
多因子选股模型是广泛应用的一种方法。采用一系列的因子作为选股标准,满足则买入,不满足则卖出。模型的优点是可以综合很多信息后给出一个选股结果。选取的因子不同以及如何综合各个因子得到最终判断的方法不同会产生不同的模型。一般来说,综合因子的方法有打分法和回归法两种,打分法较为常见。首先,我们对以下因子做出选择,因子越多越好:

列出前5只股:

计算不同因子的月回报:

计算因子有效性:

根据有效因子选股:

轮动选股:

策略思路来源于聚宽平台陈小米的量化选股——多因子模型。投资有风险,入市需谨慎!
代码:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import statsmodels.api as sm
import scipy.stats as scs
import matplotlib.pyplot as plt
# In[3]:
factors = ['B/M','EPS','PEG','ROE','ROA','GP/R','P/R','L/A','FAP','CMC','MC','CMC/C','TOE/MC','PB','NP/MC','TP/MC',
'TA/MC','OP/MC','CRF/MC','PS','OR/MC','RP/MC','TL/TA','TCA/TCL','PE','OR*ROA/NP','GPM','IRYOY','IRA','INPA',
'NPM','OPTTR','C','CC','PR','PRL']
#月初取出因子数值
def get_factors(fdate,factors):
stock_set = get_index_stocks('000001.XSHG',fdate)
q = query(
valuation.code,
balance.total_owner_equities/valuation.market_cap/100000000,
income.basic_eps,
valuation.pe_ratio,
income.net_profit/balance.total_owner_equities,
income.net_profit/balance.total_assets,
income.total_profit/income.operating_revenue,
income.net_profit/income.operating_revenue,
balance.total_liability/balance.total_assets,
balance.fixed_assets/balance.total_assets,
valuation.circulating_market_cap,
valuation.market_cap, # MC 总市值
valuation.circulating_market_cap/valuation.capitalization*10000, # CMC/C 流通市值(亿)/总股本(万) (收盘价)
balance.total_owner_equities/valuation.market_cap/100000000, # TOE/MC 每元所有者权益
valuation.pb_ratio, # PB 市净率
income.net_profit/valuation.market_cap/100000000, # NP/MC 每元所有者净利润
income.total_profit/valuation.market_cap/100000000, # TP/MC 每元利润总额
balance.total_assets/valuation.market_cap/100000000, # TA/MC 每元资产总额
income.operating_profit/valuation.market_cap/100000000, # OP/MC 每元营业利润
balance.capital_reserve_fund/valuation.market_cap/100000000, # CRF/MC 每元资本公积
valuation.ps_ratio, # PS 市销率
income.operating_revenue/valuation.market_cap/100000000, # OR/MC 每元营业收入
balance.retained_profit/valuation.market_cap/100000000, # RP/MC 每元未分配利润
balance.total_liability/balance.total_sheet_owner_equities,# TL/TA 资产负债率
balance.total_current_assets/balance.total_current_liability, # TCA/TCL 流动比率
valuation.pe_ratio, # PE 市盈率
income.operating_revenue*indicator.roa/income.net_profit, # OR*ROA/NP 总资产周转率
indicator.gross_profit_margin, # GPM 销售毛利率
indicator.inc_revenue_year_on_year, # IRYOY 营业收入同比增长率(%)
indicator.inc_revenue_annual, # IRA 营业收入环比增长率(%)
indicator.inc_net_profit_year_on_year, # INPYOY 净利润同比增长率(%)
indicator.inc_net_profit_annual, # INPA 净利润环比增长率(%)
indicator.net_profit_margin, # NPM 销售净利率(%)
indicator.operation_profit_to_total_revenue, # OPTTR 营业利润/营业总收入(%)
valuation.capitalization,# C 总股本
valuation.circulating_cap, # CC 流通股本(万股)
valuation.pcf_ratio, # PR 市现率
valuation.pe_ratio_lyr, # PRL 市盈率LYR
).filter(
valuation.code.in_(stock_set),
valuation.circulating_market_cap
)
fdf = get_fundamentals(q, date=fdate)
fdf.index = fdf['code']
fdf.columns = ['code'] + factors
return fdf.iloc[:,-36:]
fdf = get_factors('2017-01-01',factors)
fdf.head()
# In[3]:
#计算每月回报
def caculate_port_monthly_return(port,startdate,enddate,nextdate,CMC):
close1 = get_price(port, startdate, enddate, 'daily', ['close'])
close2 = get_price(port, enddate, nextdate, 'daily',['close'])
weighted_m_return = ((close2['close'].ix[0,:]/close1['close'].ix[0,:]-1)*CMC).sum()/(CMC.ix[port].sum())
return weighted_m_return
#计算基准回报
def caculate_benchmark_monthly_return(startdate,enddate,nextdate):
close1 = get_price(['000001.XSHG'],startdate,enddate,'daily',['close'])['close']
close2 = get_price(['000001.XSHG'],enddate, nextdate, 'daily',['close'])['close']
benchmark_return = (close2.ix[0,:]/close1.ix[0,:]-1).sum()
return benchmark_return
#因为研究模块取fundmental数据默认date为研究日期的前一天。所以要自备时间序列。按月取
year = ['2013','2014','2015']
month = ['01','02','03','04','05','06','07','08','09','10','11','12']
result = {}
for i in range(7*12):
startdate = year[i//12] + '-' + month[i%12] + '-01'
try:
enddate = year[(i+1)//12] + '-' + month[(i+1)%12] + '-01'
except IndexError:
enddate = '2016-01-01'
try:
nextdate = year[(i+2)//12] + '-' + month[(i+2)%12] + '-01'
except IndexError:
if enddate == '2016-01-01':
nextdate = '2016-02-01'
else:
nextdate = '2016-01-01'
print('time %s'%startdate)
fdf = get_factors(startdate,factors)# 因子列表
PRL = fdf['PRL']
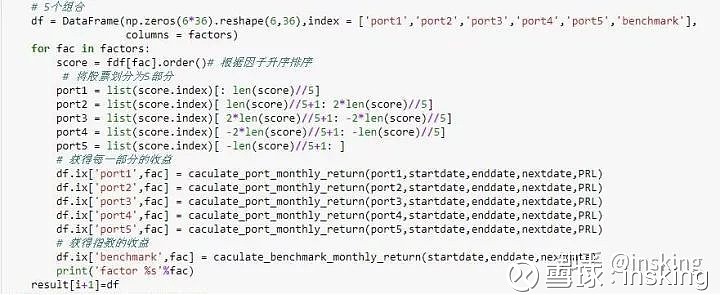
# 5个组合
df = DataFrame(np.zeros(6*36).reshape(6,36),index = ['port1','port2','port3','port4','port5','benchmark'],
columns = factors)
for fac in factors:
score = fdf[fac].order()# 根据因子升序排序
# 将股票划分为5部分
port1 = list(score.index)[: len(score)//5]
port2 = list(score.index)[ len(score)//5+1: 2*len(score)//5]
port3 = list(score.index)[ 2*len(score)//5+1: -2*len(score)//5]
port4 = list(score.index)[ -2*len(score)//5+1: -len(score)//5]
port5 = list(score.index)[ -len(score)//5+1: ]
# 获得每一部分的收益
df.ix['port1',fac] = caculate_port_monthly_return(port1,startdate,enddate,nextdate,PRL)
df.ix['port2',fac] = caculate_port_monthly_return(port2,startdate,enddate,nextdate,PRL)
df.ix['port3',fac] = caculate_port_monthly_return(port3,startdate,enddate,nextdate,PRL)
df.ix['port4',fac] = caculate_port_monthly_return(port4,startdate,enddate,nextdate,PRL)
df.ix['port5',fac] = caculate_port_monthly_return(port5,startdate,enddate,nextdate,PRL)
# 获得指数的收益
df.ix['benchmark',fac] = caculate_benchmark_monthly_return(startdate,enddate,nextdate)
print('factor %s'%fac)
result[i+1]=df
monthly_return = pd.Panel(result)
# In[6]:
total_return = {}
annual_return = {}
excess_return = {}
win_prob = {}
loss_prob = {}
effect_test = {}
MinCorr = 0.3
Minbottom = -0.05
Mintop = 0.05
for fac in factors:
effect_test[fac] = {}
monthly_return = pd.Panel(result)
monthly = monthly_return[:,:,fac]
total_return[fac] = (monthly+1).T.cumprod().iloc[-1,:]-1
annual_return[fac] = (total_return[fac]+1)**(1./6)-1
excess_return[fac] = annual_return[fac]- annual_return[fac][-1]
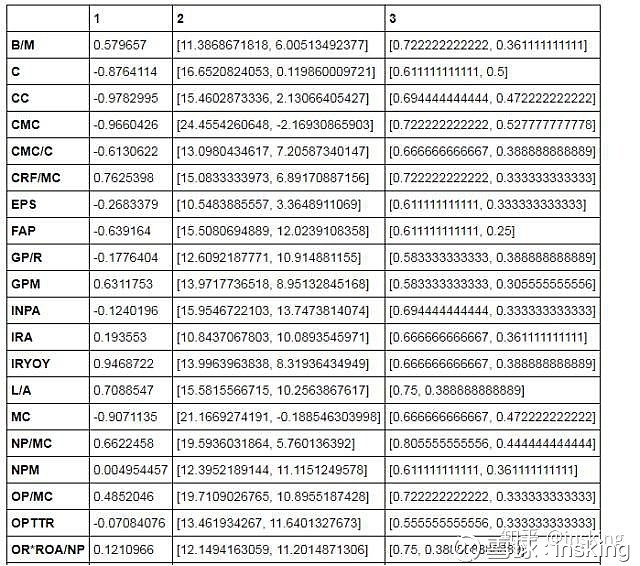
#判断因子有效性
#1.年化收益与组合序列的相关性 大于 阀值
effect_test[fac][1] = annual_return[fac][0:5].corr(Series([1,2,3,4,5],index = annual_return[fac][0:5].index))
#2.高收益组合跑赢概率
#因子小,收益小,port1是输家组合,port5是赢家组合
if total_return[fac][0] < total_return[fac][-2]:
loss_excess = monthly.iloc[0,:]-monthly.iloc[-1,:]
loss_prob[fac] = loss_excess[loss_excess<0].count()/float(len(loss_excess))
win_excess = monthly.iloc[-2,:]-monthly.iloc[-1,:]
win_prob[fac] = win_excess[win_excess>0].count()/float(len(win_excess))
effect_test[fac][3] = [win_prob[fac],loss_prob[fac]]
#超额收益
effect_test[fac][2] = [excess_return[fac][-2]*100,excess_return[fac][0]*100]
#因子小,收益大,port1是赢家组合,port5是输家组合
else:
loss_excess = monthly.iloc[-2,:]-monthly.iloc[-1,:]
loss_prob[fac] = loss_excess[loss_excess<0].count()/float(len(loss_excess))
win_excess = monthly.iloc[0,:]-monthly.iloc[-1,:]
win_prob[fac] = win_excess[win_excess>0].count()/float(len(win_excess))
effect_test[fac][3] = [win_prob[fac],loss_prob[fac]]
#超额收益
effect_test[fac][2] = [excess_return[fac][0]*100,excess_return[fac][-2]*100]
effect_test_df = DataFrame(effect_test)
effect_test_df_T = effect_test_df.T
# 条件1 相关性绝对值大于0.5,值越大越有效
#effect_test_df_T = effect_test_df_T[abs(effect_test_df_T['corr']) > 0.5]
# 条件3 胜率大于0.5,胜率越大效果越好
#effect_test_df_T = effect_test_df_T[effect_test_df_T['prob_win'] > 0.4]
DataFrame(effect_test_df_T)
# In[7]:
effective_factors = ['CMC','CMC/C','IRYOY','NP/MC','TP/MC']
#选股
def score_stock(fdate):
effective_factors = {'CMC/C':False,'IRYOY':True,'NP/MC':True,'TP/MC':True,'CMC':False}
fdf = get_factors(fdate)
score = {}
for fac,value in effective_factors.items():
score[fac] = fdf[fac].rank(ascending = value,method = 'first')
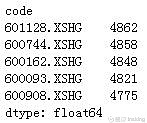
print(DataFrame(score).T.sum().order(ascending = False).head(5))
score_stock = list(DataFrame(score).T.sum().order(ascending = False).index)
return score_stock,fdf['CMC']
#获取有效因子数据
def get_factors(fdate):
factors = ['CMC/C','IRYOY','NP/MC','TP/MC','CMC']
stock_set = get_index_stocks('000001.XSHG',fdate)
q = query(
valuation.code,
valuation.circulating_market_cap/valuation.capitalization*10000,
indicator.inc_revenue_year_on_year,
income.net_profit/valuation.market_cap/100000000,
income.total_profit/valuation.market_cap/100000000,
valuation.circulating_market_cap,
).filter(
valuation.code.in_(stock_set)
)
fdf = get_fundamentals(q,date = fdate)
fdf.index = fdf['code']
fdf.columns = ['code'] + factors
return fdf.iloc[:,-5:]
[score_result,CMC] = score_stock('2017-01-01')
# In[22]:
year = ['2016','2017']
month = ['01','02','03','04','05','06','07','08','09','10','11','12']
factors = ['CMC/C','IRYOY','NP/MC','TP/MC','CMC']
result = {}
for i in range(7*12):
startdate = year[i//12] + '-' + month[i%12] + '-01'
try:
enddate = year[(i+1)//12] + '-' + month[(i+1)%12] + '-01'
except IndexError:
enddate = '2017-06-01'
try:
nextdate = year[(i+2)//12] + '-' + month[(i+2)%12] + '-01'
except IndexError:
if enddate == '2017-06-01':
nextdate = '2017-07-01'
else:
nextdate = '2017-06-01'
print('time %s'%startdate)
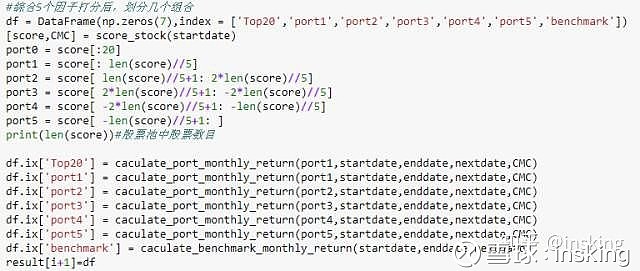
#综合5个因子打分后,划分几个组合
df = DataFrame(np.zeros(7),index = ['Top20','port1','port2','port3','port4','port5','benchmark'])
[score,CMC] = score_stock(startdate)
port0 = score[:20]
port1 = score[: len(score)//5]
port2 = score[ len(score)//5+1: 2*len(score)//5]
port3 = score[ 2*len(score)//5+1: -2*len(score)//5]
port4 = score[ -2*len(score)//5+1: -len(score)//5]
port5 = score[ -len(score)//5+1: ]
print(len(score))#股票池中股票数目
df.ix['Top20'] = caculate_port_monthly_return(port1,startdate,enddate,nextdate,CMC)
df.ix['port1'] = caculate_port_monthly_return(port1,startdate,enddate,nextdate,CMC)
df.ix['port2'] = caculate_port_monthly_return(port2,startdate,enddate,nextdate,CMC)
df.ix['port3'] = caculate_port_monthly_return(port3,startdate,enddate,nextdate,CMC)
df.ix['port4'] = caculate_port_monthly_return(port4,startdate,enddate,nextdate,CMC)
df.ix['port5'] = caculate_port_monthly_return(port5,startdate,enddate,nextdate,CMC)
df.ix['benchmark'] = caculate_benchmark_monthly_return(startdate,enddate,nextdate)
result[i+1]=df
backtest_results = pd.DataFrame(result)