

新智元编译
来源:GitHub
编译:金磊
【新智元导读】近期,TensorFlow官方推文推荐了一款十分有趣的项目——用Attention模型生成图像字幕。而该项目在GitHub社区也收获了近十万“点赞”。项目作者Yash Katariya十分详细的讲述了根据图像生成字幕的完整过程,并提供开源的数据和代码,对读者的学习和研究都带来了极大的帮助与便利。

TensorFlow官方推文近期力荐了一款在Github上获赞十万之多的爆款项目——利用Attention模型为图像生成字幕。

Image Captioning是一种为图像生成字幕或者标题的任务。给定一个图像如下:

我们的目标就是为这张图生成一个字幕,例如“海上冲浪者(a surfer riding on a wave)”。此处,我们使用一个基于Attention的模型。该模型能够在生成字幕的时候,让我们查看它在这个过程中所关注的是图像的哪一部分。
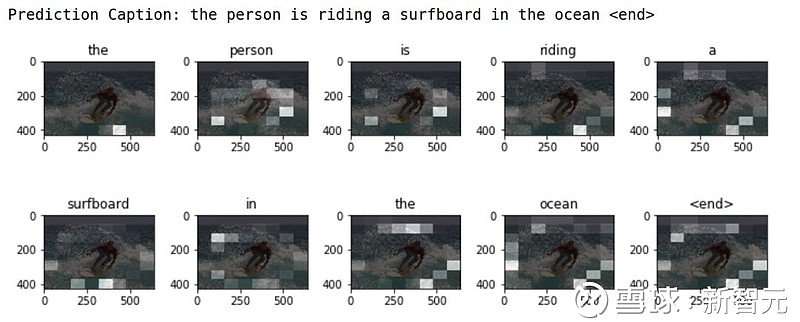
预测字幕:一个人在海上冲浪(the person is riding a surfboard in the ocean)
该模型的结构与如下链接中模型结构类似:网页链接
代码使用的是tf.keras和eager execution,读者可以在链接指南中了解更多信息。
tf.keras: 网页链接
eager execution: 网页链接
这款笔记是一种端到端(end-to-end)的样例。如果你运行它,将会下载 MS-COCO数据集,使用Inception V3来预处理和缓存图像的子集、训练出编码-解码模型,并使用它来在新的图像上生成字幕。
如果你在 Colab上面运行,那么TensorFlow的版本需要大于等于1.9。
在下面的示例中,我们训练先训练较少的数据集作为例子。在单个P100 GPU上训练这个样本大约需要2个小时。 我们先训练前30,000个字幕(对应约20,000个图像,取决于shuffling,因为数据集中每个图像有多个字幕)。
# Import TensorFlow and enable eager execution
# This code requires TensorFlow version >=1.9
import tensorflow as tf tf.enable_eager_execution()
# We'll generate plots of attention in order to see which parts of an image
# our model focuses on during captioning
import matplotlib.pyplot as plt
# Scikit-learn includes many helpful utilities
from sklearn.model_selection
import train_test_split
from sklearn.utils import shuffle
import re
import numpy as np
import os
import time
import json
from glob import glob
from PIL import Image
import pickle
下载并准备MS-COCO数据集
我们将使用MS-COCO数据集来训练我们的模型。 此数据集包含的图像大于82,000个,每个图像都标注了至少5个不同的字幕。 下面的代码将自动下载并提取数据集。
注意:需做好提前下载的准备工作。 该数据集大小为13GB!!!
annotation_zip = tf.keras.utils.get_file('captions.zip', cache_subdir=os.path.abspath('.'), origin = '网页链接 extract = True) annotation_file = os.path.dirname(annotation_zip)+'/annotations/captions_train2014.json'name_of_zip = 'train2014.zip'if not os.path.exists(os.path.abspath('.') + '/' + name_of_zip): image_zip = tf.keras.utils.get_file(name_of_zip, cache_subdir=os.path.abspath('.'), origin = '网页链接 extract = True) PATH = os.path.dirname(image_zip)+'/train2014/'else: PATH = os.path.abspath('.')+'/train2014/'
限制数据集大小以加速训练(可选)
在此示例中,我们将选择30,000个字幕的子集,并使用这些字幕和相应的图像来训练我们的模型。 当然,如果你选择使用更多数据,字幕质量将会提高。
# read the json file
with open(annotation_file, 'r') as f: annotations = json.load(f)
# storing the captions and the image name in vectors
all_captions = [] all_img_name_vector = []
for annot in annotations['annotations']: caption = ' ' + annot['caption'] + ' ' image_id = annot['image_id'] full_coco_image_path = PATH + 'COCO_train2014_' + '%012d.jpg' % (image_id) all_img_name_vector.append(full_coco_image_path) all_captions.append(caption)
# shuffling the captions and image_names together# setting a random state
train_captions, img_name_vector = shuffle(all_captions, all_img_name_vector, random_state=1)
# selecting the first 30000 captions from the shuffled set
num_examples = 30000
train_captions = train_captions[:num_examples] img_name_vector = img_name_vector[:num_examples]
len(train_captions), len(all_captions)
使用InceptionV3来预处理图像
接下来,我们将使用InceptionV3(在Imagenet上预训练过的)对每个图像进行分类。 我们将从最后一个卷积层中提取特征。
首先,我们需要将图像按照InceptionV3的要求转换格式:
调整图像大小为(299,299)
使用preprocess_input方法将像素放置在-1到1的范围内(以匹配用于训练InceptionV3的图像的格式)。
def load_image(image_path): img = tf.read_file(image_path) img = tf.image.decode_jpeg(img, channels=3) img = tf.image.resize_images(img, (299, 299)) img = tf.keras.applications.inception_v3.preprocess_input(img)
return img, image_path
初始化InceptionV3并加载预训练的Imagenet权重
为此,我们将创建一个tf.keras模型,其中输出层是InceptionV3体系结构中的最后一个卷积层。
每个图像都通过networkd传递(forward),我们将最后得到的矢量存储在字典中(image_name -- > feature_vector)。
因为我们在这个例子中使用了Attention,因此我们使用最后一个卷积层。 该层的输出形状为8x8x2048。
在所有图像通过network传递之后,我们挑选字典并将其保存到磁盘。
image_model = tf.keras.applications.InceptionV3(include_top=False, weights='imagenet') new_input = image_model.input hidden_layer = image_model.layers[-1].output image_features_extract_model = tf.keras.Model(new_input, hidden_layer)
将InceptionV3中提取出来的特征进行缓存
我们将使用InceptionV3预处理每个图像并将输出缓存到磁盘。 缓存RAM中的输出会更快但内存会比较密集,每个映像需要8 x 8 x 2048个浮点数。 这将超出Colab的内存限制(尽管这些可能会发生变化,但实例似乎目前有大约12GB的内存)。
通过更复杂的缓存策略(例如,通过分割图像以减少随机访问磁盘I / O)可以改善性能(代价是编写更多的代码)。
使用一个GPU在Colab中运行大约需要10分钟。 如果你想查看进度条,可以:安装tqdm(!pip install tqdm),然后将下面这行代码:
for img,path in img_dataset:
改为:
for img,path in dqtm(img_dataset):
# getting the unique imagesencode_train = sorted(set(img_name_vector))# feel free to change the batch_size according to your system configurationimage_dataset = tf.data.Dataset.from_tensor_slices( encode_train).map(load_image).batch(16)for img, path in image_dataset: batch_features = image_features_extract_model(img) batch_features = tf.reshape(batch_features, (batch_features.shape[0], -1, batch_features.shape[3])) for bf, p in zip(batch_features, path): path_of_feature = p.numpy().decode("utf-8") np.save(path_of_feature, bf.numpy())
预处理并标注字幕
首先,我们将标记字幕(例如,通过空格拆分)。 这将为我们提供数据中所有单个单词的词汇表(例如,“冲浪”,“足球”等)。
接下来,我们将词汇量限制在前5,000个单词以节省内存。 我们将用“UNK”(对应于unknown)替换所有其他单词。
最后,我们创建一个word→index的映射,反之亦然。
然后我们将所有序列填充到与最长序列相同的长度。
# This will find the maximum length of any caption in our datasetdef calc_max_length(tensor): return max(len(t) for t in tensor)
# The steps above is a general process of dealing with text processing# choosing the top 5000 words from the vocabularytop_k = 5000tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=top_k, oov_token="", filters='!"#$%&()*+.,-/:;=?@[\]^_`{|}~ ') tokenizer.fit_on_texts(train_captions) train_seqs = tokenizer.texts_to_sequences(train_captions)
tokenizer.word_index = {key:value for key, value in tokenizer.word_index.items() if value token in the word2idx dictionarytokenizer.word_index[tokenizer.oov_token] = top_k + 1tokenizer.word_index['
'] = 0
# creating the tokenized vectorstrain_seqs = tokenizer.texts_to_sequences(train_captions)
# creating a reverse mapping (index -> word)index_word = {value:key for key, value in tokenizer.word_index.items()}
# padding each vector to the max_length of the captions# if the max_length parameter is not provided, pad_sequences calculates that automaticallycap_vector = tf.keras.preprocessing.sequence.pad_sequences(train_seqs, padding='post')
# calculating the max_length # used to store the attention weightsmax_length = calc_max_length(train_seqs)
将数据分为训练集和测试集
# Create training and validation sets using 80-20 split
img_name_train, img_name_val, cap_train, cap_val = train_test_split(img_name_vector,
cap_vector,
test_size=0.2,
random_state=0)
len(img_name_train), len(cap_train), len(img_name_val), len(cap_val)
图片和字幕已就位!
接下来,创建一个tf.data数据集来训练模型。
# feel free to change these parameters according to your system's configuration
BATCH_SIZE = 64
BUFFER_SIZE = 1000
embedding_dim = 256
units = 512
vocab_size = len(tokenizer.word_index)
# shape of the vector extracted from InceptionV3 is (64, 2048)
# these two variables represent that
features_shape = 2048
attention_features_shape = 64
# loading the numpy files
def map_func(img_name, cap):
img_tensor = np.load(img_name.decode('utf-8')+'.npy')
return img_tensor, cap
dataset = tf.data.Dataset.from_tensor_slices((img_name_train, cap_train))
# using map to load the numpy files in parallel
# NOTE: Be sure to set num_parallel_calls to the number of CPU cores you have
# 网页链接
dataset = dataset.map(lambda item1, item2: tf.py_func(
map_func, [item1, item2], [tf.float32, tf.int32]), num_parallel_calls=8)
# shuffling and batching
dataset = dataset.shuffle(BUFFER_SIZE)
# 网页链接
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.prefetch(1)
我们的模型
有趣的是,下面的解码器与具有Attention的神经机器翻译的示例中的解码器相同。
模型的结构灵感来源于上述的那篇文献:
在这个示例中,我们从InceptionV3的下卷积层中提取特征,给出了一个形状向量(8,8,2048)。
我们将其压成(64,2048)的形状。
然后该矢量经过CNN编码器(由单个完全连接的层组成)处理。
用RNN(此处为GRU)处理图像,来预测下一个单词。
def gru(units):
# If you have a GPU, we recommend using the CuDNNGRU layer (it provides a
# significant speedup).
if tf.test.is_gpu_available():
return tf.keras.layers.CuDNNGRU(units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
else:
return tf.keras.layers.GRU(units,
return_sequences=True,
return_state=True,
recurrent_activation='sigmoid',
recurrent_initializer='glorot_uniform')
classBahdanauAttention(tf.keras.Model):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, features, hidden):
# features(CNN_encoder output) shape == (batch_size, 64, embedding_dim)
# hidden shape == (batch_size, hidden_size)
# hidden_with_time_axis shape == (batch_size, 1, hidden_size)
hidden_with_time_axis = tf.expand_dims(hidden, 1)
# score shape == (batch_size, 64, hidden_size)
score = tf.nn.tanh(self.W1(features) + self.W2(hidden_with_time_axis))
# attention_weights shape == (batch_size, 64, 1)
# we get 1 at the last axis because we are applying score to self.V
attention_weights = tf.nn.softmax(self.V(score), axis=1)
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * features
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
class CNN_Encoder(tf.keras.Model):
# Since we have already extracted the features and dumped it using pickle
# This encoder passes those features through a Fully connected layer
def __init__(self, embedding_dim):
super(CNN_Encoder, self).__init__()
# shape after fc == (batch_size, 64, embedding_dim)
self.fc = tf.keras.layers.Dense(embedding_dim)
def call(self, x):
x = self.fc(x)
x = tf.nn.relu(x)
return x
class RNN_Decoder(tf.keras.Model):
def __init__(self, embedding_dim, units, vocab_size):
super(RNN_Decoder, self).__init__()
self.units = units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = gru(self.units)
self.fc1 = tf.keras.layers.Dense(self.units)
self.fc2 = tf.keras.layers.Dense(vocab_size)
self.attention = BahdanauAttention(self.units)
def call(self, x, features, hidden):
# defining attention as a separate model
context_vector, attention_weights = self.attention(features, hidden)
# x shape after passing through embedding == (batch_size, 1, embedding_dim)
x = self.embedding(x)
# x shape after concatenation == (batch_size, 1, embedding_dim + hidden_size)
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
# passing the concatenated vector to the GRU
output, state = self.gru(x)
# shape == (batch_size, max_length, hidden_size)
x = self.fc1(output)
# x shape == (batch_size * max_length, hidden_size)
x = tf.reshape(x, (-1, x.shape[2]))
# output shape == (batch_size * max_length, vocab)
x = self.fc2(x)
return x, state, attention_weights
def reset_state(self, batch_size):
return tf.zeros((batch_size, self.units))
encoder = CNN_Encoder(embedding_dim)
decoder = RNN_Decoder(embedding_dim, units, vocab_size)
optimizer = tf.train.AdamOptimizer()
# We are masking the loss calculated for padding
def loss_function(real, pred):
mask = 1 - np.equal(real, 0)
loss_ = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=real, logits=pred) * mask
return tf.reduce_mean(loss_)
开始训练
我们提取存储在各个.npy文件中的特征,然后通过编码器传递这些特征。
编码器输出,向解码器传奇隐藏状态(初始化为0)和解码器输入(开始标记)。
解码器返回预测值并隐藏状态。
然后将解码器隐藏状态传递回模型,并使用预测值来计算损失。
使用teacher-forcing决定解码器的下一个输入(teacher-forcing是一种将目标单词作为下一个输入传递给解码器的技术)。
最后一步是计算gradients并将其应用于优化器并反向传递。
# adding this in a separate cell because if you run the training cell
# many times, the loss_plot array will be reset
loss_plot = []
EPOCHS = 20
for epoch in range(EPOCHS):
start = time.time()
total_loss = 0
for (batch, (img_tensor, target)) in enumerate(dataset):
loss = 0
# initializing the hidden state for each batch
# because the captions are not related from image to image
hidden = decoder.reset_state(batch_size=target.shape[0])
dec_input = tf.expand_dims([tokenizer.word_index['']] * BATCH_SIZE, 1)
with tf.GradientTape() as tape:
features = encoder(img_tensor)
for i in range(1, target.shape[1]):
# passing the features through the decoder
predictions, hidden, _ = decoder(dec_input, features, hidden)
loss += loss_function(target[:, i], predictions)
# using teacher forcing
dec_input = tf.expand_dims(target[:, i], 1)
total_loss += (loss / int(target.shape[1]))
variables = encoder.variables + decoder.variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables), tf.train.get_or_create_global_step())
if batch % 100 == 0:
print ('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1,
batch,
loss.numpy() / int(target.shape[1])))
# storing the epoch end loss value to plot later
loss_plot.append(total_loss / len(cap_vector))
print ('Epoch {} Loss {:.6f}'.format(epoch + 1,
total_loss/len(cap_vector)))
print ('Time taken for 1 epoch {} sec\n'.format(time.time() - start))
plt.plot(loss_plot)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Loss Plot')
plt.show()
字幕“诞生”了!
评估函数类似于training-loop(除了不用teacher-forcing外)。
在每个时间步骤对解码器的输入是其先前的预测以及隐藏状态和编码器输出。
当模型预测到最后一个token的时候停止预测。
每个时间步骤都存储attention权重。
def evaluate(image):
attention_plot = np.zeros((max_length, attention_features_shape))
hidden = decoder.reset_state(batch_size=1)
temp_input = tf.expand_dims(load_image(image)[0], 0)
img_tensor_val = image_features_extract_model(temp_input)
img_tensor_val = tf.reshape(img_tensor_val, (img_tensor_val.shape[0], -1, img_tensor_val.shape[3]))
features = encoder(img_tensor_val)
dec_input = tf.expand_dims([tokenizer.word_index['']], 0)
result = []
for i in range(max_length):
predictions, hidden, attention_weights = decoder(dec_input, features, hidden)
attention_plot[i] = tf.reshape(attention_weights, (-1, )).numpy()
predicted_id = tf.multinomial(tf.exp(predictions), num_samples=1)[0][0].numpy()
result.append(index_word[predicted_id])
if index_word[predicted_id] == '':
return result, attention_plot
dec_input = tf.expand_dims([predicted_id], 0)
attention_plot = attention_plot[:len(result), :]
return result, attention_plot
def plot_attention(image, result, attention_plot):
temp_image = np.array(Image.open(image))
fig = plt.figure(figsize=(10, 10))
len_result = len(result)
for l in range(len_result):
temp_att = np.resize(attention_plot[l], (8, 8))
ax = fig.add_subplot(len_result//2, len_result//2, l+1)
ax.set_title(result[l])
img = ax.imshow(temp_image)
ax.imshow(temp_att, cmap='gray', alpha=0.6, extent=img.get_extent())
plt.tight_layout()
plt.show()
# captions on the validation set
rid = np.random.randint(0, len(img_name_val))
image = img_name_val[rid]
real_caption = ' '.join([index_word[i] for i in cap_val[rid] if i notin [0]])
result, attention_plot = evaluate(image)
print ('Real Caption:', real_caption)
print ('Prediction Caption:', ' '.join(result))
plot_attention(image, result, attention_plot)
# opening the image
Image.open(img_name_val[rid])
在你的图像上试一下吧!
下面我们提供了一种方法,你可以使用我们刚训练过的模型为你自己的图像添加字幕。 请记住,它是在相对少量的数据上训练的,你的图像可能与训练数据不同(因此出来的结果可能会很奇怪,做好心理准备呦!)。
GitHub原文链接:
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号: aiera2015_3 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。