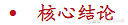
基于成本、能耗、可靠性和时延、隐私、个性化服务等考虑,端云混合的AI才是AI的未来,高通认为终端AI 能力是赋能混合AI并让生成式AI实现全球规模化扩展的关键。
百亿参数开源MoE大模型Mixtral 8x7B再掀热潮,性能超LLaMA2-70B,对标GPT-3.5。MoE(混合专家模型)通过将任务分配给对应的一组专家模型来提高模型的性能和效率。Mixtral 8x7B的专家数量为8个,总参数量为470亿,但在推理过程中仅调用两个专家即只调用130亿参数。
我们认为MoE或为现阶段大模型平衡成本、延迟以及性能的最优选择,叠加开源模型本身高灵活性、安全性和高性价比特点,Mistral AI的开源MoE轻量化模型可能是未来最适合部署于终端的模型。目前,高通、联发科、英特尔、AMD等龙头芯片厂商都推出了终端AI芯片,能跑十亿甚至百亿量级大模型。后续类Mixtral 8x7B的SMoE模型在高性能基础上继续压缩的话,很大几率可以装进终端设备实现本地运行。SMoE轻量模型大幅降低了训练的门槛和成本,且由于在推理时只激活少部分参数,保持较高性能的同时能适应不同的计算环境,包括计算能力有限的终端,降低推理成本且将催生更多大模型相关应用。
2024年有望成为终端智能元年,看好拥有终端资源、深耕场景、掌握行业knowhow、积累了海量数据的B端和C端公司。1)未来每台终端都将是AI终端,包括AI PC、AI手机、AI MR等,这将带来全新的用户体验。2)AI PC有望成为“AI+”终端中最先爆发的。英特尔预计全球今年将交付4000万台AI PC,明年将交付6000 万台,预估2025年底AI PC在全球PC市场中占比将超过20%;微软AI PC预计于今年亮相。3)随着大模型逐步发展,尤其是多模态能力增强,更广泛的AIoT设备也迎来了更新换代的重要机遇。3)B端私有化部署也是AI应用的重要方向,关注边缘侧AI。4)鸿蒙:提供顶级流畅连接体验,大模型有望赋能奔赴万物智联下一站。
人形机器人是大模型应用的重要硬件载体,也是终端智能发展的核心方向。1)人形机器人是目前具身智能最好的形态,因为它们有着与人相似的外观设计,能更好地适应周围的环境和基础设施。2)端云混合的“大脑”让机器人既能处理复杂和高强度的计算任务,又能实时进行信息处理和分析。
建议关注:1)算力基础:中科曙光、神州数码、浪潮信息、高新发展;2)AI PC:华勤技术、龙旗科技、联想集团、星环科技-U、海光信息;3)终端鸿蒙:润和软件、九联科技、东方中科、软通动力、中国软件国际、拓维信息、初灵信息;4)拥有丰富的终端资源:海康威视、大华股份、科大讯飞、萤石网络、漫步者;5)B端应用:北路智控、智洋创新、云涌科技、商汤-W、云从科技-UW。风险提示:AIGC技术突破不及预期、终端智能需求不及预期、宏观经济增长不及预期、国际环境变化;

基于成本、能耗、可靠性和时延、隐私和安全、个性化服务等考虑,端云融合的AI才是AI的未来,高通认为终端侧AI 能力是赋能混合AI并让生成式AI实现全球规模化扩展的关键。高通曾发布白皮书称混合AI 是AI的未来。只有云和终端都能承担AI处理的任务,才能实现AI 的规模化扩展并发挥其最大潜能——正如传统计算从大型主机和瘦客户端演变为当前云端和终端相结合的模式。混合AI指终端和云协同,根据不同场景和需求分配AI计算的工作负载,以提供更好的体验并高效利用资源。在一些场景下,AI处理将以终端为中心,必要时向云端分求助;而在以云为中心的场景下,终端将根据自身能力,在可能的情况下从云端分担部分AI 工作负载


百亿参数开源MoE大模型Mixtral 8x7B再掀热潮,性能超LLaMA2-70B,对标GPT-3.5。Mixtral 8x7B每个token可以访问470亿参数,但推理过程中仅使用130亿参数,低成本优势显著。我们认为MoE或为现阶段大模型平衡成本、延迟以及性能的最优选择,叠加开源模型本身高灵活性、安全性和高性价比特点,MistralAI的开源MoE轻量化模型可能是未来最适合部署于终端的模型。
2.1关注MoE——LLM头部玩家们正在实践的重要技术路线
MoE(Mixture of Experts,混合专家模型)是一种创新的深度学习架构,旨在通过将任务分配给对应一组专家模型来提高模型的性能和效率。MoE架构最早由1991 年的论文《Adaptive Mixture of Local Experts》提出,其核心思想在于利用多个小型的专家网络,每个网络专注于处理输入数据的不同部分或特征;然后通过一个“门控”机制来被选择性地激活,该机制基于输入数据的特性来决定哪些专家网络应该参与到当前任务的预测中
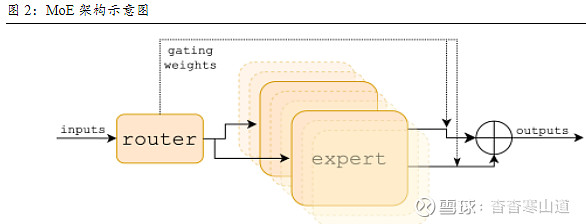
MoE基于Transformer架构,主要由稀疏MoE层和门控网络这两个关键部分组成。1)稀疏MoE层:取代传统transformer 模型中的前馈网络层(FFN),MoE层中每个专家本身也是一个独立的神经网络;2)门控网络或路由:决定输入的token激活哪些专家。例如在下图中,“More”被发送到第二个专家,而“Parameters”被发送到第一个专家,在某些情况下单个token甚至可能被发送至多位专家。最后,所有专家的输出会被聚合(aggregated)起来,形成最终的模型输出
GPT-4或已采用MoE架构。根据semianalysis文章,GPT-4 参数规模是GPT-3 的10 倍以上。GPT-3 的参数量约1750 亿,semianalysis推测GPT-4约1.8万亿个参数,这些参数分布在120 个transformer 层上。GPT-4中有16 个MLP.2 (Multi-Layer Perceptron,多层感知机)类型的专家,每个专家网络的参数大约为1110 亿个,每次前向传递中会调用其中的两个专家模型;此外,还有550 亿个attention共享参数。这样推理时,每生成一个token仅需约2800 亿个参数和560 TFLOP,而相比之下,如果使用稠密模型,每次生成一个token需要约18000 亿个参数和3700 TFLOP。
谷歌Gemini 1.5采用MoE架构,可一次性、高效处理大量信息。2024年2月15日,谷歌发布Gemini 1.5,宣布将上下文窗口长度扩展到100万个tokens,也就是说Gemini 1.5可以一次性处理1小时的视频、11小时的音频、超过3万行代码或超过70万字的代码库。谷歌甚至在研究中成功测试了多达1000万个tokens

2.2Mixtral 8x7B:低成本SMoE小模型+开源,更务实的GenAI商业化路线
Mistral AI横空出世打造超强轻量化模型Mistral 7B。Mistral AI是一家法国AI初创公司,也是目前欧洲最强的LLM公司之一,团队成员中7人来自Facebook(4位参与Llama 研发),3人来自Hugging Face,2人来Deepmind。2023年9月27日,Mistral AI发布轻量化大模型Mistral 7B。根据技术论文《Mistral 7B》,Mistral-7B在每个基准测试中,都优于Llama2-13B,并且在代码、数学和推理方面优于LLaMA1-34B。根据Percy Liang 团队HELM 模型测评报告,Mistral 7B 的表现甚至超越了Cohere-52B 的模型。
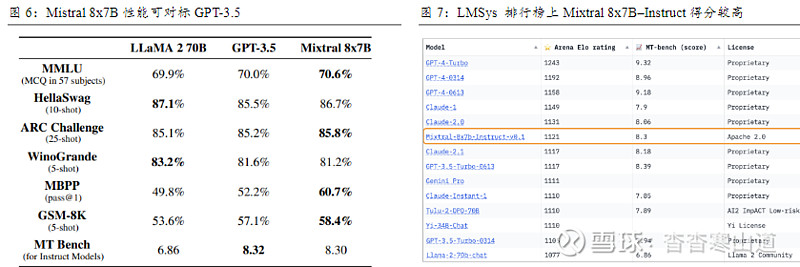
开源SMoE大模型Mixtral 8x7B再掀热潮,性能超越LLaMA2-70B。2023年12月8日,Mistral AI在X上发布了一条磁力链接,直接开源了自己最新的,基于Mistral 7B打造的SMoE(Sparse Mixture of Experts,稀疏混合专家模型,相对MoE引入了稀疏性的概念,以提高模型的稀疏性和计算效率)轻量大模型Mixtral 8x7B;2024年1月8日,Mistral AI在Arxiv公开Mixtral 8x7B的论文《Mixture of Experts》。Mixtral 8x7B的研发人员使用自己的流程全方位评估了模型性能,结论是:Mixtral 8x7B在大多数指标测试中的表现均优于LLaMA2-70B,尤其在代码和数学基准测试中优势明显;
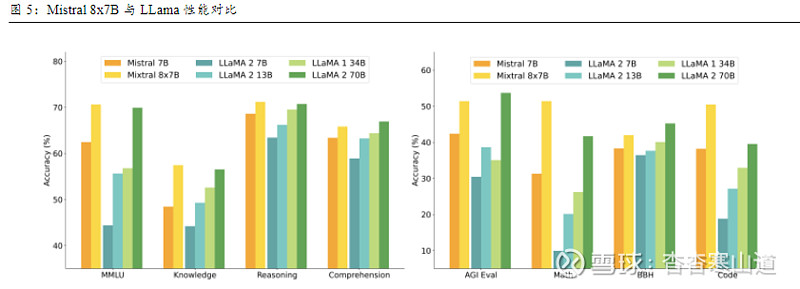
Mistral 8x7B比肩GPT-3.5,Mistral AI成为开源LLM新领军。与semianalysis文章中的GPT-4对比,Mistral 8x7B架构类似,有和GPT-4相同的3.2万上下文窗口长度,但在规模小很多:1)专家数量为8个;2)每个专家拥有70亿左右参数;3)每个token可以访问470亿参数,但在推理过程中仅调用两个专家,即只使用130亿参数。在《Mixture of Experts》论文中,研究者也展示了Mixtral 8x7B和GPT-3.5、LLama2-70B的性能评测结果,综合来看,Mixtral 8x7B可以对标甚至超越其它两个模型。研究者使用优化后的Mixtral–Instruct进行跑分测试,在MT-Bench评估中得分8.30,在Arena Elorating中得分1121,超过了Claude-2.1、GPT-3.5-Turbo所有版本、Gemini Pro和Llama-2-70b-chat
Mistral 7B已做了针对性优化以降低推理成本和延迟。根据论文《Mistral 7B》,Mistral 7B使用了GOA(grouped-query attention,分组查询注意力)以加速推理,同时采用SWA(Sliding Window Attention,滑动窗口注意力机制)以降低成本。Hugging Face CSO 在X上以Summarize.tech 为例,提及在实际应用中,使用Mistral 7B 替代GPT-3.5 可节省了一大半推理成本。
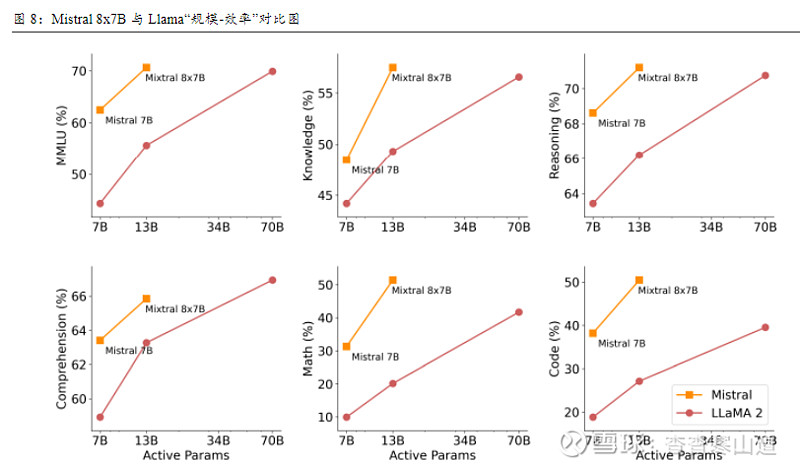
Mistral 8x7B增大总参数以提高性能,但推理时只激活小部分参数,有效提高了效率、降低了成本。下图横轴为推理时激活的参数量,这与推理时的计算成本强相关,竖轴表示推理效率。可以看出,对比LLama,Mistral 8x7B由于推理时调用的参数较少,故成本低;且由于MoE模型中的专家是并行工作的,并且在任何给定时间只激活一部分专家,因此它能实现更快的推理速度,即能以更低的计算成本下实现更高推理效率
2.3端侧AI芯片已能支持百亿参数模型本地运行,看好轻量SMoE模型终端部署前景
我们认为,低成本、高灵活性及安全性的开源轻量化SMoE模型较为适合在终端部署。
1)训练端,Mixtral 8x7B这类高性能开源小模型大幅降低了模型训练的门槛,也降低了软硬件成本。硬件方面,这类模型总体规模相对小很多,因此对AI芯片数量需求以及单卡性能要求都有所降低,这意味着即使在没有大量高端硬件资源的情况下,企业也能够进行有效的模型训练和优化。在软件方面,开源特性让企业可以基于自身场景及需求灵活调试模型,且成本相对于闭源模型更低。
2)推理端,轻量MoE模型推理时只激活少部分参数,也就意味着大模型可以在保持较高性能的同时适应不同的计算环境,包括计算能力有限的终端设备。同时由于模型本地部署于终端,推理计算时更多依赖终端设备的芯片,即计算成本转移到了端侧,总推理成本会大幅降低,这将催生许多大模型相关的应用。
目前,高通、联发科、英特尔、AMD等龙头芯片厂都推出了终端AI芯片,能跑十亿级甚至百亿量级大模型。后续类Mixtral 8x7B的SMoE模型在高性能基础上继续压缩的话,很大几率可以装进终端设备实现本地运行。高通从手机、PC、耳机、XR、眼镜、汽车等多方面布局端侧AI,接连推出大算力端侧芯片;联发科推出可本地运行百亿参数大模型的手机芯片;英特尔推出内置NPU的酷睿Ultra处理器且宣布启动“AI PC加速计划;
2.3.1高通:端侧AI芯片领导者,提供软硬件全栈优化
高通通过持续优化硬件性能和AI软件栈来加速终端侧AI。硬件上,高通AI引擎采用异构计算架构,包括Hexagon处理器、Adreno GPU 和高通Kryo CPU,全部面向在终端侧快速高效地运行AI应用而打造。其中,Hexagon 处理器不断演进,已经成为了高通AI 引擎最关键的部分,能够应对不断变化的AI 需求。
Hexagon处理器的迭代更新为高通端侧芯片AI性能跃升的关键。
2015年,高通将AI技术集成到Hexagon处理器中;2017 年,骁龙845芯片中引入Hexagon 685 DSP,通过迭代、优化、更新,现在骁龙X Elite 和8 Gen 3 芯片中的Hexagon NPU可以提供45TOPS的AI算力。Hexagon NPU与之前的DSP相比,在架构、计算单元上都进行了重新设计,升级了全新的微架构,集成了硬件加速单元和微型区块推理单元,以及全新的张量单元、标量单元、矢量单元,并且所有单元共享2倍带宽的大容量共享内存,内部运行频率更高,内部缓存空间更大,实现了显著的运行速度的提升。Hexagon处理器在6年时间里AI性能提高了100倍,计算能力呈陡峭上升趋势

软件上,在算法和模型开发方面,高通进行了神经网络架构开发和调整工作,以在不牺牲准确度的前提下提高效率;在软件和模型效率方面,高通打造AI软件栈来帮助开发者实现一次开发,即可跨高通所有硬件运行AI负载,并且采用全面而有针对性的策略,包括量化、压缩、条件计算、神经网络架构搜索(NAS)和编译等技术,在不牺牲太多精度的前提下缩减AI 模型,使其高效运行

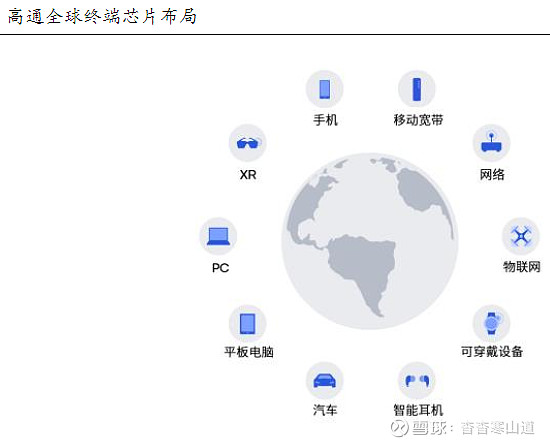
高通终端芯片布局包括手机、汽车、XR、PC 和物联网等,种类和数量都为行业领先,搭载骁龙平台的终端能够推动混合AI 扩展至跨不同细分领域和层级的数十亿产品。手机领域,高通目前已出货的且具备AI能力的处理器达到十亿量级。汽车领域,高通提供领先的座舱和车载信息娱乐解决方案,合作伙伴包括诸多头部车厂。物联网领域,高通是物联网终端芯片的主要提供商之一,高通物联网芯片的AI处理能力支持终端设备以高效可行的方式进行端侧数据分析,推动了跨多个细分领域的创新和转型,包括机器人、智能摄像头、零售和城市基础设施。XR领域,Meta等公司的VR 头显和AR 眼镜等XR 终端集成了高通终端侧AI和Snapdragon Spaces技术
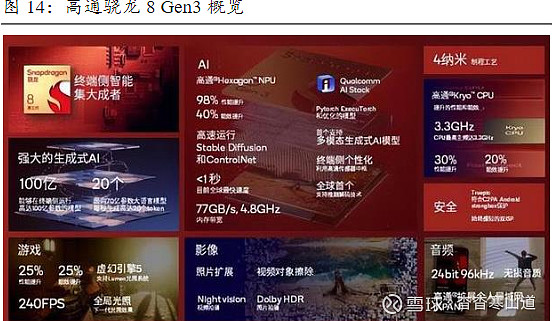
2023年10月,高通发布了两款支持端侧运行百亿大模型的芯片——面向PC的骁龙X Elite以及面向手机的骁龙8 Gen3。1)高通骁龙X Elite:支持在终端本地运行130亿参数大模型,能以30 Tokens/s的速度在终端运行70亿参数的Llama-2模型,实现快速、准确的响应。AI方面整合CPU、GPU、NPU等模块,总算力最高75TOPS,其中HexagonNPU峰值算力为45TOPS。2)高通骁龙8 Gen3:用Hexagon NPU代替了原有的Hexagon DSP,总算力73TOPS,支持在终端运行100亿大模型。运行70亿参数大模型时,每秒可生成20个token;运行Stable Diffusion时,创作图像只需0.6秒

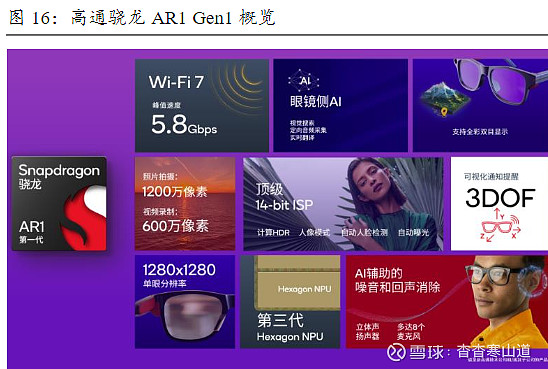
2023年9月,高通宣布推出两款全新空间计算平台——第二代骁龙XR2和第一代骁龙AR1,分别用于MR和VR、智能眼镜设备。这两款产品是与Meta密切合作而开发的:Meta Quest 3搭载了骁龙XR2 Gen2平台,Ray-Ban Meta智能眼镜系列搭载骁龙AR1 Gen1平台。1)与XR2 Gen1对比,骁龙XR2 Gen2的GPU性能提升2.5倍,AI性能提升8倍;2)骁龙AR1 Gen1的终端侧AI能提供音质增强、视觉搜索和实时翻译等个人助手体验

2024年1月,高通推出第二代骁龙XR2加强版本第二代骁龙XR2+平台。相对于XR2 Gen2,XR2+ Gen2的GPU频率提升15%,CPU频率提升20% ,支持更逼真、具备更丰富细节的全新水平MR和VR体验。搭载第二代骁龙XR2+的设备能够支持12路及以上并行摄像头和强大的终端AI,轻松追踪用户的运动轨迹和周围环境,从而实现融合物理和数字空间的便捷导航和出色XR体验。三星和谷歌的XR设备采用XR2+ Gen2平台。
2023年10月,高通推出面向耳塞、耳机和音箱设计的第一代高通S7和S7 Pro音频平台。对比此前的S5系列,带来了3倍的DSP性能、6倍的计算性能、100倍的端侧AI性能进步,以及3倍的集成内存带宽。AI性能大幅提升有利于提高耳机降噪性能;同时,芯片算力提高将为未来无线耳机实现更多功能奠定基础,比如支撑耳塞内置传感器以收集整理数据等

2.3.2全球芯片巨头:密集发布新品,抢抓终端侧AI机遇
联发科天玑9300可本地运行70亿参数大模型,还和vivo一起将规模提高到130亿参数,甚至在基于24GB内存的智能手机上,已成功运行最高330亿参数的AI大模型。2023年11月,联发科发布天玑9300 旗舰5G 生成式AI 移动芯片。在整体架构上,天玑9300采用全大核CPU架构,大幅减少任务的总消耗时间,提升应用执行效率、减少卡顿,同时也能降低功耗,为AI算力提升打下底层计算基础。在AI能力上,天玑9300集成性能显著提升的Media Tek第七代AI处理器APU 790,内置硬件级的生成式AI 引擎,整数运算和浮点运算性能均是上一代的2倍,同时功耗降低45%,是业界首款搭载硬件生成式AI 引擎的智能手机芯片,可实现更加高速且安全的终端AI计算。同时,天玑9300深度适配Transformer模型,在核心的Softmax+LayerNorm算子上,处理速度较上代提升8倍;

AMD推出内置Ryzen AI引擎的新一代移动处理器。2023年初,AMD推出了首款内置Ryzen AI引擎的锐龙7040系列处理器;2023年12月,AMD发布8040系列,升级了XDNANPU,使其AI算力从10TOPS升至16TOPS,提升幅度达到了60%,同时整体算力从33TOPS增加到39TOPS。根据AMD给出的数据,相比于前代7040系列,锐龙8040系列在Llama2和视觉模型方面,性能提升多达40%

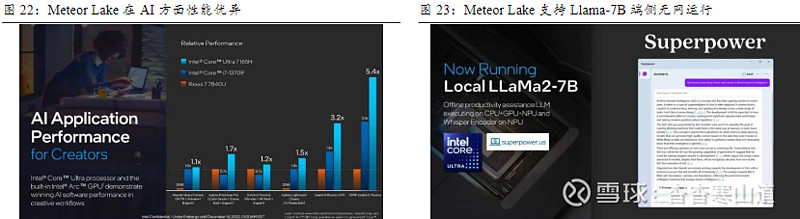
英特尔第一代酷睿Ultra支持端侧无网运行Llama2-7B。酷睿Ultra处理器(代号为Meteor Lake)是英特尔首款搭载NPU的处理器,其搭载的GPU、NPU、CPU都可以承载AI算力。阿里通义千问大模型已成功适配英特尔酷睿Ultra平台,未来可在PC等端侧部署

随着轻量模型性能愈加强大、端侧芯片算力提升,大模型本地部署于终端为大势所趋。我们认为,2024年将成为AI终端发展元年。AI赋能有望带来PC、手机、手表等智能可穿戴设备、平板、XR等各类数码产品的换机热潮,而更广泛AIoT智能也有望在大模型加持下迎来全面升级。
3.1各类“AI+”终端产品陆续发布,新周期大幕拉开
未来每一个终端将是AI终端,每一个PC、手机、MR、手表都将是AI PC、AI 手机、AI MR、AI手表。1)英特尔预估2024年全球将交付4000万台AI PC,明年将交付6000 万台,并计划到2025年底,英特尔为超过1亿台AI PC 供应处理器,而彼时AI PC在全球PC市场中的占比将超过20%。2)据Digitimes,微软AI PC将于今年首次亮相。微软将在2024年中旬首先推出以AI PC为主的Windows 11更新版,还将与高通合作将Windows on ARM和英特尔的x86系统进行整合,这一全新版本预计将在2024年台北国际电脑展上正式亮相。
英特尔启动“AI PC加速计划”,拉动PC进入新一轮换机周期。英特尔认为AI将成为PC市场转折点,并在2023年10月“英特尔on 技术创新大会”期间宣布启动AI PC加速计划——将在2025年前为超过1亿台PC带来AI特性。英特尔将充分利用英特尔在AI 工具链、协作共创、硬件、技术经验等资源以最大化利用AI,通过与超100 家独立软件供应商合作伙伴的深度合作,集合300余项AI加速功能,在音频效果、内容创建、游戏、安全、直播、视频协作等方面继续强化PC 体验

智能手机市场低迷,AI或为破局关键,国内外厂商抢滩大模型手机。消费者换机周期延长,智能手机市场急需颠覆性突破,AI带来想象空间。Siri引领了手机“智能语音助手”浪潮,虽然普及率高,但因为语音识别准确率较低以及实现场景较少,该类助手使用率较低。现在,大模型赋能的“智能助手”性能更为强大且支持多模态输出,由于天然接入了用户的私人数据库,它可以学习用户习惯以提供个性化输出或辅助,还能不断优化自身,同时还可以调用其他App,进而在更好识别用户意图的基础上实现功能多元化。2023年10月,谷歌发布可搭载谷歌AI模型的手机Pixel 8 Pro,采用自研Tensor G3芯片。2023年11月,vivo发布X100系列,支持本地运行70亿参数端侧大模型,曾跑通端侧130亿参数大模型。2024年1月,OPPO发布Find X7系列,宣布70亿参数的AI大模型在手机端落地;荣耀发布Magic6系列,首发搭载荣耀自研70亿参数端侧平台级AI大模型“魔法大模型”。
3.2AI PC有望成为“AI+”终端中最先爆发的
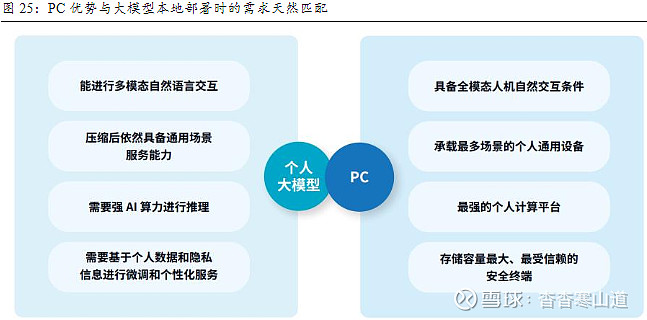
PC相对于其它终端,有最多样化交互方式、能承载最多的场景,同时存储容量较大且较为安全,和大模型本地部署需求更为适配。根据IDC与联想联合发布的白皮书《AI PC 产业(中国)白皮书》,PC具有以下四点优势从而使其与大模型更为匹配:1)PC作为终端设备,拥有全模态的交互方式,包括触控、语音、手势控制和专业的键鼠、数字笔交互等,在人机交互方面有天然优势;2)既能承载生活娱乐场景,也能够承载工作、学习等场景,为创新的AI应用提供了更多可能性;3)PC通常拥有大容量的本地安全存储,非常适合大模型本地部署以及隐私保护;
最重要的是PC通用计算能力较强,且能搭载较大体积的芯片,能实现强算力与便携性的平衡,是大模型实时推理和高性能计算的更为理想的平台。手机、平板电脑和智能穿戴设备便携性强,但由于体积不够大,很多时候无法搭载体积偏大的算力芯片。而AI PC的异构算力(CPU +GPU+NPU)协同运用,为PC 提供了相对来说更为强劲的并行计算能力,且随着终端AI芯片计算能力和能效的提升,算法和存储方案的优化,PC有望实现更大量级模型的本地部署
近年来PC全球出货量每年都有2亿台以上,所以当大模型与PC结合后,能触及的用户群体将非常庞大。同时,PC拥有大量的用户基础,这意味着一旦AI技术在PC上得到了有效的集成和应用,其影响力和覆盖范围将会很广,AI PC将会迅速普及。我们认为AIPC有望成为“AI+”终端中最先爆发的,尔后随着技术进步和产业发展,手机、音箱、MR人形机器人等等所有终端设备都将AI化;
3.3大模型有望驱动AIoT硬件升级,关注深耕场景、具有终端资源的公司
过往讨论“AI+终端”,更多集中在消费电子类数码产品,但随着大模型逐步发展,尤其是多模态能力增强,更广泛的AIoT设备也迎来了更新换代的重要机遇。大模型只有与各类AIoT设备深度结合才能真正从数字世界走向物理世界,同样AIoT设备只有与大模型深度结合才能从单纯的数据收集传输工具变为可以决策分析的智能化产品。
例如安防领域,传统的监控设备主要依赖于人力进行监控和分析,效率低下且容易出错。然而,当大模型被应用于安防领域的摄像头等传感器设备时,大模型可以实时分析摄像头的视频流,自动检测异常行为和事件,如入侵者、火灾等,并及时发出警报,不仅可以大大提高监控的效率和准确性,而且能减轻安保人员的工作负担。此外,大模型还可以帮助AIoT设备更好地理解和适应环境的变化。而由于用户数据的私密性要求、个性化体验要求以及出于成本考虑,大模型本地部署才是更好的选择。
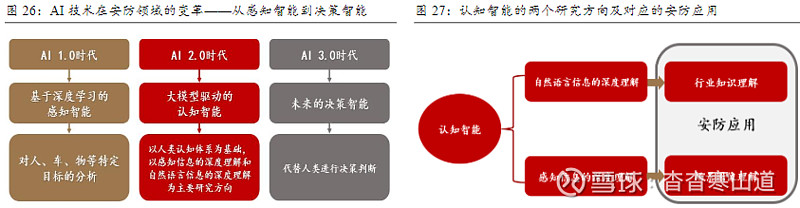
AI在安防领域的应用有三个阶段,大模型技术主导下的AI 2.0时代将成为分界线。AI 1.0时代,主要聚焦于感知智能,通过深度学习技术赋予机器类似人类的视觉、听觉和触觉,对特定目标进行分析;AI 2.0时代,则标志着认知智能的崛起,大模型成为主导,推动了机器的学习、思考和推理能力的提升;未来AI 3.0时代,机器将拥有真正的“人工大脑”,能够代替人类进行决策判断;
Transformer大模型是预训练模型,可以理解语义信息且具有很强的通用性,即使没有事先掌握所有的复杂视觉场景也能够理解和执行更广泛的下游任务。根据海康威视2023年三季报业绩会,在容易发生野泳溺水但不能常年派人值守的地方,用一台具备识别算法的海康威视设备进行监控,并搭配报警系统,结合现场的语音提示,能阻止大量危险行为的发生。此外,在工厂的螺丝安装过程中,视觉大模型可以在大量不同产品的场景中识别到不同的螺丝孔位并提示工人,有效避免螺丝漏打的问题,提高了生产质量。
爱芯智元认为,端侧部署大模型,有助于解决长尾场景下AI智能应用投入太高的问题。爱芯智元是一家AI视觉感知芯片研发及基础算力平台公司,其在需求沟通过程中发现,目前凡是需要用摄像头去捕捉画面的应用场景,都开始对大模型产生比较迫切的需求。比如做河道垃圾监测,以前的方式是采集数据、数据标注模型训练,新垃圾出现时模型可能识别不出来了,而重新训练又耗费时间和成本,而大模型能识别从未见过的新垃圾。但如果将数据传输回云端,会产生较高成本且增加云基础设施的压力。
所以,不仅要关注AIPC等消费电子类产业变革,也要关注物联网智能终端在大模型加持下的升级迭代机遇,我们看好拥有终端资源、深耕场景、掌握行业knowhow、积累了海量数据的B端公司。
3.4私有化部署的B端场景也是AI应用的重要方向,关注边缘侧AI
出于安全可控考虑,国央企通常都有私有化部署AI的需求。国央企是国家重要的经济支柱和产业龙头,掌控着国家关键资源及相关产业链,且较大的业务范围和业务体量有助于其实现规模效应,降低运营成本以及提高盈利能力,实现较好的经济效益,所以国央企通常具有较为丰富的资金储备以及较强的支付能力。而国央企在考虑AI部署时,会特别关注数据安全和合规性问题,私有化部署不仅能满足安全要求,还可以提供更大的灵活性和可控性,使得企业可以根据自身独特的业务需求来自定义AI系统的功能和配置。
政策驱动下,央企将发力AI赋能原有业务。在央企人工智能专题推进会上,国资委要求央企把加快发展新一代AI摆在更加突出的位置,着力打造AI产业集群,带头抢抓发力AI赋能传统产业,开展AI+专项行动,构建优质数据集,打造从基础设施、算法工具、智能平台到解决方案的大模型赋能产业生态。
我们认为,私有化部署的B端场景是AI应用的重要方向。从行业分布来看,国央企数量较多的主要有金融、电力、煤炭矿冶、运输物流、钢铁机械等为行业,关注面向这些重点行业,且能对大量终端或边缘侧设备进行连接管理的计算机公司;
3.5鸿蒙:提供顶级的流畅连接体验,大模型有望赋能奔赴万物智联下一站
鸿蒙OS是一款面向万物互联时代的、全新的分布式操作系统,具备分布架构、天生流畅、内核安全、生态共享四大特征,打破设备“孤岛”。2019年8月,华为在HDC大会上正式发布鸿蒙操作系统。鸿蒙OS的设计初衷是为满足全场景智慧体验的高标准的连接要求,为此华为提出了4大特性的系统解决方案:1)将分布式架构首次用于终端OS,实现跨终端无缝协同体验;2)确定时延引擎和高性能IPC 技术,以实现系统天生流畅;3)基于微内核架构重塑终端设备可信安全;4)通过统一IDE支撑一次开发、多端部署,实现跨终端生态共享“
1+8+N”全场景战略布局明确,为消费者串联起过往割裂的终端体验,实现了跨终端的无缝切换,让各类终端相互协同组成“超级终端”。2019年,华为首次“1+8+N” 全场景智慧战略,“1”是智能手机,“8”是指围绕手机的、华为自研的车机、音箱、耳机、手表/手环、平板、大屏、PC、AR/VR产品,N则指众多泛IoT设备,是华为与生态伙伴,例如摄像头、智能秤等外围智能硬件;

鸿蒙计划打造面向万物互联的人机交互统一入口,我们认为大模型未来将深度赋能智能助手“小艺”,叠加鸿蒙软总线能力,有望成为“超级终端”的“大脑”,加速万物智联时代来临。在华为的愿景中,未来的万物智联是通过智能助手“小艺”实现统一交互,解决不同IoT设备入口的差异,然后从海量应用中找到用户需要的服务,最终的目标是让终端真正懂用户、让设备去将服务推荐给用户,而不是用户自己去查找和调用服务。我们认为,大模型赋能后,可以让此目标更近一步,比如智能家居系统中,大模型可以助力设备实现更准确的协同响应;此外大模型还可以根据用户的行为习惯和生活模式,自动调整家庭环境的温度、湿度和照明等条件,为用户创造舒适的生活环境。目前,大模型已经和华为手机中的小艺深度融合;未来,大模型如果能深度融入鸿蒙OS、部署于各个设备,将有望成为“超级终端”的“大脑”,让万物智联真正进入现实生活

鸿蒙渗透率攀升,生态逐步繁荣。自上线以来,鸿蒙OS仅用两年时间就实现用户数就突破1亿,四年时间从1.0升级至4.0。2023年8月,华为在HDC大会上官宣鸿蒙生态设备数量为7亿台;2024年1月,鸿蒙生态设备增长至8亿。根据IDC数据,2023年前三季度,在中国智能手机操作系统市场中,安卓份额为71.8%,iOS占比16.4%,鸿蒙份额11.8%。
鸿蒙PC或将于今年发布,鸿蒙生态拼图渐趋完整。2023年,软通动力子公司鸿湖万联率先完成了OpenHarmony操作系统基于X86架构的英特尔芯片在PC端的适配。2023年12月,华为高管余承东在花粉年会上表示,华为即将在2024年推出非常有引领性、创新性、颠覆性的产品。
正如鸿蒙设备开发官网所说,鸿蒙OS为不同设备的智能化、互联与协同提供了统一的语言,根据用户不同需求和不同使用场景将生态伙伴各类相互分离的设备协同联动起来。我们看好终端智能化趋势下,鸿蒙软硬件生态的迭代发展,建议关注大模型赋能下鸿蒙万物智联更上一层楼,以及未来基于鸿蒙OS的AI手机、AI PC等各类AI终端;

人形机器人是是一种设计来模仿人类外观和行为特征的机器人,其主干结构与人类相似,包括头部、躯干、手臂和腿,所以能在一定程度上模拟人类的行走、抓取物体等物理动作。我们认为,人形机器人是目前具身智能最好的形态,因为它们有着与人相似的外观设计,能更好地适应按照人的身体尺寸和操作习惯而设计的环境和基础设施,例如门框的尺寸、开关的位置、工具的握把等。这意味着,无需对外部环境或工具进行过多额外的修改或适应,人形机器人便能无缝融入并承担多种工作

智能化趋势明确,大模型将成为机器人“大脑”。腾讯首席科学家张正友认为机器人要从自动化变成自主化(智能化)。目前很多工业机器人可以精准做好预编程的动作,而智能机器人要实现自主,能在环境不确定时自动调整,以应对没有预测到的情况。而大模型的庞大知识库、强大的通识理解能力和泛化能力让机器人智能化向前迈进一大步。
4.1具备思维链及零样本学习特性,大模型开启机器人智能化新篇章
具身智能的核心为“主动感知”和“物理交互”。具身智能(Embodied Intelligence)是人工智能的一个子领域,关注的是智能体如何在具有实体形式的情况下,通过与环境的物理交互来学习、适应并获得认知能力。具身智能的一个重要特点是强调了“感知-行动回路”的重要性。这意味着智能体需要通过感受世界、对世界进行建模,进而采取行动,并通过行动的反馈来调整和优化其模型。这一过程与人类的学习和认知过程相似,即通过实践和经验来学习和适应。
具身智能机器人从上到下可划分为:大脑、小脑、主控系统、主干结构以及零部件。大脑负责规划决策、分解任务;小脑负责全身的运动分层控制;主控系统,包括实施系统调度、通信协议站、CPU、GPU、FPG硬件加速进程和算力的优化;主干结构及零部件有双臂、足式、轮式等,类似于人的一系列关节和肌肉;
具备思维链及零样本学习特性,大模型有望成为机器人的“大脑”。思维链是大模型涌现时出来的一种特殊能力,是被偶然发现的——有人在提问时以“Lets think step by step”开头,后面发现AI自动把问题分解为多个步骤,然后逐步解决。谷歌在研发机器人模型RT-2时受到LLM思维链提示方法启发,将机器人控制与思维链推理相结合,使其可以执行多阶段语义推理

斯坦福李飞飞团队VoxPoser系统让机械臂实现了零样本的日常操作任务轨迹合成:1)机器人用相机采集RGB-D图像,并输入自然语言指令;2)LLM根据这些内容编写代码,所生成代码与VLM(视觉语言模型)进行交互,指导系统生成相应的操作指示地图,即3D Value Map;3)动作规划器将生成的3D地图作为其目标函数,合成最终操作轨迹

4.2端云融合AI为机器人打造智能高效“大脑”
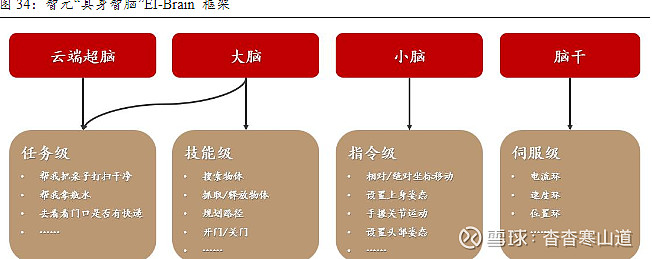
端云混合的“大脑”让机器人既能处理复杂和高强度的计算任务,又能实时进行信息处理和分析。基于混合AI思想,智元机器人团队打造出具身智脑EI-Brain框架,包括部署在云端的超脑,部署在端侧的大脑、小脑以及脑干,分别对应机器人任务不同级别的技能,包括技能级、指令级、伺服级等。具体来说,“大脑”进行抽象思考、多级推理,“小脑”负责运动控制方面的指令生成,“脑干”负责电机控制、伺服等硬件底层任务
4.3产业催化不断,人形机器人有望迎来奇点时刻
英伟达公司成立具身智能实验室GEAR,专注四大关键领域研究:多模态基础模型、通用型机器人研究、虚拟世界中的基础智能体、模拟与合成数据技术。2月24日,英伟达高级科学家JimFan在X上宣布,英伟达将在内部组建一个新研究小组专攻通用具身智能体研究,并强调“2024年将是属于机器人、游戏AI和模拟的一年”。
英伟达将在3月下旬的GTC上发布机器人领域成果。Agility Robotics、波士顿动力、迪士尼和Google DeepMind等全球领先的机器人公司将在活动中共展示25款新一代机器人产品,包括人形机器人、工业机械手等。
初创公司Figure AI获北美AI大厂看好,OpenAI、亚马逊、英伟达等参与融资。2024年3月1日,OpenAI官宣将与Figure合作,专为人形机器人打造下一代AI多模态模型,而Figure创始人Brett Adcock认为“Figure的人形机器人是AGI的最终部署载体”。Figure还宣布了6.75亿美元的巨额B轮融资,亚马逊创始人贝索斯、英伟达等参与,此前Figure AI已获得来自OpenAI和微软的支持,本轮融资前的估值已达到约20亿美元

1)算力基础:中科曙光、神州数码、浪潮信息、高新发展;
2)AI PC:华勤技术、龙旗科技、联想集团、星环科技-U、海光信息;
3)终端鸿蒙:润和软件、九联科技、东方中科、软通动力、中国软件国际、拓维信息、初灵信息;
4)拥有丰富终端资源的公司:海康威视、大华股份、科大讯飞、萤石网络、漫步者;
5)B端应用:北路智控、智洋创新、云涌科技、商汤-W、云从科技-UW