“
编者按:近年来,在几大厂商的推动下,Chiplet成为了业界的关注点。但关于这个技术,你真的了解吗?下面让我们跟随作者的思路,去深入探究一下。
1、为什么做chiplet
这一轮chiplet 的风潮,是AMD 引领的。但是绝对不仅仅影响AMD,而是冲击了整个半导体行业。
其实chiplet 不算是新概念,早在Marvell 在2016 年公布Mochi 架构之前 ,2014 年海思与TSMC 的CoWoS 合作产品就上了新闻。
为什么要做chiplet,站在不同的位置,动机肯定不同。但是有一点有意思的地方,这是一个以fab 的角度,解决摩尔定律失效问题的方案,虽然TSMC 并没有把chiplet 当作一个新技术突破,而是把interposer 当作新技术突破,但半导体业界的其它公司的立场各不一致。Marvell 最初说的是Mask 太贵,Xilinix 是突破die size 上限(可怕的FPGA 公司),AMD 说良率问题,Intel 上来就是mix-and-match,而Darpa,Facebook,要的是第三方chiplet 的开放繁荣市场。
站在Fab 的位置,高良率的收益显著,即使算上封装的开销,其次可以不同工艺节点的die 混封,有利于最新工艺的销售。而且如果把memory 与logic 单元封装在一起,无论是性能,功耗,还是尺寸大小方面的收益,其实还有管脚(pin)的收益,都是巨大,当然,这种情况下,价格就小贵了。
因此单纯从生产角度看,大型最先进工艺的芯片,或者对性能,功耗和尺寸有超高要求,而价值比较高的芯片,适合做chiplet 的设计。
Chiplet 是针对超贵芯片的一种相对省钱设计,在初期。
站在2014 年左右开始chiplet 计划的fabless 的芯片设计公司角度看,如果公司内部的产品线复杂,例如海思,Marvell,而每一个产品的数目不巨大(Marvell 的VP,公开抱怨过苹果与三星,这种公司杀入半导体设计产业,造成出货量骤减,新工艺又贵),chiplet 的重用性的好处巨大。
在2016 年,Darpa 启动的Chips 项目,把这种chiplet Reuse 的想法,推到了整个产业界面前。
但是AMD 的EYPC 系列的成功,才真正让chiplet 进入主流业界视线。
更多的玩家进入,更多的设计样本,推动成本的下降,成本的下降推动chiplet 生态发展。chiplet 的发展前景如何,特别是独立第三chiplet 供应商的商业模式是否成立,谁会从中获益,谁会被产业链优化出局,现在尚未可知。
特别是互联网公司的介入,让这个本身就具有颠覆行业能力的技术,更为特出的重要。
2、Chiplet 的历史与现状
本来应该按时间顺序写,但是我想想,按照公司来写,其实参考性更高。一个公司的发展路径,是一个公司和它的上下游合作伙伴的智慧结晶。半导体行业的架构师,多数拿着超过市场平均价的高薪,规划着5 年,甚至10 年的路标,真是集智慧,对行业理解,和对行业影响力为一身的强者工作。
而chiplet 起初是fab 为了解决fab 中的一些问题而提出来的方案,而且技术突破的难点都在fab 侧。因此我把fab 的技术发展列为技术挑战,而不是历史。
2.1 AMD
2.1.1 EPYC (Naples)
EPYC 是AMD 在服务器CPU 市场上的翻身帐开始,在发布会上,AMD 明晃晃的提出打破摩尔定律的限制,这个来自fab 的说法。
每个EPYC 处理包括4 个Zeppelin die,使用的还是2D 的 MCM (Multi-chip module)封装。
AMD 的革命性 the Infinity Fabric,不仅仅是die-to-die 的互联总线,还是processor-to-processor 的互联总线。从这里也可以看出来,cache coherent 互联总线设计,和CPU 的设计关系紧密,凡是 cache coherent 互联总线的标准背后都有家CPU的设计公司。

图 2.1 AMD EPYC 1st Gen
Zeppelin die 包含2 个core complex-CCX。一个Zeppelin die 做桌面产品,2个Zeppelin die 做高端桌面产品, 4 个Zeppelin die 就是服务器产品。
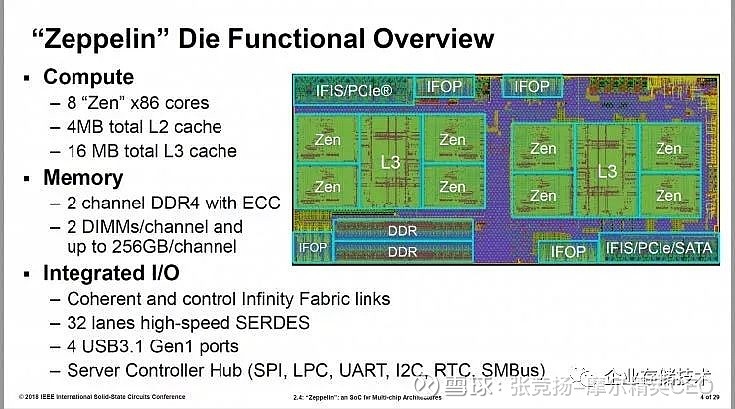
图 2.2 Zeppelin Die
单独看, 每个Zeppelin die 都包括单独的memory, IO complex,infinityFabric 的控制与接口,下图更清晰一点。每个Zeppelin die 是213mm^2,4 个die 就是852mm^2。AMD 给了如果用一个single chip 设计的话,die 的大小大约就是777mm^2,也就是说有10%的面积损耗,但是777mm^2 非常接近reticle limit size 了。
名词解释 reticle limit size, 这是光刻机能够处理的最多的尺寸。对于193iimmersion steppers 这个限制就是33*26, 856mm2, TSMC 的12nm 工艺,估计TSMC 会设置成815 这类数字。
对于单一产品的生产测试,良率,最后的价格,我相信,AMD 的工程师与架构师一定反复核算过。Intel 的工程师与架构师采取冗余设计来保护single chip 设计,这也是同一个die,有不同的核数的原因。这两种方式都是在提高良率,降低制造成本,以损失性能的代价。
但是如果从公司层面看,对于研发成本,一个Zeppelin die 可以覆盖服务器和桌面两个市场,这个收益明显。想想AMD $6.48 billion 的收入,与Intel 的$70.848billion, 合情合理。[TSMC 台积电的2018 收入是US$32.47 billion]其实从Intel 的lakefield 上看,10nm CPU/GPU die 加 22nm 的I/O die,尺寸上的收益明显,重用22nm 的I/Odie,对于开放成本,时间,相比收益也是不错的。
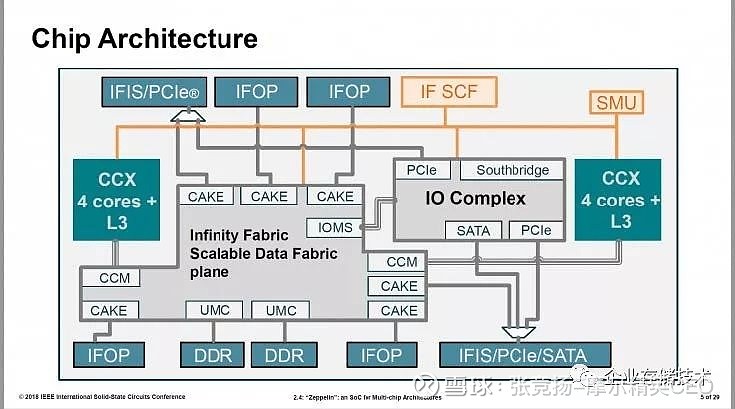
图 2.3 EPYC(Naples)的架构
最后放一张chiplet 的代价。

图2.4 EPYC(Naples) 内部带宽
2.1.2 EPYC (Rome)
Rome 的设计,甚至比Naples 还难做决定。要提高IPC,要双倍性能。
而且不能再一个die,同时兼顾服务器和PC 市场。AMD 试图在一个chiplet 上加倍核数(就是说要设计一个400+mm^2),然后保持4 个die 的设计,然而向现实妥协的结果是9个die 的设计。
而且从一个chiplet 上包含内存控制器,I/O 和Infinity 互联的接口, 转变为有一个中央集中式I/O 和内存控制器die,而且这个集中IOD 仍然有14nm 工艺,CCD 仍然保持8 个核的设计。8 个CCD die, 一个IOD,最高核数为64 个。
每个CCD 上的核数,可以根据良率变化,每个SKU 上的chiplet 数目也可以选择,因此真正最终产品的核数,有多种组合。
好消息是Rome 的下一代Milan 仍然是9die 的设计,有点tock 的意思。而且I/Odie 看起来变化不大,不知道是不是重用旧设计,仅仅升级工艺,但是Milan 的CCD 的设计有增强。这也是chiplet 设计的好处,不同的die 可以分离演进。服务器的IOD 和Client 的IOD 也演进为两个设计。
Rome 的CCD 的面积是74mm2,包括了3.9B 的transistors。对比Zepplin 的CCX面积大约是88mm2,2.8B 的transistors,感觉改进还是巨大的,7nm 的工艺进步也是显著的。Rome 的IOD 有125mm2,

图 2.5 EPYC(Naples)与 EPYC (Rome)
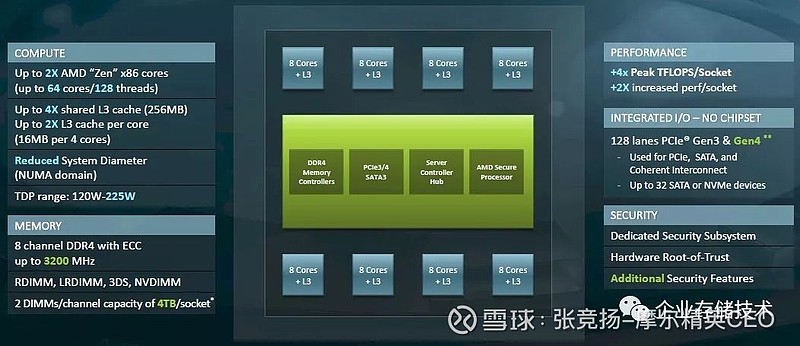
图2.6 EPYC (Rome)
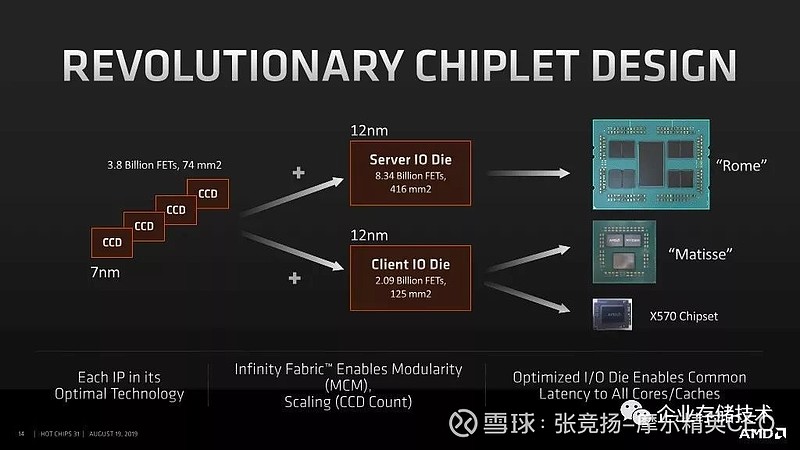
图 2.7 AMD Chiplet 设计路标
2.1.3 Ryzen (Matisse)
我这里并不想过多的分析Ryzen,只是想指出,Ryzen 产品线重用了 EYPC Rome 的CCD。只是单独配了一个Client IOD。
对于产品线复杂的公司,chiplet 设计,极好的降低了总研发费用。

图 2.8 Ryzen (Matisse) 架构

图 2.9 Ryzen (Matisse)
2.2 Intel
Intel 真是一个复杂的公司,首先,它可不是fabless,它是唯一一家有fab 的半导体设计公司。真心想知道,它的这种超强商业模式,在这轮chiplet 浪潮中,会不会受影响呢。
前面有说, chiplet 是fab 主导开始的,解决最新工艺贵,且良率低,或者超大芯片到达物理极限的问题的。Intel 在fab 技术和制定业界标准上都强,EMIB, HBM 的3D 封装, AIB 的总线, Foveros,CXL 这些都是Intel 的出品。
2.2.1 Altera Stratix 10 FPGA
Stratix 10 是Intel 第一款使用EMIB 的设计,中心是FPGA die,周围是6 个chiplet。4 个高速transceiver chiplet 和2 个高带宽memory chiplet。这6 个chiplet,是来自三个不同fab 的6 个不同工艺chiplet,用来证明不同fab 之间的强大互操作性。
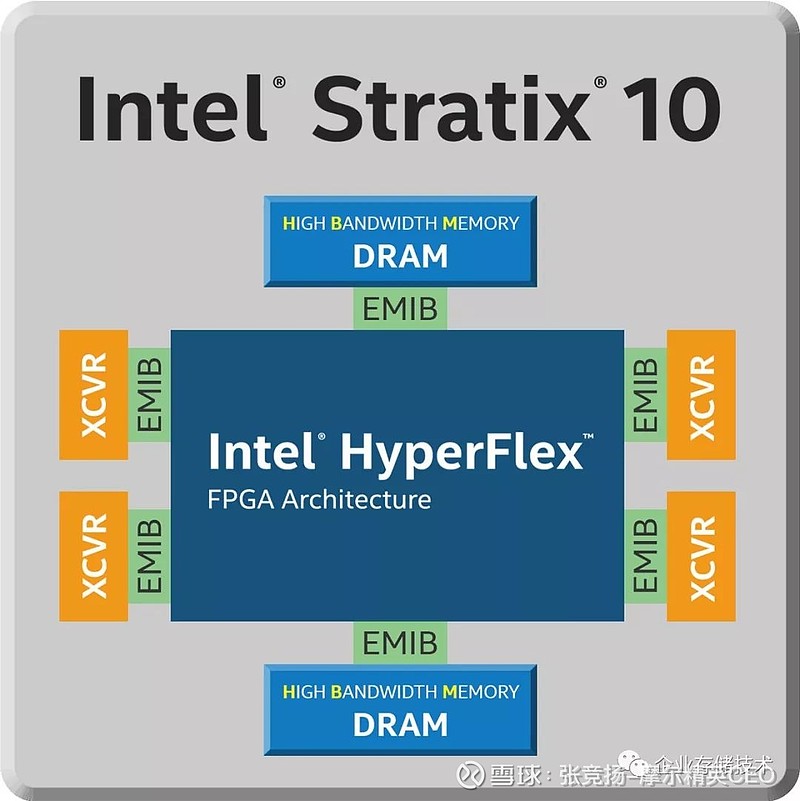
图 2.10 Stratix 10
2.2.2 Lakefield SoC
Stratix 10 是用的EMIB,所谓的2.5D 封装技术, Lakefield 亲孩子,就是用上了3D 封装,当然Intel 重新给它了一个名字Foveros。

图 2.11 Lakefield 架构
Lakefield 有两个技术有趣点,一是不同核的big.little 混合架构,二是chiplet 设计,一个compute die,一个base die。Base die,主要是I/O 功能,性能不敏感,因此可以用22nm 工艺,而混合了大小CPU 核,IPU,GPU 的compute die,会持续演进,用7nm,5nm 工艺。
3D Foveros 封装技术,从名字上可以感觉一二,我们留到技术挑战那章再讲。
2.2.3 Barefoot the Tofino 2 chip 7nm plus chiplet switch ASIC
这是Ethernet Switch(以太网交换机)市场的第一款分离为chiplet 的设计,broadcom 的7nm Trident 4倒是还是单片设计。
Switch ASIC 长期以来都是把模拟和逻辑部分放在一起设计的,模拟部分,其实和逻辑部分,演进的时间表完全不同。如果是单芯片设计,模拟部分也不得不随着逻辑部分的工艺演进前进。如果采用chiplet 分离设计,例如Barefoot 的模拟部分,采用老一点的工艺,Barefoot 没有透露,因此大家从28nm,16nm,12nm 都有猜, 逻辑部分则是最新的7nm 工艺。
Chiplet 不仅仅带来了模拟部分的工艺节省,而且还可以通过不同的chiplet 配置,来提供不同的SKU。对比传统的单片设计,干脆disable 一部分芯片的方式,这种chiplet 就经济实惠多了。

图2.12 Barefoot 的Tofino2
想想Barefoot 的startup 出身,猜有chiplet 的设计,也算是顺理成章。
2.3 Xlinix
讲chiplet FPGA 公司必须有名字。FPGA 公司因其属性和高利润性,一直是各种先进工艺的率先使用者。而FPGA 一开始采用Chiplet 方案,就是为了打破fab 的物理限制,做超大芯片。
讲真,其实所有AISC 的新应用领域,都是从FPGA 的设计开始的。2011 Virtex-7 2000T 就是4 个die 的chiplet 设计。文献20 中的Xilinx 的白皮书,是比较好的对于chiplet 技术的一个探讨。Chiplet 并不是一个新技术,只是在新工艺节点越来越贵,竞争越来越激烈的半导体市场上,又重新被广泛应用了而已。
Xilinx 号称提供业界唯一的同构和异构的3D IC。

图2.13 virtex-7 系列
2.4 Marvell Mochi
Marvell 提出Mochi 概念,最大的驱动力是降低成本,模块化芯片设计,像LEGO 那样,提高模块的重用性。借助基本模块的重用,还能在保持灵活性的同时,加快新产品的上市时间。
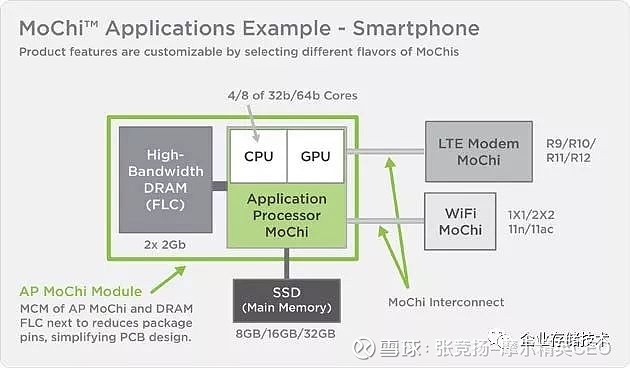
图2.14 Mochi 应用的案例 智能手机
2015 年当时的Marvell CEO Sehat Sutardja 估计到2018 年开一个Mask 的价格是$10million (我也不知道这个价格,是不是对,知道的同志们,可以吱一声),因此要有25M 的出货量的产品,ROI 才合算。不知道大家对25M 这个数字是否有感觉,但是基本上,服务器(约12M),4G 基站(约7M),汽车(86M)这种市场就不用考虑最新工艺了。
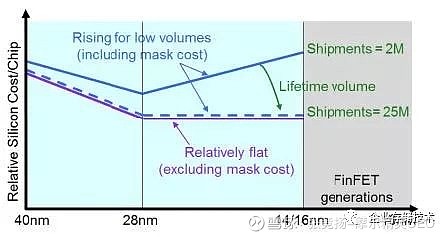
图2.15 芯片研发成本
Marvell 采用了Kandou Glasswing IP 作为die-to-die 的接口, 而Kandou 依然非常活跃在chiplet 的互联标准组织中。但是这个chiplet 互联标准,是一个新生态的核心标准,竞争者众多。
2.5 Hisilicon
海思的第一片公开的chiplet 设计,就是2014 年TSMC 16nm FinFet 网络芯片。这个时间,这个工艺,这个CoWoS,都是闪闪亮的顶配。
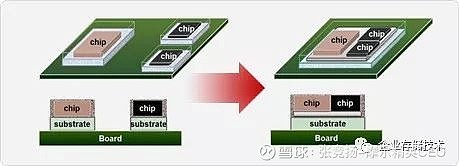
图2.16 CoSoW
海思因为其属性,公开消息并不多。往往是因为合作伙伴,需要展示自己的技术突破,海思才被迫营业,站台示众。这个海思1616 就是这样挂在TSMC 的网站上的。
晟腾910 的8 个chiplet 设计,融合了HBM die,逻辑部分与I/O 部分分离,两个dummydie,超大总die size 等特点。也算是业界标杆性设计。
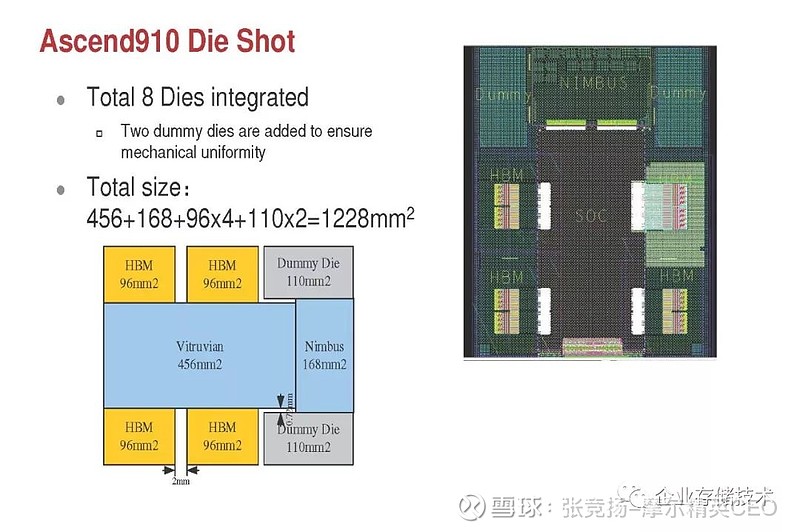
图 2.17 Ascend910
2.6 HBM
HBM 从设计开始就是3D 封装的,因此有些讨论chiplet 的文章,并不包括HBM。但是在我看来,凡是采取多die 封装的,都算是chiplet 的范畴。Memory die 也是chiplet,而且memory 公司卖Known good die 的历史蛮长。
2016 年 AMD Radeon R9 Fury X 是第一个采用HBM 的芯片。Nvidia 紧随其后。Fujitsu 的PostK supercomputer 设计,也采用了CPU die 与HBM 一起封装的设计,因此A64FX 芯片的管脚,要比一般的芯片精简不少。
3、Chiplet 的技术挑战
先坦白的说,出来接口标准这一节以外,这一章,我也是外行。而且说起标准这事,我也只熟悉几个。
我给大家把资料备齐,大家鉴别着,当参考材料读一下吧。
3.1 Interconnect interface 的标准化
互联接口标准化重要么?仅仅在需要对接来自不同厂家的chiplet 的时候,才重要。一个公司内部,他们自己心里有数就好。
现有接口能解决这个问题么?其实能的,如果不追求高带宽,低延迟,这类性能指标。回想一下前面的案例, 逻辑die 和IO die 之间,需要什么接口?
3.1.1 DARPA Chips 项目
DARPA 先讲了一个与商业芯片公司不同的动机,就是如何降低高研发成本,特别是对于量不大的应用。DARPA 用的芯片,估计量也大不到哪里去,却不得不用啊,商业市场的那套“走量”的生意模式,这里肯定是不行的。
可以如logo 一样拼接组合的chiplet,肯定是一条出路。
CHIPS 项目的一个重大成果就是Intel 的AIB( Advanced Interface Bus),这是一个royalty free 的chiplet-to-chiplet (or die-to-die) 的物理层接口标准。Intel® Stratix® 10 FPGA 用的就是AIB 接口。(在github 上找得到代码的项目,才是真.开源项目)
但是有意思的是2018 年开始的ERI 电子复兴计划第二期中的3DSoC Three Dimensional Monolithic System-on-chip 3D 单芯片系统。
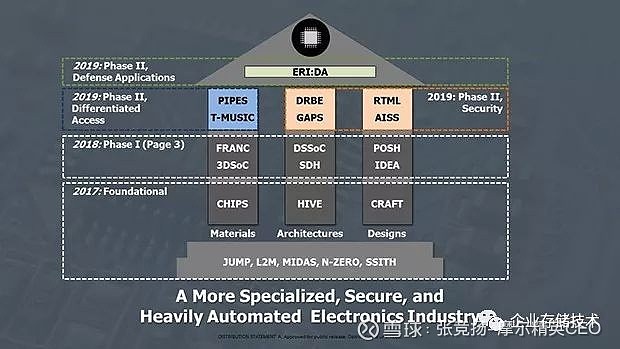
图3.1 DARPA ERI
3.1.2 OCP ODSA相对于DARPA 纠结的哪些闪光的logo 们,OCP 的ODSA 工作组相对平民化很多,当然, Global Foundries 在镇场子。ODSA 把die-to-die 的层次。而且ODSA 把chiplet marketplace 的口号提了出来。
这个和DARPA 解决量小芯片项目的目的是不同的。
Chiplet 市场这件事,如果做得好,可以改变产业界的分工合作关系。所谓的优化供应链,就是新的一轮洗牌。
ODSA 的接口标准, 分层概念提的很清晰,CCIX+PCIe 也是看熟悉。但是如果试图包括一切,标准的统一性就不会好,用来对接的标准不
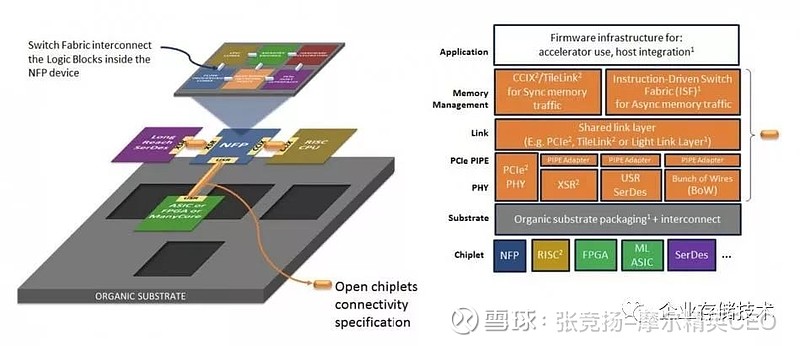
图3.2 OCP ODSA
3.1.3 OIF,JEDEC,CCIX 和其它
OIF 有一些关于die-to-die 的讨论(看了看,不算明白)。JEDEC 一直出memory 接口标准的。历史上一个好标准,被借用在其它地方的事情也时有发生。Memory 业界一直出好标准。
还有一些公司,就不搞什么标准,直接上产品,例如Cadence Ultralink D2D PHY IP ,Synopsys 新出的 DesignWare die to die PHY IP 简单,高效,我喜欢。
物理层,把chiplet 对接在一起。而在物理层之上,有两种类型倾向的语以接口,I/O 类型的和memory 类型的。保持一致性,以硬件复杂换取软件简单?还是不保持一种性追求高效。ARM,AMD 一开始支持的CCIX,与Intel 主导的CXL,哪个能成为chipet-tochiplet的主流标准?目前尚未有结论。
3.2 封装技术
如果可以,我想写略。
标准,我多少还是知道的。封装技术,就实打实的不行了。我把能用来索引的关键字留下来。你们自己努力吧。
3.2.1 MCM - Multi Chip Module3.2.2 Interposer3.2.3 TSV3.2.4 TSMC CoWoS3.2.5 Fan-Out Wafer-level packaging3.2.6 InFo WLP and fan-in WLP3.2.7 Samsung FOPLP3.2.8 Intel EMIB3.2.9 Intel Foveros3.2.10 价格与性能的折衷3.2.11 高价值小批量的芯片3.2.12 大规模生产类型的芯片
3.3 KGD&测试
工业标准测试非常重要。通常,我们只做整个芯片的测试,但是现在我们需要在封装前,测试出“known good die”。业界需要一个KGD 策略和一个测试策略,目前还是空缺的。测试裸die,可比测试整个芯片麻烦多了,也难多了。
而且要独立测试chiplet,对于功能并不独立的某些chiplet,也很复杂。
3.4 EDA工具
EDA 工具对chiplet 的支持,仿真,都是需要慢慢补齐的。
3.5 多供应商的电源,功耗管理问题
多个chiplet 的多供应商的电源,功耗管理,都是问题。需要标准,也需要业界统一。
4、Chiplet 的商业模式挑战
如果上章的技术问题,都能完美的解决。让我们重新考虑一下chiplet 这个技术方案的商业动机。
最初chiplet 是为了打破芯片面积的物理上限,而近期是为了解决最新工艺节点的高昂IC设计费。
例如,28nm 需要$51.3 million, 7nm 芯片需要$297.8 million (International Business Strategies (IBS))
人间理想,一个开放的数量巨大的chiplet 市场, 客户可以自由的mix-and-match, 不同的逻辑使用不同的工艺节点,IP 可以重用,研发费用在多个设计之间平摊, 创新度剧增。
谁受益,谁有可能受损?工厂和封装厂肯定是受益方。
IP 公司会是受益方么?卖IP RTL 风险小,把自己手中的IP 升级为chiplet 利润高。
Chiplet 降低了半导体设计的门槛,对于新进入的公司,是一个好消息,但是这chiplet 的这种模块化设计,其实拆分了半导体公司的方案,消弱了整体竞争能力。
对于最终的买家来说,降成本的chiplet 无疑是受欢迎的。
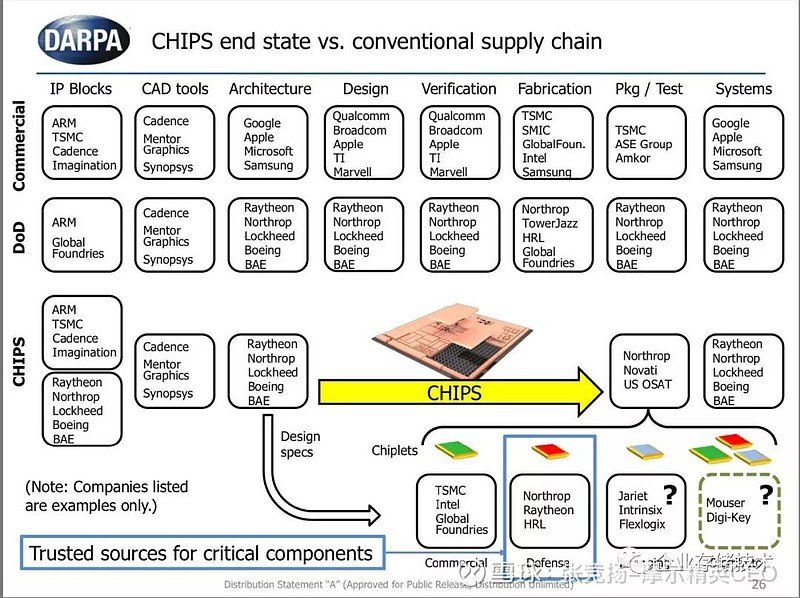
图4.1 Darpa 的预言
放一张Darpa 的chips 产业最终状态和传统供应链的对比,那些设计,验证的fabless 芯片公司不见了。
如果只是小startup 公司与IP 公司,参与Chiplet 的生态建设,对于半导体这个投资巨大的产业来说,只是促进产业创新,不会有大风浪。
如果大型hyperscale 公司,例如AWS,Google,也加入到这场新生态的建设之中,那么现存的大鱼们,就要有危机意识了。
有端到端设计能力的超大型hyperscale,可以站在上帝视角,优化产业链。这是可怕之处。
参考文献
1.Marvell Mochi 架构 网页链接 announces its first 16nm FinFET networking chip: 32-core ARM Cortex-A57网页链接)3.Interposer 技术 :Past,now, future , TSMC 侯上勇网页链接(4)%20SEMICON%20Taiwan%202016%20Interposer%20Technology%20SYHou_hand%20out.pdf4.Q&A: A Deeper Look at Marvell’s MoChi Technology网页链接 Sutardja Sees Simpler SoCs Marvell CEO Promotes MoChi, FLC to Reduce
Design Complexit 网页链接 网页链接 网页链接 网页链接 网页链接 网页链接 网页链接
28.网页链接 网页链接 网页链接 网页链接 网页链接 网页链接
原文链接:网页链接
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2151期内容,欢迎关注。
推荐阅读
★新型存储盘点,谁会是继任者?
★全球IC设计公司排名中的X元素
★日本半导体的一张王牌
半导体行业观察
『半导体第一垂直媒体』
实时 专业 原创 深度
识别二维码,回复下方关键词,阅读更多
中美半导体|AI|台积电|英伟达|ASML|RISC-V|EDA|松下
回复 投稿,看《如何成为“半导体行业观察”的一员 》
回复 搜索,还能轻松找到其他你感兴趣的文章!