《科创板日报》5月10日讯连AI大模型也开始“卷”价格了,这次举起“砍价屠刀”的搅局者,没有科技巨头加持,也没有互联网大厂背景,而是和幻方这家量化私募有着千丝万缕关系。
日前,深度求索开源第二代MoE大模型DeepSeek-V2,顶着“价格屠夫”的称号一炮而红——性能比肩GPT-4、价格仅有GPT-4的近百分之一。
值得注意的是,DeepSeek出品公司是杭州深度求索人工智能基础技术研究有限公司(以下简称“杭州深度求索”),此前多家媒体报道显示,深度求索为幻方旗下组织机构。且幻方量化曾在去年4月发布公告称,将全力投身到人工智能技术之中,成立新的独立研究组织“深度求索”。
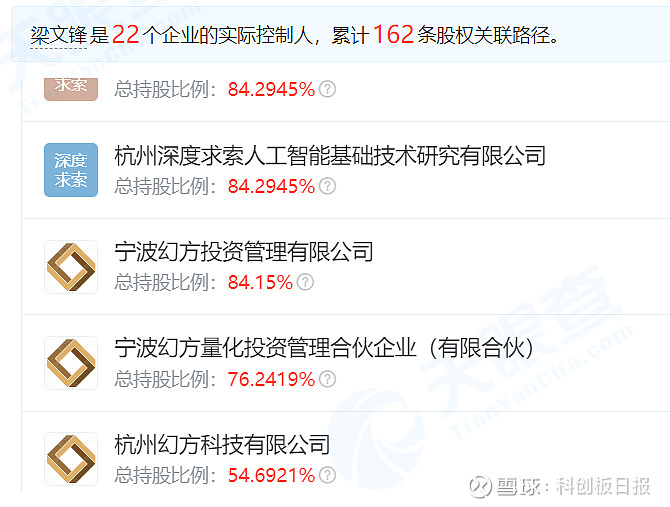
另据天眼查数据显示,杭州深度求索的背后为幻方量化实控人梁文锋,后者在杭州深度求索最终受益的股份比例超八成。
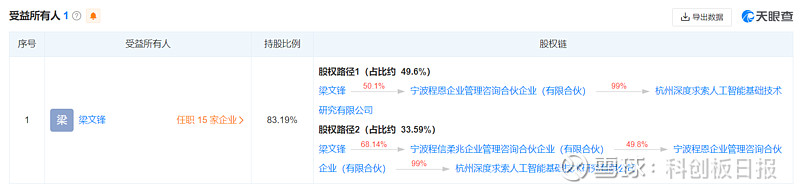
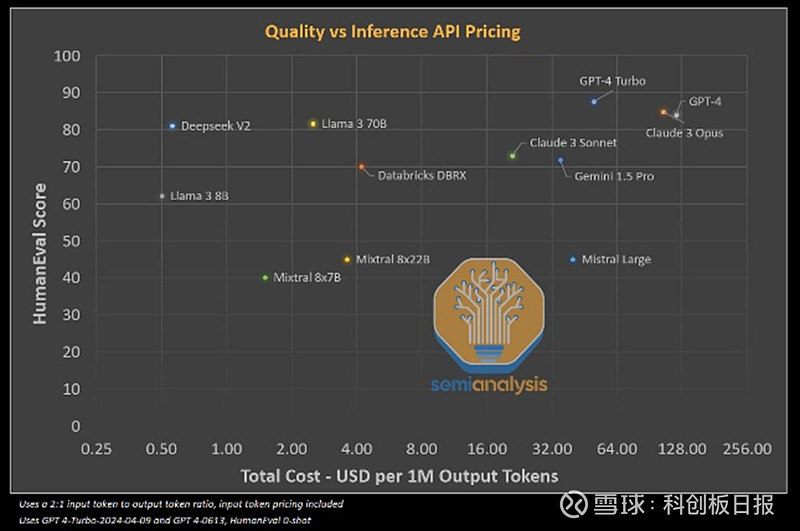
性能方面,DeepSeek-V2拥有2360亿参数,其中每个token210亿个活跃参数。据官网介绍,DeepSeek-V2中文综合能力(AlignBench)“在众多开源模型中最强”,超过GPT-4,与GPT-4-Turbo,文心 4.0等闭源模型在评测中处于同一梯队;英文综合能力(MT-Bench)与LLaMA3-70B处于同一梯队,超过最强MoE开源模型Mixtral8x22B。
算力需求方面,分析机构SemiAnalysis指出,DeepSeek-V2训练参数量达8.1万亿个token,而表现出“难以置信”的训练效率,计算量仅为Meta Llama 3 70B的1/5,更只有GPT-4 的1/20。
如果说上述这些只是AI技术迭代浪潮中常见的“技术炫技”,那么价格则是该模型最引发关注的要点。
目前DeepSeek-V2 API定价为:每百万token输入1元、输出2元(32K上下文),仅是GPT-4的近百分之一水平。
SemiAnalysis给出了“便宜得难以置信”的评价。据该机构计算,在其算力服务力利用率最高的情况下,DeepSeek每台服务器每小时收益可达35.4美元,毛利率在70%以上。
幻方量化,这家号称量化界“四大天王”之一的私募,管理规模曾一度飙升至千亿,但之后幻方产品大幅回撤,管理规模也迅速缩水。去年年末,幻方还遭投资者控诉称,“花100万元买了幻方量化的产品两年多,赎回时只剩约80万元,还要被计提3万多的业绩报酬”。
幻方量化去年4月公告成立“深度求索(DeepSeek)”之后,深度求索发布了第一代大模型,并将免费商用,完全开源。
彼时,幻方量化的公告曾在业内引发“AI炒股说”的议论,但幻方量化董事总经理陆政哲表示,“我用中文重申一下:AGI不是用来炒股的,有大得多的用处和大得多的价值。”
在此之前,幻方量化已于2019年投资2亿元自主研发深度学习训练平台“萤火一号”,搭载了1100块GPU;2021年幻方量化对“萤火二号”投入增加到10亿元,且搭载了约1万张英伟达A100显卡——也是在那一年末,OpenAI的ChatGPT横空出世,掀起全球AI热潮和英伟达GPU“抢购潮”。
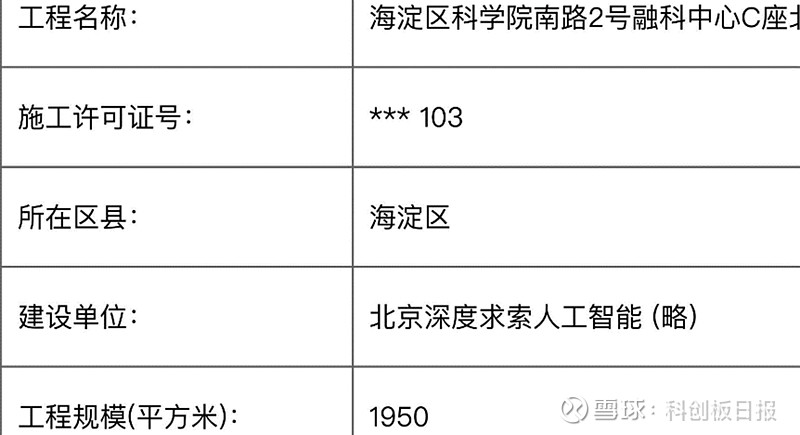
值得一提的是,为了投入人工智能,幻方还租下“20个网球场”。去年末有媒体报道称,北京深度求索人工智能(以下简称“北京深度求索”)正在进行装修招标,办公室选址于北京海淀区融科中心,装修工程面积达1950平方米,并获得了施工许可证。
近2000平方米的面积是什么概念?一般情况下,相当于20个标准网球场或者2个标准足球场的大小。
而天眼查显示,北京深度求索则由上文提到的杭州深度求索100%控股。