出口成章已是过去式,出口成“视频”才是现在时?
最近几天,sora的热度只增不减。Sora是美国人工智能团队OpenAI发布的首个文本生成视频大模型。据了解,Sora的文本生成视频不仅在时长上取得了突破,时长达到60秒,而且质量稳定,能够模拟物理世界和数字世界的人物、动物和环境。
Sora堪称惊艳的视频生成能力,“技惊四座”,并很快引起了同为AI科技圈特斯拉CEO埃隆·马斯克的注意。近日,马斯克更是在推特上直言:“特斯拉拥有世界上最好的现实世界模拟和视频生成能力!”
Sora与马斯克两大神仙打架,谁的“视频生成术”更胜一筹?
Sora与马斯克,本是同根生?
Sora与马斯克,一直关系匪浅。
一方面,马斯克原本是Sora背后的公司OpenAI的联合创始人,只不过后来被踢出了董事会。据了解,马斯克在OpenAI转变为盈利公司后,曾多次在公开场合批评和指责OpenAI开始逐利、失去初心。
另一方面,马斯克探索的视频生成技术方向以及其背后的逻辑与Sora十分相似。
其实,“文生视频大模型”并不是一条全新的赛道,早在sora之前,市面上的头部大模型就已经在探索视频生成技术了。据相关媒体报道,在OpenAI登场之前,头部大模型研发商几乎都拥有自己的文生视频大模型。例如,Google的Lumiere以及Stability AI的SVD(Stable Video Diffusion),甚至已经诞生了垂直于多媒体内容创作大模型的独角兽,例如视频生成大模型Gen-2的开发商Runway,在2023年6月底完成由Google、Nvidia、Salesforce参与的C轮融资后,估值超过15亿美元。
而后来者Sora之所以能够引起轰动,更多的在于其在技术层面和逻辑层面的重大突破。
技术层面,据悉,Sora最令人震撼的技术突破莫过于视频时长的巨大提升。Sora能生成长达1分钟的视频,远超市面上其他AI视频模型。此前,Runway能够生成4秒的视频,用户可以将其最多延长至16秒,这已经是AI生成视频在2023年所能达到的最长时长纪录:Stable Video能提供4秒的视频,Pika则提供3秒的视频。
逻辑层面,Sora展示出了对物理世界部分规律的理解,解决了过去文生视频模型的一大痛点。有专家分析指出,Sora带有“世界模型”的特质,这让其在逼真度上更胜一筹。
而特斯拉的世界模型和Sora之间的最大相似点,也是逻辑层面。据悉,二者的技术底层逻辑都是通过视觉让AI能够理解甚至模拟真实的物理世界。
去年7月,特斯拉自动驾驶软件总监Ashok Elluswamy在CVPR2023的演讲中提到,特斯拉正在为其人工智能技术构建一个基础的世界模型(General World Model)。
同时,据马斯克介绍,特斯拉的视频生成技术是基于其模拟现实技术而开发的。通过这种技术,特斯拉能够构建一个动态生成的世界,这个世界并不是简单的图像拼接或动画模拟,而是基于真实世界的物理规则和数据来生成的。这意味着,特斯拉的视频生成技术不仅能够呈现出逼真的视觉效果,更重要的是它能够预测和模拟出极其精准的物理场景。
不过,二者的底层逻辑也存在差异。有业内人士分析指出,特斯拉目前的视频生成技术逻辑,是基于过去的视频,给出车辆行动提示,甚至不给提示,该模型可以预测不同的未来情况,以及生成视频。
也就是说,特斯拉目前的视频生成技术是基于过去的视频进行动态生成的,而不是基于文本的输入。对此,有业内人士分析表示,这或许意味着特斯拉的视频生成技术可能更依赖于数据的质量和数量,而不是模型的复杂度和创造力。
晚了一步的马斯克,相煎何太急?
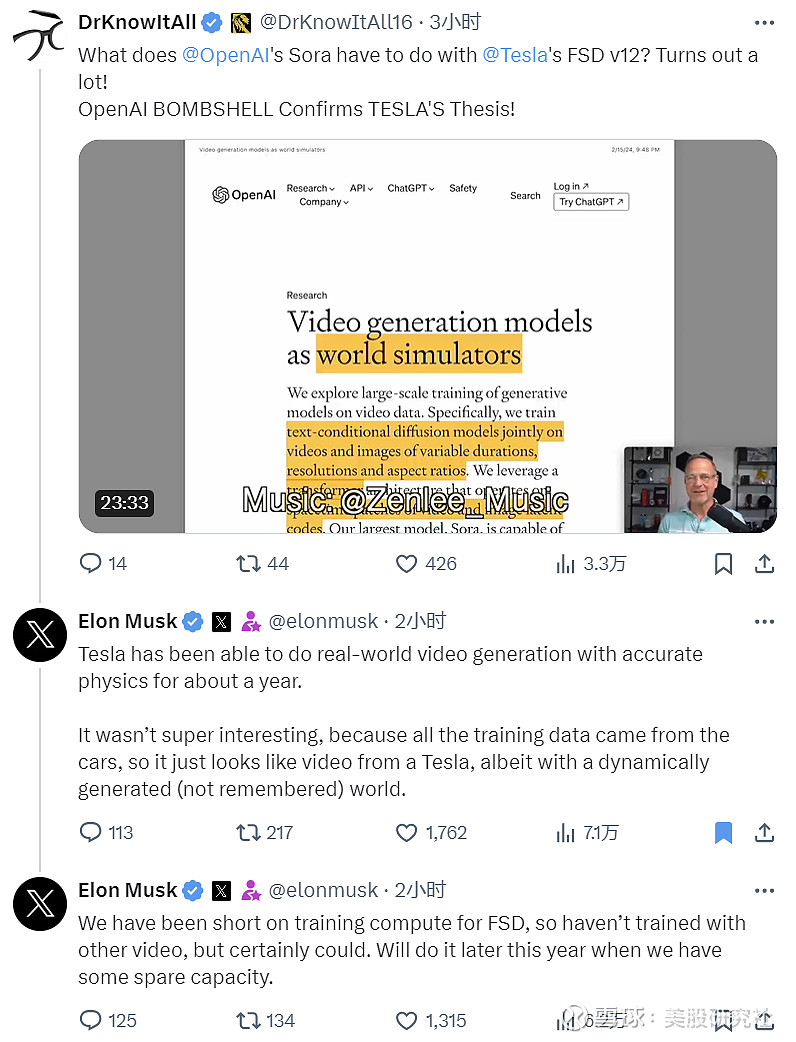
在Sora出现在公众视野之前,马斯克的特斯拉早在一年前就具备了相似的技术。
马斯克表示:“特斯拉在大约一年前就能以精确的物理生成真实世界的视频。只不过,由于训练数据来自汽车,生成的视频并不有趣。这些视频看起来像特斯拉的普通视频,实际上是通过动态生成的。”
只不过,由于发展方向不同,马斯克这一次似乎失去了技术公布的“先机”。目前特斯拉的视频生成能力主要运用在了探索自动驾驶上。而OpenAI的Sora则一直将重心放在生成视频上。方向不同,重心也就不同。因此,相比于OpenAI先放出Sora给世界带来一点震撼的方式,晚了一步的马斯克也情有可原。
也正是在自动驾驶上的深耕,让特斯拉的视频生成技术有希望与如今风头正盛的Sora一较高下。
第一,特斯拉FSD的成功依赖于对大量真实世界数据的处理和学习能力,这与OpenAI探索AGI的途径有共通之处。两者都需要大量的数据、高效的算法和强大的计算能力。所以,有业内人士猜测,如果OpenAI能够在AGI领域取得突破,那么特斯拉在FSD上的成功也显得更加可行。
第二,由于特斯拉FSD专注于自动驾驶这一特定的应用场景,技术难度和复杂性可能低于开发能够执行广泛任务的通用人工智能系统。同时,特斯拉拥有大量的实际驾驶数据,这为FSD的训练提供了丰富资源。这也是不少业内人士猜测其技术突破和实现自动驾驶的时间可能比OpenAI实现通用人工智能要早的重要原因。
不过,相比于Sora,特斯拉的视频生成能力仍存在局限性。
算力是限制特斯拉的主要因素。据了解,视频生成涉及大量的视觉信息处理,所需计算量远超文本生成。模型可能需要在数以亿计的参数上进行训练,消耗巨大的GPU算力资源。此外,文生视频模型需要结合音频、文本等多个模态信息,这就需要模型能够有效融合不同类型的输入信号,并输出相应的跨模态内容,无疑将大大增加模型设计和训练的难度。
而在对一则讨论OpenAI Sora和FSD的视频下,马斯克也回复到:“我们在FSD的训练计算能力上一直比较紧张,因此没有使用其他视频进行训练,但这是肯定可以做到的。我们计划在今年晚些时候,当有一些空余能力时进行这项工作。“
同时,自动驾驶仪工程的负责人Ashok也直言,公司目前的视频生成模型也还只是个“半成品”,关键是它可以提供一个神经网络模拟器,推演出不同的未来结果,跟踪道路中所有移动的物体。
可见,Sora的发布的确让马斯克产生了些许危机感。
好在,Sora并非完美无瑕。在Sora公开的Demo视频中,存在不少生成式AI脱离现实逻辑的漏洞。例如,随着时间推移,有的人物、动物或物品会消失、变形或者生出分身;或者出现一些违背物理常识的画面,比如穿过篮筐的篮球、悬浮移动的椅子。
OpenAI在技术报告中也坦诚地公布了Sora的不成熟之处。据悉,OpenAI表示,Sora可能难以准确模拟复杂场景的物理原理,可能无法理解因果关系,可能混淆提示的空间细节,可能难以精确描述随着时间推移发生的事件,如遵循特定的相机轨迹等。
多年从事计算机视觉研究的上海交通大学人工智能研究院副教授王韫博也认为:“Sora对真实世界的模拟还有很大提升空间,就目前的展示内容来看,并不意味着它已经‘读懂了’物理规律。”
英伟达高级科学家Jim Fan也指出,目前Sora对涌现物理的理解是脆弱的,远非完美,仍会产生严重、不符合常识的幻觉,还不能很好地掌握物体间的相互作用。
总之,留给马斯克追赶的时间似乎还很多。而Sora最后又能否成为文本生成视频领域的“真老大”,现在定论,似乎也为时尚早。