
作者 | Abhinav Sagar
翻译 | 申利彬
校对 | 吴金笛
来源 | 数据派THU(ID:DatapiTHU)
本文旨在让您把训练好的机器学习模型通过Flask API 投入到生产环境 。
当数据科学或者机器学习工程师使用Scikit-learn、Tensorflow、Keras 、PyTorch等框架部署机器学习模型时,最终的目的都是使其投入生产。通常,我们在做机器学习项目的过程中,将注意力集中在数据分析,特征工程,调整参数等方面。但是,我们往往会忘记主要目标,即从模型预测结果中获得实际的价值。
部署机器学习模型或者将模型投入生产,意味着将模型提供给最终的用户或系统使用。
然而机器学习模型部署具有一定的复杂性,本文可以让你把训练好的机器学习模型使用Flask API 投入生产环境。
我将使用线性回归,通过利率和前两个月的销售额来预测第三个月的销售额。
线性回归是什么?
线性回归模型的目标是找出一个或多个特征(自变量)和一个连续目标变量(因变量)之间的关系。如果只有一个特征,则称为单变量线性回归;如果有多个特征,则称为多元线性回归。
线性回归的假设
线性回归模型可以用下面的等式表示:
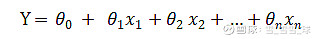

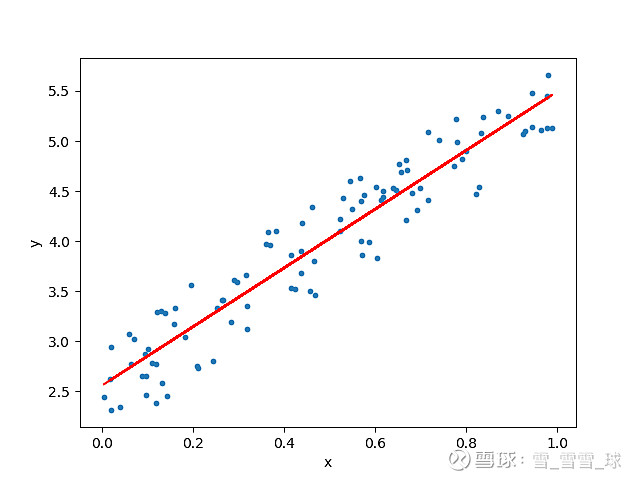
线性回归图解
为什么使用Flask?
容易上手使用内置开发工具和调试工具集成单元测试功能平稳的请求调度详尽的文档
项目结构
这个项目分为四个部分:
1. model.py -- 包含机器学习模型的代码,用于根据前两个月的销售额预测第三个月的销售额。
2. app.py – 包含用于从图形用户界面(GUI)或者API调用获得详细销售数据的Flask API,Flask API根据我们的模型计算预测值并返回。
3. request.py -- 使用requests模块调用app.py中定义的API并显示返回值。
4. HTML/CSS – 包含HTML模板和CSS风格代码,允许用户输入销售细节并显示第三个月的预测值。
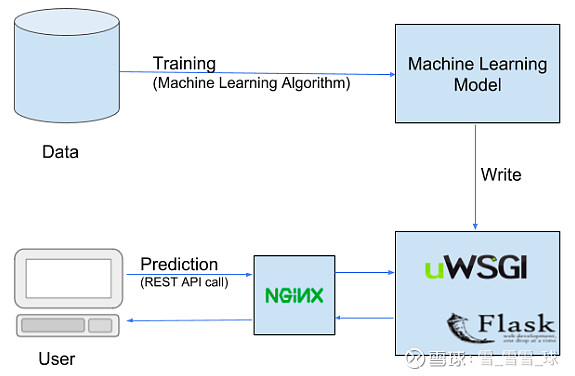
部署机器学习模型的Pipeline
环境和工具
1. Scikit-learn
2. Pandas
3. Numpy
4. Flask
代码在哪里呢?
从代码开始,完整的项目可以在github上找到(网页链接)。
我们使用HTML构建前端,让用户输入数据。这里有三个区域需要用户去填写—利率,第一个月的销售额以及第二个月的销售额。
接下来,使用CSS对输入按钮、登录按钮和背景进行了一些样式设置。
@import url(网页链接);
html { width: 100%; height:100%; overflow:hidden;
}body {width: 100%;height:100%;font-family: 'Helvetica';background: #000;
color: #fff;
font-size: 24px;
text-align:center;
letter-spacing:1.4px;}.login {position: absolute;
top: 40%;
left: 50%;
margin: -150px 0 0 -150px;
width:400px;
height:400px;}
login h1 { color: #fff;
text-shadow: 0 0 10px rgba(0,0,0,0.3);
letter-spacing:1px;
text-align:center;
}input {width: 100%;
margin-bottom: 10px;
background: rgba(0,0,0,0.3);
border: none;
outline: none;
padding: 10px;
font-size: 13px;
color: #fff;
text-shadow: 1px 1px 1px rgba(0,0,0,0.3);
border: 1px solid rgba(0,0,0,0.3);
border-radius: 4px;
box-shadow: inset 0 -5px 45px rgba(100,100,100,0.2), 0 1px 1px rgba(255,255,255,0.2);
-webkit-transition: box-shadow .5s ease;
-moz-transition: box-shadow .5s ease;
-o-transition: box-shadow .5s ease;
-ms-transition: box-shadow .5s ease;
transition: box-shadow .5s ease;
}
我为这个项目创建了一个定制的销售数据集,它有四列——利率、第一个月的销售额、第二个月的销售额和第三个月的销售额。
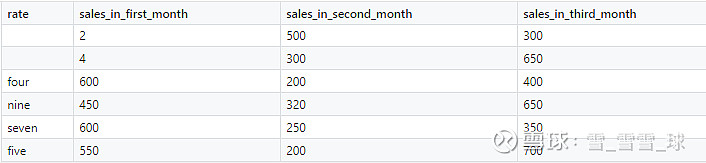
我们现在构建一个机器学习模型来预测第三个月的销售额。首先使用Pandas解决缺失值问题,当一项或多项指标没有信息时,就会有缺失值发生。使用0填充利率这一列的缺失值,平均值填充第一个月销售额中的缺失值,采用线性回归的机器学习算法。
序列化和反序列化
简而言之,序列化是一种在磁盘上写入python对象的方法,该对象可以传输到任何地方,然后通过python脚本反序列化(读)回去。
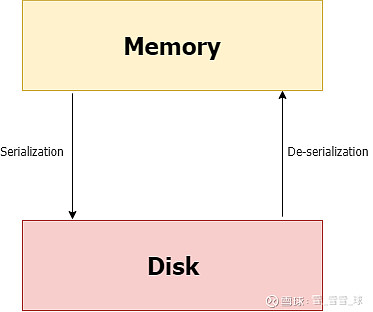
序列化 反序列化
使用Pickling将是python对象形式的模型转为字符流形式,其思想是这个字符流中包含了在另一个python脚本中重建这个对象所需的所有信息。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import pickle
dataset = pd.read_csv('sales.csv')
dataset['rate'].fillna(0, inplace=True)
dataset['sales_in_first_month'].fillna(dataset['sales_in_first_month'].mean(), inplace=True)
X = dataset.iloc[:, :3]
def convert_to_int(word):
word_dict = {'one':1, 'two':2, 'three':3, 'four':4, 'five':5, 'six':6, 'seven':7, 'eight':8,
'nine':9, 'ten':10, 'eleven':11, 'twelve':12, 'zero':0, 0: 0}
return word_dict[word]
X['rate'] = X['rate'].apply(lambda x : convert_to_int(x))
y = dataset.iloc[:, -1]
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X, y)
pickle.dump(regressor, open('model.pkl','wb'))
model = pickle.load(open('model.pkl','rb'))
print(model.predict([[4, 300, 500]]))
下一部分是构建一个API,反序列化这个模型为python对象格式,并通过图形用户界面(GUI)获取详细销售数据,根据模型计算预测值。我使用index.html设置主页,并在使用POST请求方式提交表单数据时,获取预测的销售值。
可以通过另一个POST请求将结果发送给results并展示出来。它接收JSON格式的输入,并使用训练好的模型预测出可以被API端点接受的JSON格式的预测值。
import numpy as np
from flask import Flask, request, jsonify, render_template
import pickle
app = Flask(__name__)model = pickle.load(open('model.pkl', 'rb'))
@app.route('/')
def home():
return render_template('index.html')
@app.route('/predict',methods=['POST'])
def predict():
int_features = [int(x) for x in request.form.values()]
final_features = [np.array(int_features)]
prediction = model.predict(final_features)
output = round(prediction[0], 2)
return render_template('index.html', prediction_text='Sales should
be $ {}'.format(output))
@app.route('/results',methods=['POST'])
def results():
data = request.get_json(force=True)
prediction = model.predict([np.array(list(data.values()))])
output = prediction[0]
return jsonify(output)
if __name__ == "__main__":
app.run(debug=True)
最后使用requests模块调用在app.py中定义的APIs,它的结果是第三个月销售额的预测值。
import requests
url = 'http://localhost:5000/results'
r = requests.post(url,json={'rate':5,
'sales_in_first_month':200, 'sales_in_second_month':400})
print(r.json()) Results
使用下面的命令运行Web应用程序。
python app.py
在web浏览器中打开网页链接,将显示如下所示的GUI.
原文标题:
How to Easily Deploy Machine Learning Models Using Flask
原文链接:
编辑:王菁
校对:王欣
扫码查看原文
▼▼▼

(*本文为AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。6.6 折票限时特惠(立减1400元),学生票仅 599 元!
推荐阅读
ICCV 2019 | 无需数据集的Student Networks
朱松纯:走向通用人工智能——从大数据到大任务
行人被遮挡问题怎么破?百度提出PGFA新方法,发布Occluded-DukeMTMC大型数据集 | ICCV 2019
2019年不可错过的45个AI开源工具,你想要的都在这里
宿命之战:程序员VS产品经理
美国爆料:量子计算机将如何颠覆一切?
“老赖”罗永浩:就算“卖艺”也会还债,孙宇晨:我买
重磅 | 边缘计算核心技术辨析
全民编程时代,程序员该如何保住饭碗?
中国区块链标准往事

你点的每个“在看”,我都认真当成了AI