以下文章来源于量化智投,作者国金金工高智威团队
Alpha掘金系列之十
机器学习全流程重构——细节对比与测试

高智威
金工首席分析师
执业编号:S1130522110003

王小康
金工分析师
执业编号:S1130523110004
本篇报告主要探索领域包括特征和标签的数据预处理方式,使用全A股票训练还是成分股训练,使用一次性训练、滚动或是扩展训练的效果区别,分类模型和回归模型的差异,损失函数改为IC后是否有进一步提升,不同的树集成方法优劣对比。
最终,我们保持与原框架一致,使用GBDT和NN两大类模型分别在不同成分股上训练,得到了在样本外效果突出的因子。最终,我们结合交易实际,构建了基于各宽基指数的指数增强策略。其中,沪深300指数增强策略年化超额收益达到15.43%,超额最大回撤为2.87%。中证500指增策略年化超额收益20.50%,超额最大回撤8.39%。中证1000指增策略年化超额收益32.25%,超额最大回撤4.33%。
+
目录
一、不同数据预处理方式的对比
1.1数据准备与预处理的方式
1.2 不同数据预处理方式对比
二、全A训练还是成分股训练?
三、一次性、滚动还是扩展训练?
四、分类还是回归?
五、损失函数是否有必要修改为IC?
六、GBDT, DART or RF?
七、改进后因子与策略效果
7.1 因子测试结果
7.2 基于GBDT+NN的指数增强策略
报告导读
+
一、不同数据预处理方式的对比
1.1数据准备与预处理的方式
● 在特征层面,首先将停牌日的股票行情数据均统一赋值为NaN,计算相关特征时则会对应计算为NaN;在标签层面,对月度调仓的策略而言,统一使用T+1至T+21日的收盘价信息计算收益率等数据作为标签,以满足次日调仓的需求。
● 为了高效地实现梯度下降,考虑如下标准化处理选择:
1)截面Z-Score标准化(CSZScore):对所有数据按日期聚合后进行Z-Score处理
2)截面排序标准化(CSRank):对所有数据按日期聚合后进行排序处理,将排序结果作为模型输入
3)数据集整体Z-Score标准化(ZScore):用训练集的参数去标准化整个数据集。
4)数据集整体Minmax标准化(MinMax):MinMax能严格限制上下界,且保留了数据间的大小关系。
5)数据集整体Robust Z-Score标准化(RobustZScore):使得到的均值标准差指标。
1.2 不同数据预处理方式对比
● 在沪深300成分股上,遍历不同处理方式,并分别使用LightGBM和GRU模型。
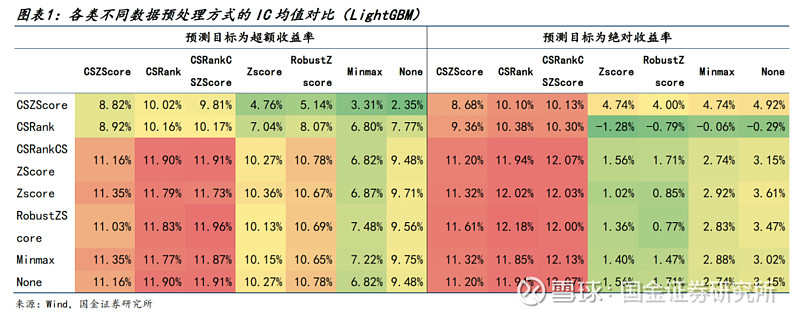
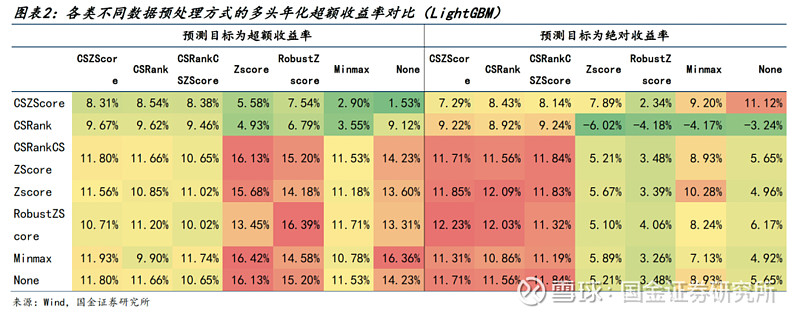

● 针对LightGBM模型,有如下结论:
1)对特征做截面处理会显著影响LightGBM的学习效果,不同日期间的相对大小关系被忽视会影响截面模型对于未来收益率的预测能力。
2)若使用绝对收益率作为预测目标,则必须进行截面标准化处理。
3)相较于超额收益率作为预测目标,绝对收益率能获得相对更高的IC(不到1%),但多头超额和回撤水平显著不如超额收益率。
4)若使用超额收益率作为预测目标再进行截面标准化处理,效果与绝对收益率基本一致,反而失去了其超额收益率的信息。而对整个数据集进行标准化处理能得到相对更优的多头超额和回撤水平。几类对比发现,RobustZscore表现更加稳健。
综上,针对GBDT类模型,我们使用超额收益率作为预测目标,特征和标签均使用RobustZscore处理。

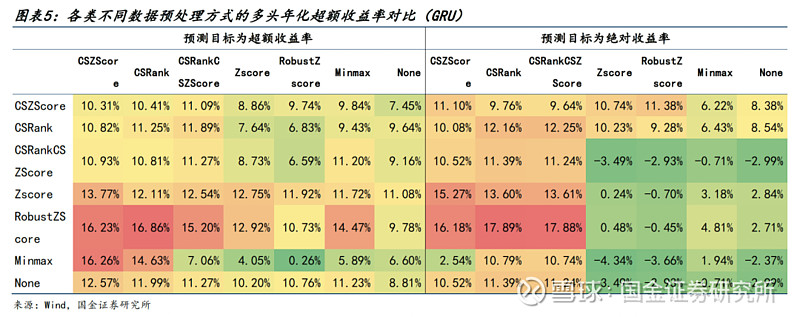
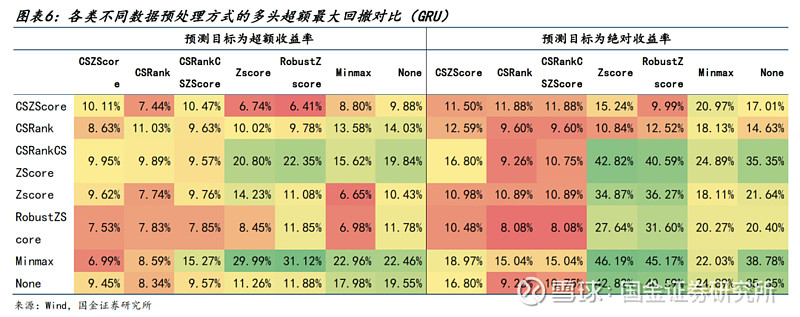
● 针对GRU模型,有如下不同点:
1)无论使用哪种预测目标,进行截面标准化都是一种更优选择。我们认为主要原因在于,时序类模型需要学习一个时间窗口(step_len)内的时序变化信息,而截面标准化使每天的标签均处于同样的分布水平,从而能使模型对股票间不同日期相对大小关系的变化更加敏感。
2)特征层面作为模型的输入变量,截面标准化会使数据丧失很多时序信息。因此对特征进行截面标准化也会使预测结果在各指标有相对更差的表现。
3)考虑到截面排序会使数据分布区间发生变化,我们尝试了叠加截面标准化的操作,使数据分布区间回归正常状态。发现最终预测效果差异不大,无太大必要。
综上,针对(时序)神经网络类模型,我们选择超额收益率作为预测目标,特征采用RobustZScore方式处理,标签使用CSRank处理。
+
二、全A训练还是成分股训练?
● 分别对LightGBM和GRU在沪深300、中证500和中证1000上进行训练,效果如下:
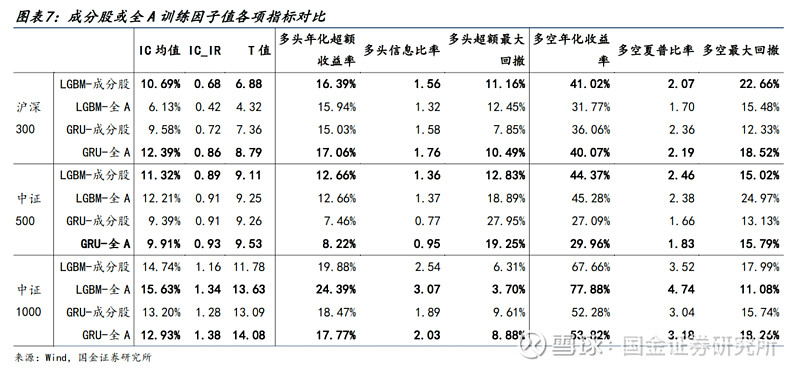
● 针对沪深300有如下结论:
1)对于更需要大量样本进行投喂训练的GRU而言,明显使用全A股票会对预测结果带来明显的提升。
2)对于具有少量样本就能充分学习的LightGBM而言,使用沪深300成分股能够有效使模型学到大市值股票的选股逻辑和规律,相较于全A而言有明显优势。
● 针对中证500有如下结论:
1)对于GRU模型,同样是大样本量的全A训练更具优势。
2)而LightGBM模型使用两种成分股样本训练效果已经比较接近,使用成分股训练时,虽然IC相关指标略低一些,但多头和多空的最大回撤明显更低,具有在不同市场环境中更稳定的优势。
● 针对中证1000有如下结论:
1)在样本特征极其相似的情况下,LightGBM使用全A训练效果略微更优。
2)GRU模型则差异极小,当样本量上升一定水平后,继续扩大样本量所带来的提升已经比较有限。
+
三、一次性、滚动还是扩展训练?
● 我们对比三种方式:
1)一个固定的时间区间数据集进行完整一次性训练
2)分年度将训练集、验证集和测试集向前滚动训练
3)保持训练集起始时间不变进行扩展训练
且控制数据长度:训练集(8年)、验证集(2年)、测试集(1年)
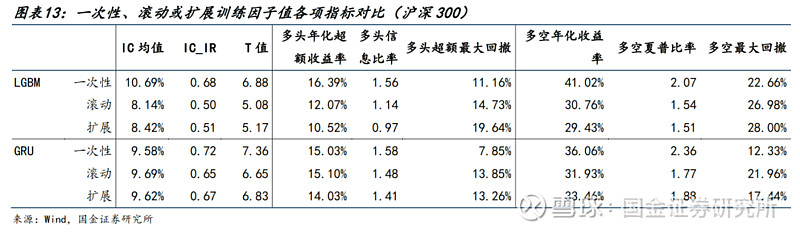
● 对于因子基本指标(IC、多空等):
1)LightGBM使用一次性训练效果明显更优。
2)GRU使用一次性训练可以更好地控制回撤。
3)不同训练方式的净值出现差距基本从2021年开始,这可能和当时的核心资产报团、大小盘风格轮动等均有一定关系。
● 为了缓解过拟合,我们会设置EarlyStopping的patience=N。这对于更容易过拟合的LightGBM模型更为重要。
+
四、量化选股:分类还是回归?
● 我们使用MSE作为回归的损失函数,Cross Entropy(交叉熵)作为分类的损失函数。在分类任务中,以收益率分位数0.3、0.7作为阈值,将所有股票分为三类。
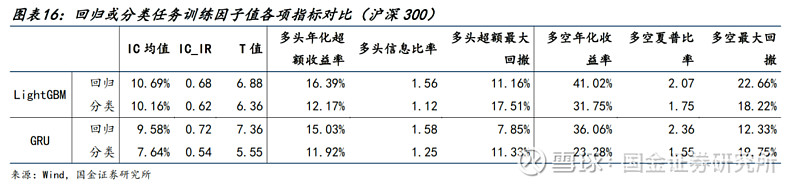
● 有如下结论:
1)LightGBM和GRU均在回归下体现出更好的IC和多空收益,可能原因是这样更好地保留每个样本标签的独立性。
2)此外,我们尝试了扩大分类组数(比如10),均对结论没有影响。
+
五、损失函数是否有必要修改为IC?
● 对比MSE、IC(pearson相关系数)、RankIC(spearman秩相关系数)三种损失函数。
● 针对GRU模型,考虑mini-batch训练,有三种模式:
1)不分交易日划分Batch且整个样本内计算损失函数(TotalBatch-TotalLoss),
2)按照交易日划分Batch且整个样本内计算损失函数(DailyBatch-TotalLoss),
3)按照交易日划分Batch且日度计算损失函数后求均值(DailyBatch-DailyLoss),
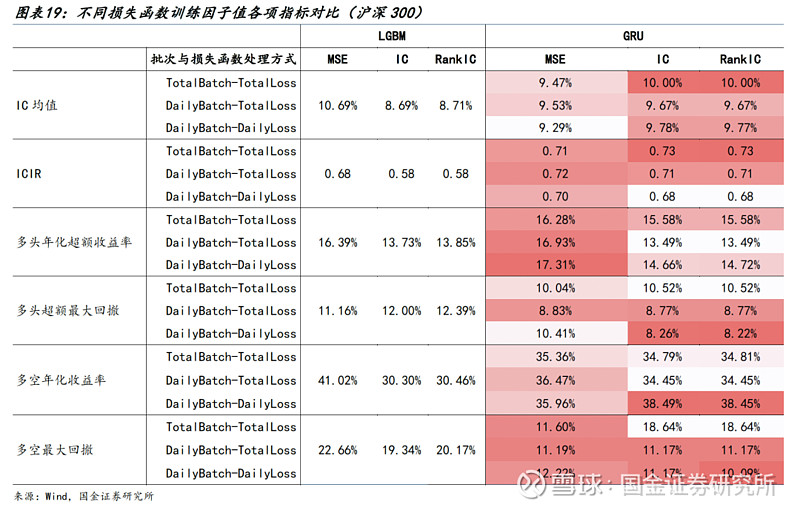
● 有如下结论:
1)GRU模型在IC或RankIC损失函数下,有更好的IC;但LightGBM更偏好MSE
2)从ICIR,多头收益、多空收益的角度而言,MSE损失函数反而具有一定优势
3)回撤相关指标则对于不同损失函数未能展现出明显规律。
● 因此,将损失函数修改为IC、RankIC并无太大必要,对样本的批次处理按照交易日划分并以此计算损失函数也无明显优势。
+
六、GBDT, DART or RF?
● 我们针对LightGBM模型在沪深300成分股分别尝试了三种不同的算法,得到因子主要指标如下:
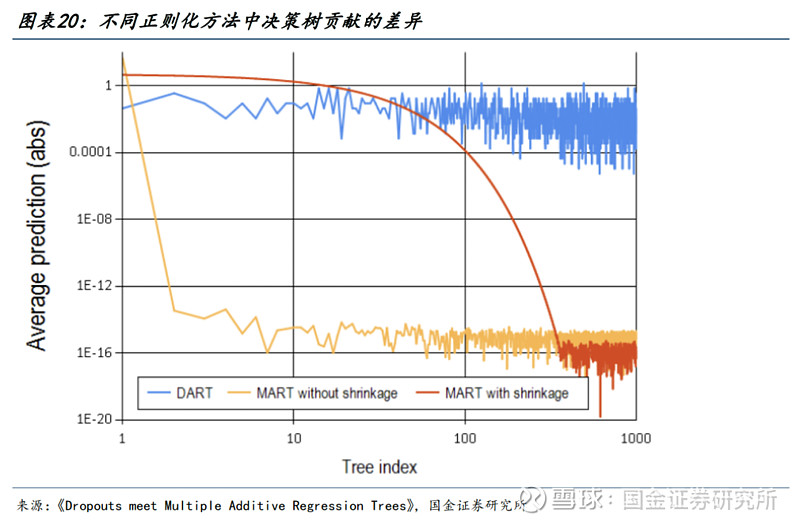
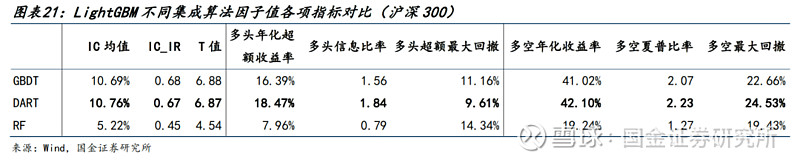
● 有如下结论:
1)DART算法在各项指标中均表现最佳,多头年化超额收益率相较于GBDT有接近2%的提升,且回撤水平也有所降低。
2)在一定程度上说明,量化领域训练时使用带有Drop Out的决策树集成算法能够均衡不同顺序决策树的贡献程度,避免对早期决策树过于敏感而导致的过拟合情况。
+
七、改进后因子与策略效果
● 基本设定:
1)回测时间:2015年2月1日-2023年9月30日,以每月第一个交易日的收盘价进行月频调仓。
2)每个模型使用5个随机种子取均值。
3)假定手续费率为单边千二。
7.1 因子测试结果

● 针对沪深300:
两类模型均有优异的选股表现,进行行业市值中性化后,IC均值分别为8.08%和10.68%,两类模型进一步合成后IC均值提升至10.98%。多头年化超额收益率达到19.66%,多头超额最大回撤仅为6.40%,相较于单类模型有一定提升。
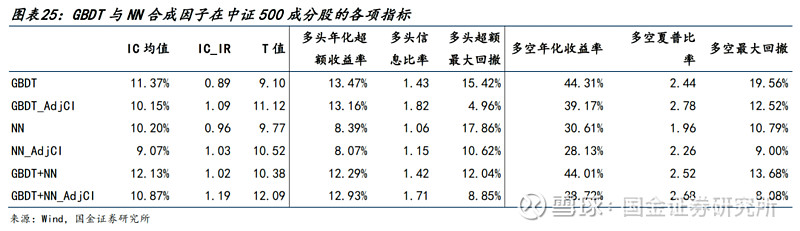
● 针对中证500:
两类模型合成后的因子IC均值为10.87%,多头年化超额收益率为12.93%,多头超额最大回撤为8.85%。相较于沪深300的收益水平和稳定性略有下降。
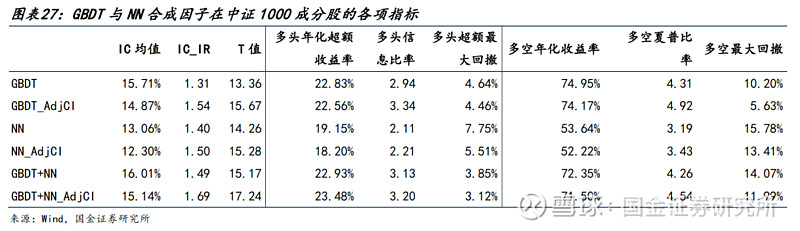
● 针对中证1000:
两类模型合成因子IC均值达到16.01%,行业市值中性化后依然有15.14%。而在多头端,年化超额收益率为22.93%,中性化后的因子收益进一步提升至23.48%,多头超额最大回撤也仅为3.12%。
7.2 基于GBDT+NN的指数增强策略
● 使用马科维茨的均值方差优化模型,对投资组合的年化跟踪误差在5%以内,并控制个股偏离程度以减少策略波动水平,最大化预期超额收益率。
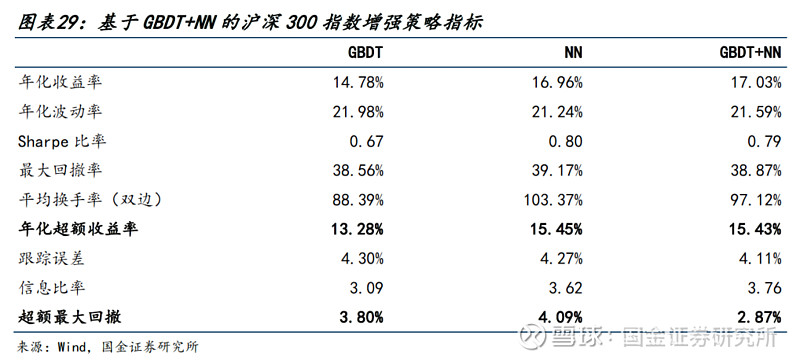
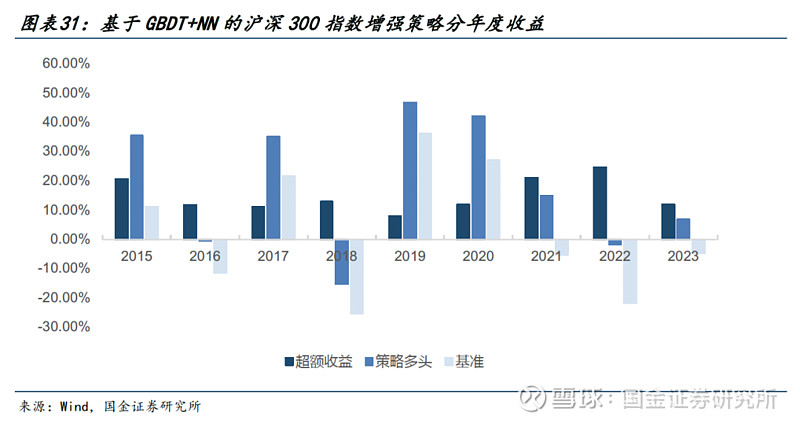
● 针对沪深300:
1)年化超额收益率达到15.43%,超额最大回撤仅为2.87%。
2)分年度来看,策略仅在2019年超额收益未达到10%,其余年份均有较高的超额收益水平。
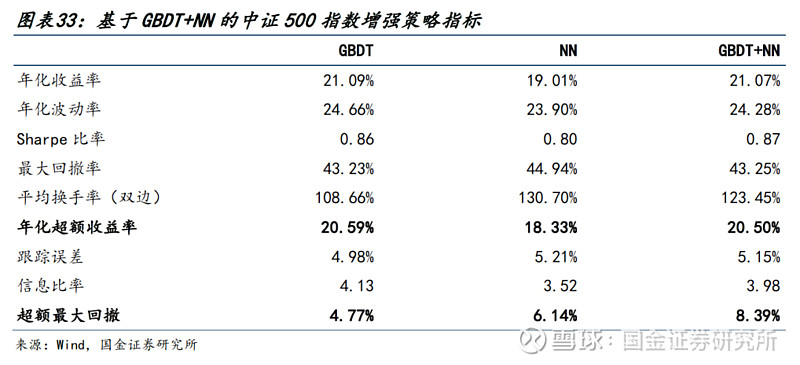
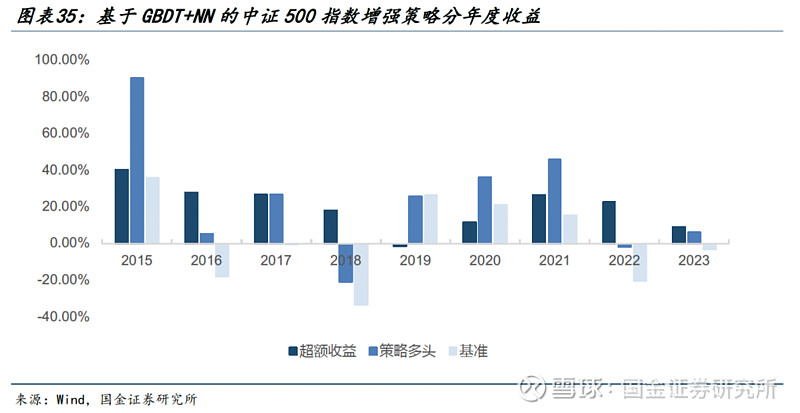
● 针对中证500:
1)策略的年化超额收益率达到20.50%,超额最大回撤为8.39%。
2)分年度来看,稳定性略差于沪深300,超额收益率在2019年较低,其余年份超额收益均在10%以上。
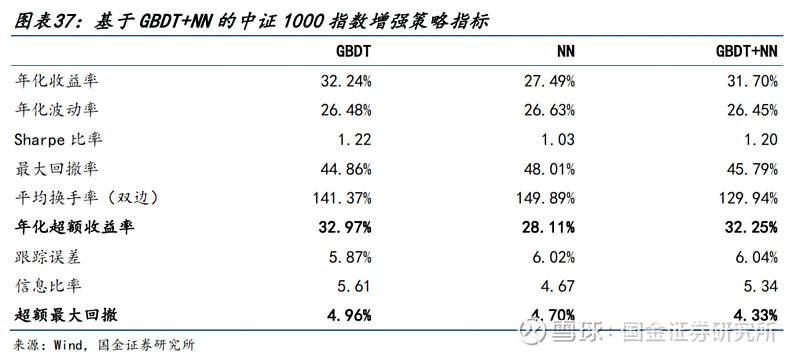
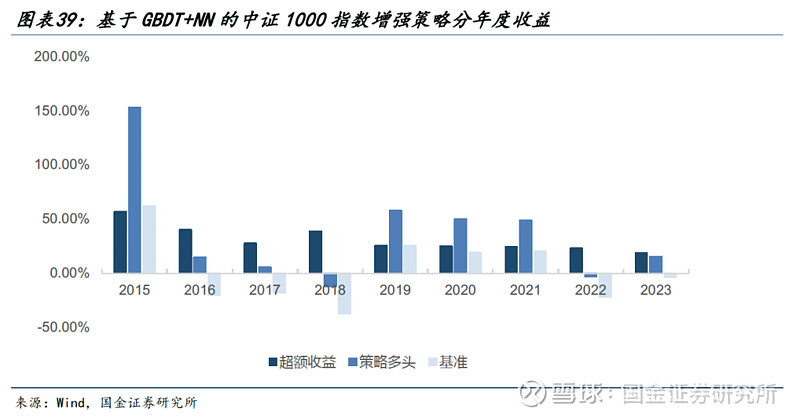
● 针对中证1000:
1)策略的年化超额收益率达到32.25%,超额最大回撤为4.33%。
2)分年度来看,策略在中证1000上表现最为稳定,每一年的超额收益均在20%以上。
风险提示:以上结果通过历史数据统计、建模和测算完成,在政策、市场环境发生变化时模型存在时效的风险;策略通过一定的假设通过历史数据回测得到,当交易成本提高或其他条件改变时,可能导致策略收益下降甚至出现亏损。
报告原文
点击阅读全文:《Alpha掘金系列之十:机器学习全流程重构——细节对比与测试》
Alpha掘金系列报告
《Alpha掘金系列之十一:基于BERT-TextCNN的中证1000舆情增强策略》
《Alpha掘金系列之十:机器学习全流程重构——细节对比与测试》
《Alpha掘金系列之九:基于多目标、多模型的机器学习指数增强策略》
《Alpha掘金系列之八:FinGPT对金融论坛数据情感的精准识别——沪深300另类舆情增强因子》
《Alpha掘金系列之七:ChatGLM医药行业舆情精选策略——大模型微调指南》
《Alpha掘金系列之六:弹性与投资者耐心——基于高频订单簿的的斜率凸性因子》
《Alpha掘金系列之五:如何利用ChatGPT挖掘高频选股因子?》
《Alpha掘金系列之四:基于逐笔成交数据的遗憾规避因子》
《Alpha掘金系列之三:高频非线性选股因子的线性化与失效因子的动态纠正》
《Alpha掘金系列之二:基于高频快照数据的量价背离因子》
《Alpha掘金系列:多维度卖方分析师预测能力评价——券商金股组合增强策略》
