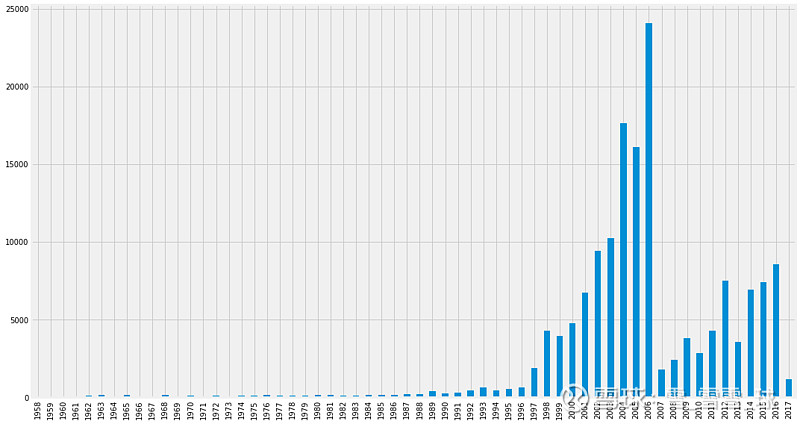
(每年的合作数分布图)
看起来我们应该在2016年进行拆分,为我们的每个子图提供合理数量的数据,将2005年之前开始的所有合著者作为训练图,2006年以后的则作为测试图。
基于该年在图表中创建明确的CO_AUTHOR_EARLY和CO_AUTHOR_LATE关系。以下代码将为我们创建这些关系:
训练子图
MATCH (a)-[r:CO_AUTHOR]->(b) WHERE r.year
测试子图
MATCH (a)-[r:CO_AUTHOR]->(b) WHERE r.year >= 2006MERGE (a)-[:CO_AUTHOR_LATE {year: r.year}]-(b);
这样分组使我们在2005年之前的早期图表中有81,096个关系,在2006年之后的后期图表中有74,128个关系,形成了52-48的比例。这个比例比通常测试中使用的比例高很多,但这没关系。这些子图中的关系将作为训练和测试集中的正例,但我们也需要一些负例。使用否定示例可以让我们的模型学习如何区分在它们之间链接节点和不在它们之间链接节点。
与链接预测问题一样,否定示例比肯定的示例多得多。否定示例的最大数量等于:
# negative examples = (# nodes)² - (# relationships) - (# nodes)
即节点的平方数减去图形所具有的关系再减去自身关系。
除了使用几乎所有可能的配对以外,我们也将彼此之间相距2至3跳的节点进行配对,这将为我们提供更多可管理的数据。我们可以通过运行以下代码来生成和查询配对:
MATCH (author:Author)WHERE (author)-[:CO_AUTHOR_EARLY]-()MATCH (author)-[:CO_AUTHOR_EARLY*2..3]-(other)WHERE not((author)-[:CO_AUTHOR_EARLY]-(other))RETURN id(author) AS node1, id(other) AS node2
此查询返回4,389,478个否定示和81,096个肯定示,这意味着否定示是肯定示的54倍之多。
但仍然存在很大的不平衡,这意味着用于预测每对节点链接的模型将非常不准确。为了解决这个问题,我们可以对正例进行升采样或对负例进行降采样,可以使用下采样方法。
4、Py2neo, pandas, scikit-learn
接下来我们使用py2neo,pandas和scikit-learn库,全部基于Python语言,通过Pypi安装:
pip install py2neo==4.1.3 pandas sklearn
(1)py2neo驱动程序使数据科学家能够轻松地将Neo4j与Python数据科学生态系统中的工具相结合。我们将使用该库对Neo4j执行Cypher查询。
(2)pandas是BSD许可的开放源代码库,为Python编程语言提供了高性能、易于使用的数据结构和数据分析工具。
(3)scikit-learn是一个非常受欢迎的机器学习库。我们将使用该库来构建我们的机器学习模型。
 (Scikit-Learn workflow 拓展版,来源网络)
(Scikit-Learn workflow 拓展版,来源网络)
安装完这些库后,导入所需的程序包,并创建数据库连接:
from py2neo import Graphimport pandas as pdgraph = Graph("bolt://localhost", auth=("neo4j", "neo4jPassword"))
5、搭建我们的训练和测试集
现在,我们可以编写以下代码来创建测试数据框架,其中包含基于早期图形的正例和负例:
# Find positive examplestrain_existing_links = graph.run("""MATCH (author:Author)-[:CO_AUTHOR_EARLY]->(other:Author)RETURN id(author) AS node1, id(other) AS node2, 1 AS label""").to_data_frame()# Find negative examplestrain_missing_links = graph.run("""MATCH (author:Author)WHERE (author)-[:CO_AUTHOR_EARLY]-()MATCH (author)-[:CO_AUTHOR_EARLY*2..3]-(other)WHERE not((author)-[:CO_AUTHOR_EARLY]-(other))RETURN id(author) AS node1, id(other) AS node2, 0 AS label""").to_data_frame()# Remove duplicatestrain_missing_links = train_missing_links.drop_duplicates()# Down sample negative examplestrain_missing_links = train_missing_links.sample( n=len(train_existing_links))# Create DataFrame from positive and negative examplestraining_df = train_missing_links.append( train_existing_links, ignore_index=True)training_df['label'] = training_df['label'].astype('category')
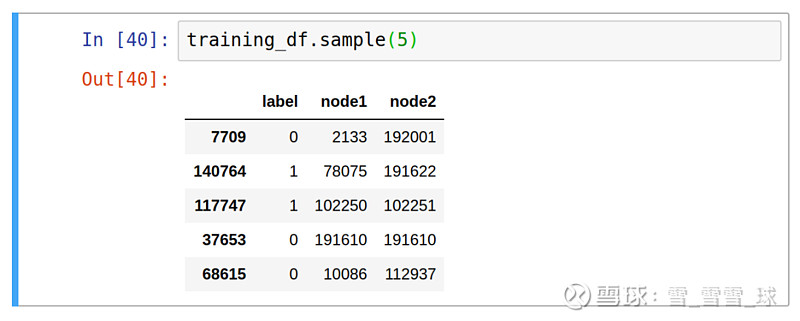
一个测试数据集的例子
执行相同的操作来创建测试数据框架,但是这次仅考虑后期图形中的关系:
# Find positive examplestest_existing_links = graph.run("""MATCH (author:Author)-[:CO_AUTHOR_LATE]->(other:Author)RETURN id(author) AS node1, id(other) AS node2, 1 AS label""").to_data_frame()# Find negative examplestest_missing_links = graph.run("""MATCH (author:Author)WHERE (author)-[:CO_AUTHOR_LATE]-()MATCH (author)-[:CO_AUTHOR_LATE*2..3]-(other)WHERE not((author)-[:CO_AUTHOR_LATE]-(other))RETURN id(author) AS node1, id(other) AS node2, 0 AS label""").to_data_frame()# Remove duplicates test_missing_links = test_missing_links.drop_duplicates()# Down sample negative examplestest_missing_links = test_missing_links.sample(n=len(test_existing_links))# Create DataFrame from positive and negative examplestest_df = test_missing_links.append( test_existing_links, ignore_index=True)test_df['label'] = test_df['label'].astype('category')
接下来,开始创建机器学习模型。
6、选择机器学习算法
我们将创建一个随机森林分类器,此方法非常适合数据集中包含强项和弱项的模型。尽管弱功能有时会有所帮助,但随机森林方法可以确保我们不会创建过度拟合训练数据的模型。使用以下代码创建模型:
from sklearn.ensemble import RandomForestClassifierclassifier = RandomForestClassifier(n_estimators=30, max_depth=10, random_state=0)
现在是时候设计一些用来训练模型的特征。特征提取是一种将大量数据和属性提取为一组具有代表性的数值(特征)的方法。这些特征会作为输入的数据,以便我们区分学习任务的类别/值。
7、生成链接预测特征
使用链接预测功能生成一些特征:
def apply_graphy_features(data, rel_type): query = """ UNWIND $pairs AS pair MATCH (p1) WHERE id(p1) = pair.node1 MATCH (p2) WHERE id(p2) = pair.node2 RETURN pair.node1 AS node1, pair.node2 AS node2, algo.linkprediction.commonNeighbors( p1, p2, {relationshipQuery: $relType}) AS cn, algo.linkprediction.preferentialAttachment( p1, p2, {relationshipQuery: $relType}) AS pa, algo.linkprediction.totalNeighbors( p1, p2, {relationshipQuery: $relType}) AS tn """ pairs = [{"node1": pair[0], "node2": pair[1]} for pair in data[["node1", "node2"]].values.tolist()] params = {"pairs": pairs, "relType": rel_type} features = graph.run(query, params).to_data_frame() return pd.merge(data, features, on = ["node1", "node2"])
此功能发起一个查询,该查询从提供的DataFrame中获取配对的节点,并对每一对节点进行以下计算:共同邻居(cn)、优先附件(pa)以及邻居总数(tn)
如下所示,我们可以将其应用于我们的训练并测试DataFrame:
training_df = apply_graphy_features(training_df, "CO_AUTHOR_EARLY")test_df = apply_graphy_features(test_df, "CO_AUTHOR")
对于训练数据框架,仅根据早期图形来计算这些指标,而对于测试数据框架,将在整个图形中进行计算。也可以使用整个图形来计算这些功能,因为图形的演变取决于所有时间,而不仅取决于2006年及以后的情况。
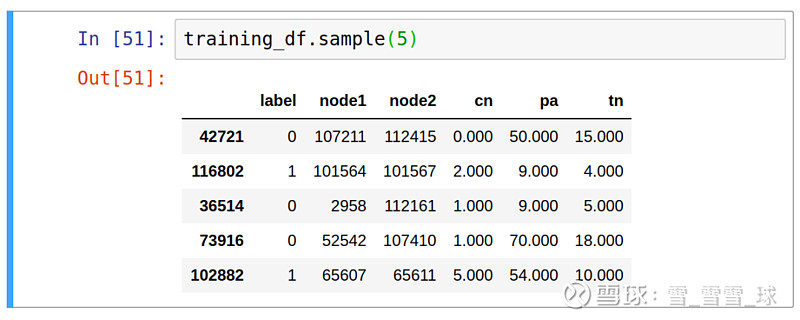
测试训练集
使用以下代码训练模型:
columns = ["cn", "pa", "tn"]X = training_df[columns]y = training_df["label"]classifier.fit(X, y)
现在的模型已经经过训练了,但还需要对它进行评估。
8、评估模型
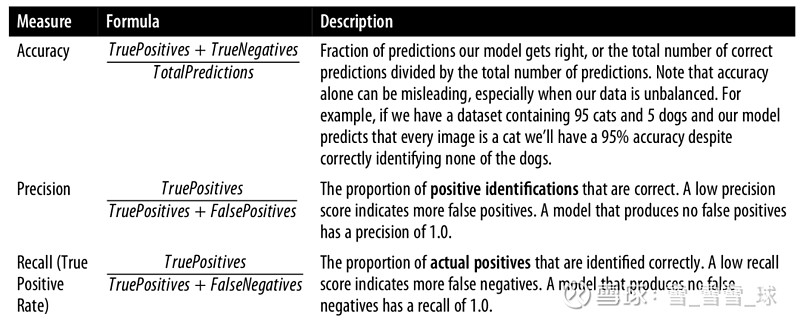
我们将计算其准确性,准确性和召回率,计算方法可参考下图,scikit-learn也内置了此功能,还可以得到模型中使用的每个特征的重要性。
from sklearn.metrics import recall_scorefrom sklearn.metrics import precision_scorefrom sklearn.metrics import accuracy_scoredef evaluate_model(predictions, actual): accuracy = accuracy_score(actual, predictions) precision = precision_score(actual, predictions) recall = recall_score(actual, predictions) metrics = ["accuracy", "precision", "recall"] values = [accuracy, precision, recall] return pd.DataFrame(data={'metric': metrics, 'value': values})def feature_importance(columns, classifier): features = list(zip(columns, classifier.feature_importances_)) sorted_features = sorted(features, key = lambda x: x[1]*-1)
keys = [value[0] for value in sorted_features] values = [value[1] for value in sorted_features] return pd.DataFrame(data={'feature': keys, 'value': values})
评估模型执行代码:
predictions = classifier.predict(test_df[columns])y_test = test_df["label"]evaluate_model(predictions, y_test)
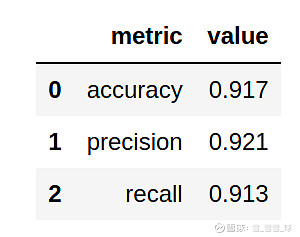
(准确率,精准度,召回度)
在各个方面的得分都很高。现在可以运行以下代码来查看哪个特征扮演了最重要的角色:
feature_importance(columns, classifier)
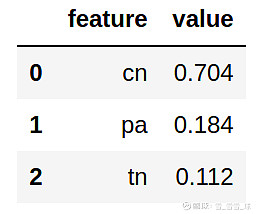
(特征重要度)
在上面我们可以看到,公共邻居(cn)是模型中的主要支配特征。共同邻居意味着作者拥有的未闭合的协同者三角的数量的计数,因此数值这么高并不奇怪。
接下来,添加一些从图形算法生成的新特征。
9、三角形与聚类系数
首先,在测试图和训练子图上运行三角计数算法。该算法可返回每个节点形成的三角形数量以及每个节点的聚类系数。节点的聚类系数表示其邻居也被连接的可能性。可以在Neo4j浏览器中运行以下Cypher查询,以在训练图上运行此算法:
CALL algo.triangleCount('Author', 'CO_AUTHOR_EARLY', { write:true, writeProperty:'trianglesTrain', clusteringCoefficientProperty:'coefficientTrain'});
然后执行以下Cypher查询以在测试图上运行:
CALL algo.triangleCount('Author', 'CO_AUTHOR', { write:true, writeProperty:'trianglesTest', clusteringCoefficientProperty:'coefficientTest'});
现在节点上有4个新属性:三角训练,系数训练,三角测试和系数测试。现在,在以下功能的帮助下,将它们添加到我们的训练和测试DataFrame中:
def apply_triangles_features(data,triangles_prop,coefficient_prop): query = """ UNWIND $pairs AS pair MATCH (p1) WHERE id(p1) = pair.node1 MATCH (p2) WHERE id(p2) = pair.node2 RETURN pair.node1 AS node1, pair.node2 AS node2, apoc.coll.min([p1[$triangles], p2[$triangles]]) AS minTriangles, apoc.coll.max([p1[$triangles], p2[$triangles]]) AS maxTriangles, apoc.coll.min([p1[$coefficient], p2[$coefficient]]) AS minCoeff, apoc.coll.max([p1[$coefficient], p2[$coefficient]]) AS maxCoeff """ pairs = [{"node1": pair[0], "node2": pair[1]} for pair in data[["node1", "node2"]].values.tolist()] params = {"pairs": pairs, "triangles": triangles_prop, "coefficient": coefficient_prop} features = graph.run(query, params).to_data_frame() return pd.merge(data, features, on = ["node1", "node2"])
这些参数与我们到目前为止使用的不同,它们不是特定于某个节点配对的,而是针对某个单一节点的参数。不能简单地将这些值作为节点三角或节点系数添加到我们的DataFrame中,因为无法保证节点配对的顺序,我们需要一种与顺序无关的方法。这里可以通过取平均值、值的乘积或通过计算最小值和最大值来实现此目的,如此处所示:
training_df = apply_triangles_features(training_df, "trianglesTrain", "coefficientTrain")test_df = apply_triangles_features(test_df, "trianglesTest", "coefficientTest")
现在可以训练与评估:
columns = [ "cn", "pa", "tn", "minTriangles", "maxTriangles", "minCoeff", "maxCoeff"]X = training_df[columns]y = training_df["label"]classifier.fit(X, y)predictions = classifier.predict(test_df[columns])y_test = test_df["label"]display(evaluate_model(predictions, y_test))
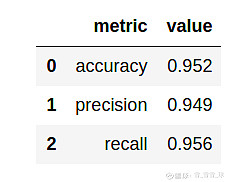
(准确率,精准度,召回度)
这些特征很有帮助!我们的每项参数都比初始模型提高了约4%。哪个特征最重要?
display(feature_importance(columns, classifier))
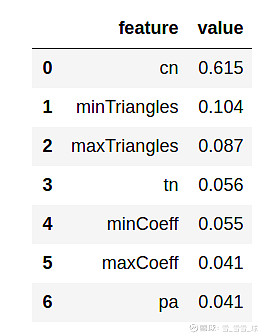
(特征重要度)
共同邻居还是最具有影响力的特征,但三角特征的重要性也提升了不少。
这篇教程即将结束,基于整个工作流程,希望还可以激发大家更多的思考:
(1)还有其他可添加的特征吗?这些特征能帮助我们创建更高准确性的模型吗?也许其他社区检测甚至中心算法也可能会有所帮助?
(2)目前,图形算法库中的链接预测算法仅适用于单零件图(两个节点的标签相同的图),该算法基于节点的拓扑;如果我们尝试将其应用于具有不同标签的节点(这些节点可能具有不同的拓扑),这就意味着此算法无法很好地发挥作用,所以目前也在考虑添加适用于其他图表的链接预测算法的版本,也欢迎大家在Github上一起交流。
Github地址:
原文链接:
(*本文为AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
开幕倒计时 2 天!2019 中国大数据技术大会(BDTC)即将震撼来袭!豪华主席阵容及百位技术专家齐聚,十余场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读。
推荐阅读
陆首群:评人工智能如何走向新阶段?准备面试题就够了吗?这些内容对考核更重要一张图生成定制版二次元人脸头像,还能“模仿”你的表情无需标注数据,利用辅助性旋转损失的自监督GANs,效果堪比现有最好方法激辩:机器究竟能否理解常识?Instagram个性化推荐工程中三个关键技术是什么?从YARN迁移到k8s,滴滴机器学习平台二次开发是这样做的【建议珍藏系列】如果你这样回答「什么是线程安全」,面试官都会对你刮目相看!985 高校计算机系学生都在用的笔记本,我被深深地种草了!从拨号到 5G :互联网登录完全指南

你点的每个“在看”,我都认真当成了AI