文/卫剑钒
前段时间学习了大模型的工作原理,学完之后,我决定改变自己的大脑思维模式,向大模型学习。
大模型的智能,显然还不是人类的智能,但它的结构和训练过程,非常值得学习。正是这独特的模型和方法,让它产生了令人震惊的效果。
大模型本身是受人脑启发的,所以,它做的好的,我们人脑完全可以学习。
本文所称大模型,是指大语言模型LLM,是指基于Transformer结构的大模型,如果举例,本文主要以GPT3为例。
一、学习大模型的字字珠玑
你知道吗,在大模型里,每个字都有一串不同的数值,就像是这个字的密码一样,神秘而不可名状。这些神奇的数值被送入大模型神奇的注意力机制和神经网络,就出现了神奇的效果。
举个例子,我们看看“变形金刚”这四个字在大模型中是怎么表示的吧:
“变”:[-0.09, 0.06,-0.78, 0.25,-0.00, ..., 1.41, 0.76,-0.75, 1.13,-0.92]
“形”: [-0.30, 0.23,-0.09,-0.67,-0.57, ..., 0.72, 0.20,-0.58, 0.21, 0.08]
“金”: [-1.15,-0.46,-0.02, 1.10,-0.43, ..., 0.42,-0.41,-0.62, 0.44, 1.21]
“刚”: [1.20,-0.91,-0.19,-0.40,-0.88, ...,-0.38, 0.09,-0.81, 0.61, 0.93]
注意,省略号代表省略了一堆数值。从术语上讲,可以把这些数值称为一个字的“特征向量”,数值的个数就是向量的维度。
对于GPT3,其维度高达12288,就是说,每个字由12288个数值来表达!
这些数值代表了什么呢?打个比方,我们说“狗”是动物、是哺乳类、有毛发、会叫、有一定智能、比较忠诚、有一定攻击性、杂食、需要适度运动,可以用 9个数值来表达,但是GPT3却用了12288个数值!
没人能说清,这么多维度中的每个数值表达了什么含义,只有大模型自己知道。
这些数值如何得来?当然不是人赋的,而是训练出来的。大模型在学习大量语料的过程中,不断调整对每个字的认识,直至整个模型令人满意时,训练结束,这些值也就定下来了。
大模型的这个特点,让我觉得,对每个字、每个概念,应做细致的考察和理解,要尽可能全面地抓住它的意思,这样,才能更好理解和掌握文字。
越全面,智能越强。
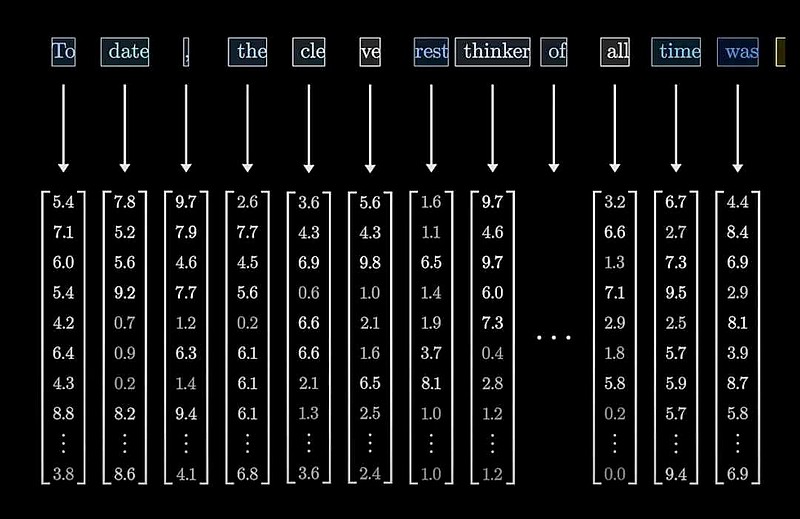
每个文字进入大模型先转为特征向量
二、学习大模型的融会贯通
曾有哲人说过,“你想要了解一个事物,就需要了解一切”。
现在看来,他不仅是对的,而且是太对了。
想要成为经济学家?单啃经济学的书可不行,你还得懂政治、懂社会、懂人性、懂历史,懂哲学。
想成为军事家?准备好跨界吧!你需要知道的不止是行军打仗,还得懂农业生产、武器制造、工程建设、金融资助、物资运输、信息科技,当然,你更要懂人性、懂文化。
想成为人工智能专家?这可不是敲敲键盘那么简单,你得懂语言学、逻辑学、数学、心理学、脑科学、工程学,还得懂哲学!
真正的天才,事实上都是通才。
大模型就是个通才。
ChatGPT之所以惊艳世界,是因为它几乎无所不知。
而这背后,是它啃了45TB语料的结果。45TB,相当于数百万本书的信息量!
正是通过对这些语料的刻苦训练,大模型学会了给每个字合适的特征向量,学会了建立靠谱的神经网络条件反射,学会了算出最适合的下一个字。
大模型并不记录任何知识,比如,它并不记录“中国的首都是北京”,但你问他中国首都是哪里,它肯定能回答出来是北京。所有的信息都在神经元连接的权重参数之中,他看到“中国”和“首都”,就能下意识反应说“北京”。
这些用于构成条件反射的权重参数,数量庞大(对GPT3而言,有1750亿个),没人知道这些权重都是什么含义,人们只是知道它们能呈现出惊人的效果。
这些权重并不是人工赋值的,它们也是训练出来的,计算机逼着大模型学习海量语料中的任意一段文字,逼其调整权重,使之能够预测任意一段文字的下一个字,而且误差要让人满意。
一旦做到这点,就意味着,它知道人怎么说话,人怎么想问题,人怎么看世界,大模型以它的结构和它的参数,拟合了数百万本图书量的高质量文字,它相当于掌握人类的知识。
相比之下,每个人学的东西太少了,每个人懂的也太少了。高人和一般人的区别就在于,高人掌握更多高质量的信息,高人拥有更多靠谱的神经连接。
虽然机器和人学习的方式并不一样,但有一点是肯定的,博览群书、见多识广,总比不读书、闭塞要好。
向大模型学习,看得更多,懂得更多。

三、学习大模型的心领神会
大模型只是在不断输出下一个字,但每一个字的输出,都是经过反复锤炼的。
我们知道,一个字,在不同的句子中,有不同的含义,比如“我喜欢黄金首饰”和“这是一个变形金刚”,虽然里面都有“金”字,但“金”的含义大不相同。
大模型是靠注意力计算和前馈神经网络来识别语义、形成语境的。
所谓注意力计算,就是对一段文本中求得其中每一个字对其他每一个字的关系(本质上是字和字的特征向量间的点积计算),然后用这个关系对每个字的特征向量进行调整。
比如,对于“金”字,训练好后,就是一个初始的向量值,想知道“金”字在某段文本中的含义,要看周围的字。
“金”字附近,是“黄”,是“首饰”,那么这个“金”字,就会是黄金首饰的“金”。
“金”字附近,是“刚”,是“变形”,那么这个“金”字,就会是变形金刚的“金”。
经过注意力计算后,“金”在这段文本中的特征向量会调整到合适的位置。
不光“金”字,文本中的所有字都会被调整,调整为贴合人意的语境。
之后,这些特征向量,会送往前馈神经网络,让大模型做进一步的联想和推理,大模型很了解,人们在说“我喜欢黄金首饰”时,通常接着会说“我想买一个”之类的话。
以上的“注意力计算 + 前馈神经网络”就是一层计算,做完一层后,会再做一层这样的计算,循环往复,做若干层。对于GPT3,做96层。
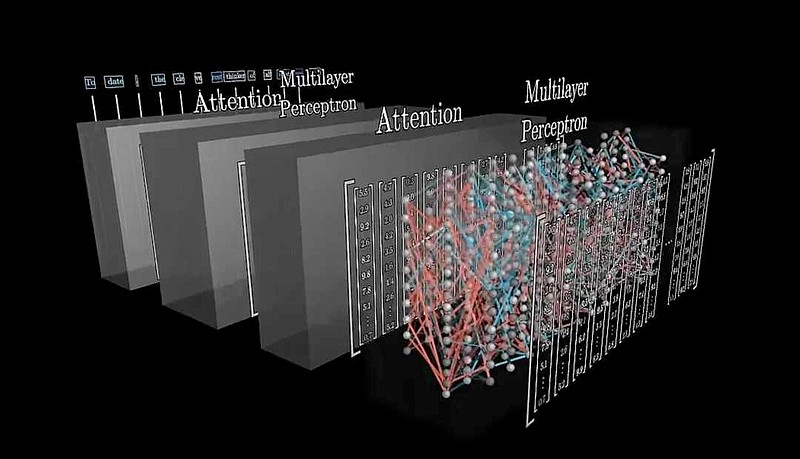
大模型通过层层注意力计算和神经网络实现智能
研究表明,前几层计算专注于理解语法、解决词汇的歧义,后面的层则致力于对整个文字做高层次理解。
比如,你扔给大模型一段故事:
“大壮有个表弟叫小帅,他喜欢变形金刚……有一天,大壮发现……于是,大壮前往英国……”(故事略去)
LLM的前面若干层计算中,基本上是做语法分析,比如这里的“金”是“金刚”而不是“金子”,“变形”是个形容词而不是动词,“大壮”是一个人名而不是“大壮山河”,“他”指的是“小帅”而不是“大壮”。
在后面的层次的计算中,会做更高层的逻辑分析,对一个人的刻画也更精确和完善,比如算到第60层时,GPT3基本上就分析出来:
“大壮”有如下特点:主角、男性、小美的男朋友,小帅的表哥,来自美国,目前在英国,试图找到他丢失的钻石。
经过96层的分析计算,大模型掌握了故事里面每个人、每件物品、每件事,了解它们的特征、处境、历史和现状,然后将这些信息存放在每个字的特征向量之中。
然后,这些值被送到最后一个神经网络,以输出要预测的下一个字。在做了前面那么多分析和研究后,下一个字几乎是呼之欲出的。
比如对于“我喜欢黄金首饰”,可能就会接着一个逗号,然后接着“戴着真漂亮”或者“我想买一个”。
对于“这是一个变形金钢”,可能也会接着一个逗号,然后接着“真酷”,或者“我想玩它”之类的。
大模型告诉我们,想要深刻理解一个东西,就要不断思考,翻来覆去思考,从各个层面思考,最终,肯定会越来越明白。这就是“书读百遍,其义自现”。
反过来是一样的,如果我想让人比较容易地理解一件事,我最好能营造出丰富、生动和完整的语境,让听者身临其境,然后,他自然就能领会我的意思。
四、学习大模型的自我修炼
大模型的训练方法,是反向传播算法,它计算输出和期望的差距,通过偏导计算,逐层逐步调整模型参数,使输出逼近期望。
做人是一样的,了解现状,定位目标,分析差距,反思原因,调整要素,然后再看调整后的系统效果,不满意就再来一轮。这是很常见也很自然的做法。
比如,你发现自己的演讲能力不够好,那就可能需要调整思想力、表达力、演讲技巧和自信心。当然,这并不容易,正确分析出问题症结,比大模型求偏导要难得多。
然而,人类有一种自动调节的能力,就是模仿、重复、背诵、演练,这就是对人脑的训练。
人工智能历史上,有两大派,符号派(将一切抽象为符号,建立逻辑系统)喜欢理性分析、逻辑推理;连接派(神经连接的意思,大模型就是连接派的产物)喜欢野蛮训练,大力出奇迹。
现在,连接派胜出了,符号派投降了。
比如,学习英语,符号派会去学习语法,连接派会去做大量阅读和背诵,谁能学得更好?
古人明白这点,他们“熟读唐诗三百首,不会作诗也会吟”。
五、学习大模型的举重若轻
马斯克今年3月份开源的大模型叫grok,这个名字取得可真巧妙。
grok,来自科幻小说《异乡异客》(Stranger in a Strange Land,1961),是火星人(说的是真火星人哦)使用的一个词语,指“理解深刻、符合直觉”(to understand profoundly and intuitively)。
大模型已经练就这样的能力:随便你扔给它什么问题,它都不怕,它不慌不忙,按照内部神经连接,完成计算,吐出答案。
它从来不会因为问题很难,就思考半天。
它像下意识般,口吐莲花,输出一个又一个字。
这种能力,要求对文字有深入理解,要求对世界领悟深刻,大模型经过千锤百炼,它能做到。
我们,最好也能这样,内功深厚,见招拆招,举重若轻。