永辉很重要的是一个坪效比数据,一直想分析,但是每次都被这复杂的PDF给拦住了,copy paste一多,就懒惰了,加上股价萎靡不振,着实不想分析这个破$永辉超市(SH601933)$ 。
希望大家鼓励我治疗好拖延症,行动起来,当然打赏给我点动力更好,哈哈。
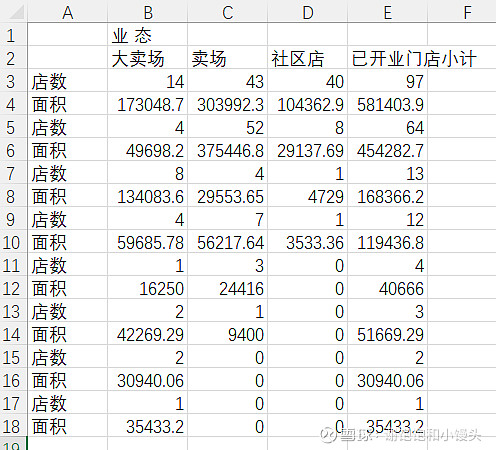
现在的想法是写一个Python脚本,来从年报中获取数据,然后自动填写到Excel中,再去用BI来分析。比如下面2011年年报第26页中就有签约门店的数据,可以读取出来。
读取的代码也不复杂,使用PyPDF2和pdfplumber两个组件来读,简单示例一下,这段代码就是把读取的第26页的内容打印出来。

打印出来的效果如下:

我自己设计的报表的格式如下,我的想法就是快速将上面表格的数据写入到下面的Excel中变成结构化的数据,以方便分析,我要开发的就是这样简单的分析工具。如果是美国证监会就简单了,用XRBL格式的XML或者API就可以很简单获取到数据。
但是我们国家金融市场的数据治理还不成熟,更谈不到向公众开放了。都是机构要花钱去买,我们普通老百姓还亏着钱,也买不起。
下面的表格中就包含了经营数据、面积、店铺数量等,这样等数据都准备好了,再设计几个坪效比的观察指标,这样才可能看出一些端倪出来。

使用extract_table()很快就可以看到上面的表格被格式化成表格数据如下:
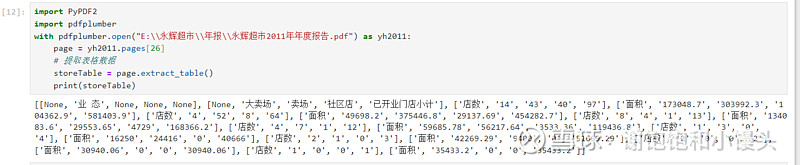
然后我就要给大模型给跪了,太强大了,程序员失业确实可能是早晚的事情。不过对我来说是好事,可以快速入门。Phython这个社区确实太强大了,有无数的文章,把这些训练数据喂给大模型,才有了大模型这么强大的智能,相互成就。

————————————————4月16日下午更新—————————————
进展:
1、已经可以从永辉2011年年报26页读取门店开办的数据。
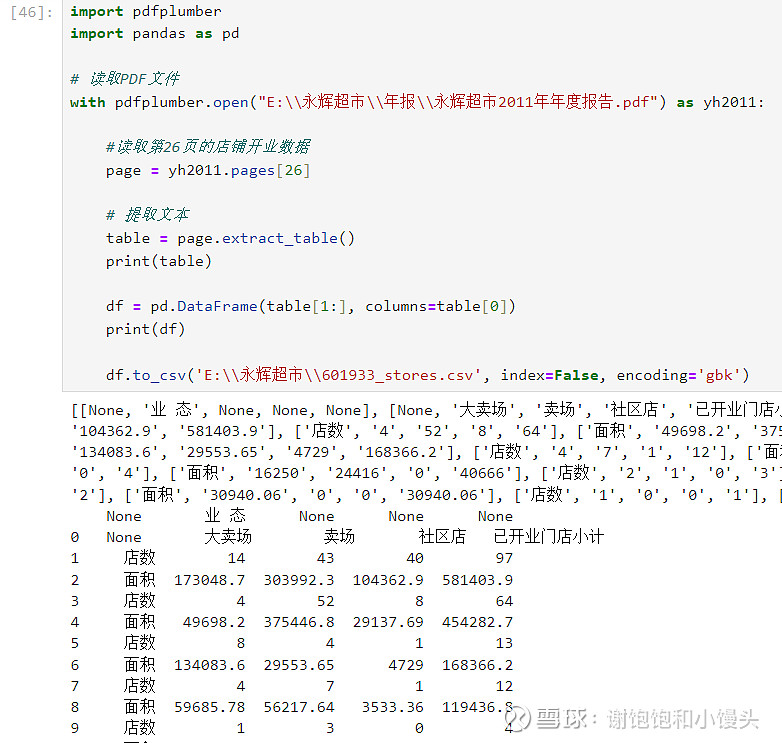
2、已经可以把数据读取出来写入到一个csv文件中,这样就不用自己辛苦去拷贝了。601933_stores.csv是程序自动生成的。

3、这是生成的csv文件中的数据。由于年报中26和27页是完整的开办数据,还需要继续研究:
(1)如何将连个pdf中的表合并成一张表;
(2)pdfplumber是根据框线来读取PDF中数据的,坑爹的永辉年报左右缺少了两根竖线,所以开业区域数据就读取不出来,还需要手工补填一下。