相信大家都在寻找产品的过程中花费了不少精力。
此前我们曾在《网页链接{嘟嘟的投研CheatSheet · 如何利用机器学习进行产品聚类}》介绍了如何使用机器学习对基金产品进行聚类,从而快速找到我们需要的产品。
今天我们以公募基金为例,尽可能完整地跟大家介绍上述工具的使用方法。
在开始进行聚类之前,首先我们需要知道,公募基金有哪些分类,每个分类的核心特征是什么。
图表 设置获取所有公募基金
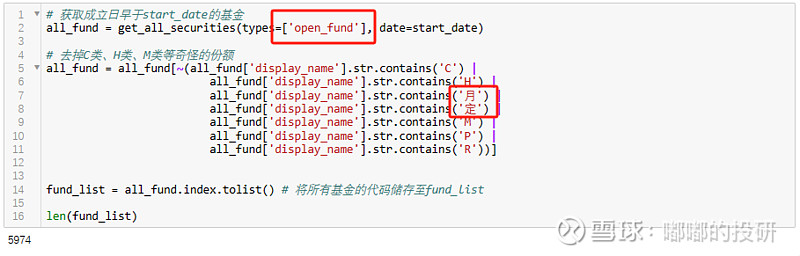
比如,从波动率角度,公募基金从货币到债券再到股票,大体呈现下图所示的分布特征:
图表 各类公募基金产品年化波动率算术平均分布
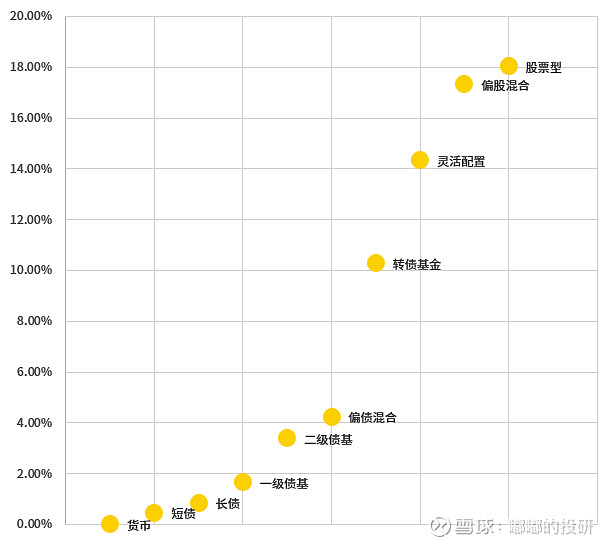
那么在接下来聚类的过程中,我们核心要控制的参数一个是波动率,另一个是拟分类的数量,即我们打算把某一波动率区间内的产品,让机器学习分成几类。
示例1:货币
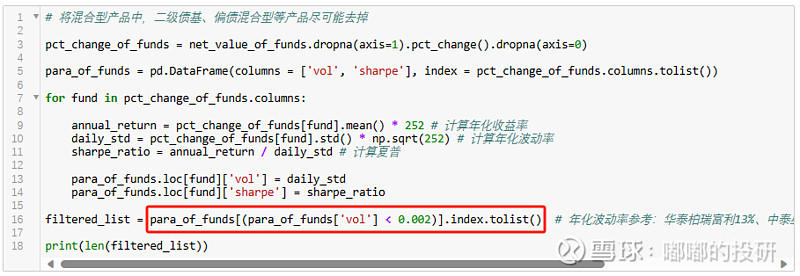
由于货币基金的年化波动率通常小于0.2%,那么我们先按照0.2%进行设置。
图表 聚类核心参数1:波动率设置
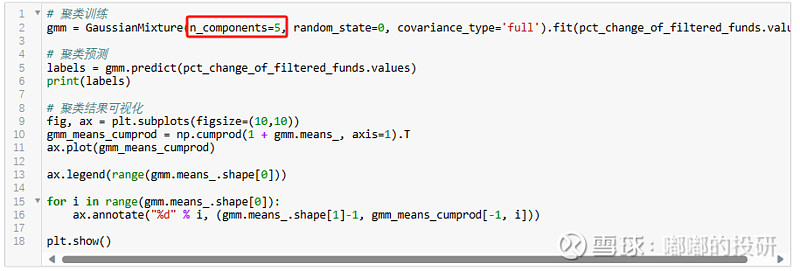
而在拟分类数量方面,大家可以多尝试不同的值,比如我们先设置成5,从聚类结果来看,5类产品丝毫看不出有什么区别,基于此可再重新设置回1,最后便得到一系列高夏普的货币基金清单。
图表 聚类核心参数2:拟分类数量
图表 当拟分类数量为5时,结果并没有显著差异
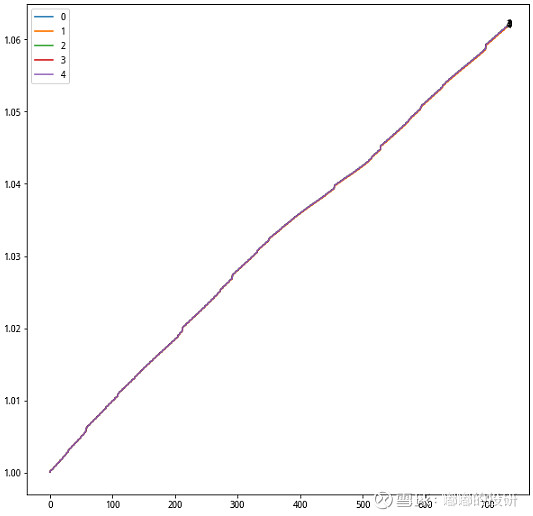
图表 高夏普货币基金清单
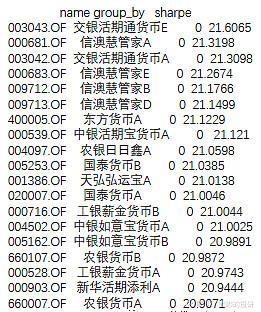
当然了,因为货币本身没有投资风险,其实筛选不用这么复杂的过程,不过此处更多是为了说明基金聚类应该怎么来使用。另外我看了下上述产品大部分还是跑赢了市场平均水平的。
示例2:纯债
具体尝试的过程示例1已有描述,在此直接告诉大家关键参数设置:波动率筛选区间为0.2%-1%,拟合数量为2,由此我们得到的便是长债跟短债两类产品的集合。
图表 通过聚类快速识别为短债、长债两类产品
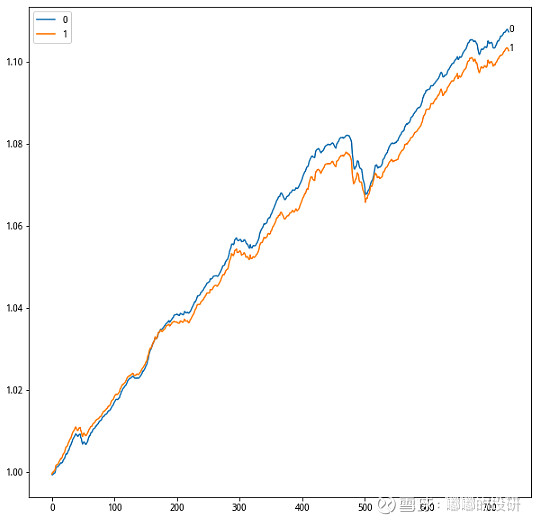
分类0为长债,分类1为短债,当然了,这个分类也不是绝对的准确,像我们在分类0中也偶尔能看到短债产品,但确实能找到很多不错的产品。
图表 高夏普债券基金清单
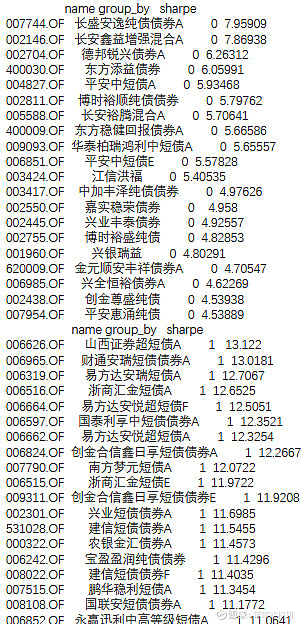
示例3:固收+
关键参数:波动率1%-4%,拟合数量3,得到纯债、固收+、干扰项三类。
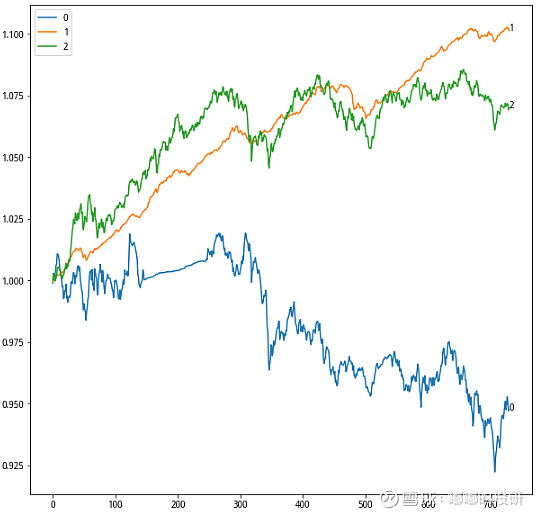
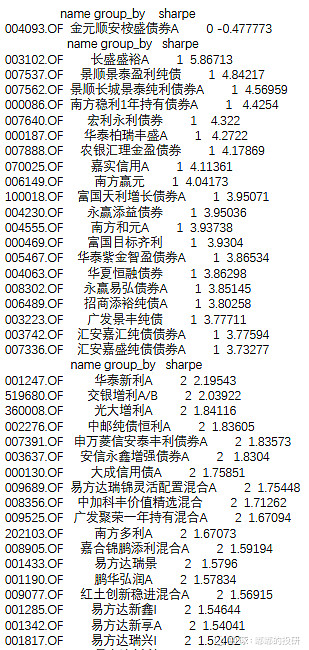
示例4:权益
至于权益的聚类分析上一篇文章已有提及,核心参数是波动率大于10%,分类数量4,在此不再赘述。
当然,还有一个关键参数是时间,我们输入的时间周期越短(比如近1年),理论上能拿到的分类结果越精确。

以上我们主要是通过波动率的维度去进行产品的筛选。当然筛选的标准并不唯一,大家也可以尝试使用包括收益率、最大回撤等指标进行,我相信最终结果应该是殊途同归的。在不同的参数选择上,大家可以多尝试下不同的组合,没准会有以外的收获,比如发现一些此前忽略掉的策略等。
除了在公募基金领域,我们也能把上述思路应用在私募基金的筛选上,只不过净值数据的获取对于大部分FOF机构来说会有难度。如果机构愿意花钱去买朝阳永续的数据库,那可以一次性解决聚类所需要的底层净值数据问题,如果机构不愿意的话,我们就只能挨个找管理人要净值的托管邮箱发送,然后再通过IMAP获取邮箱净值数据,最后再进行分析,后面我们也会把邮箱读取净值的方法跟大家做个分享。
本文所需完整代码此前已上传星*球,关键词:如何利用机器学习进行产品聚类