我把刘翔写的报告直接搬过来了:
不知道啥时候会轮到。
以下原文:
超微电脑最近发布了最新款的AI人工智能服务器。超微电脑是一家服务器厂商,也是美股明星股,一年涨幅15倍的那个。
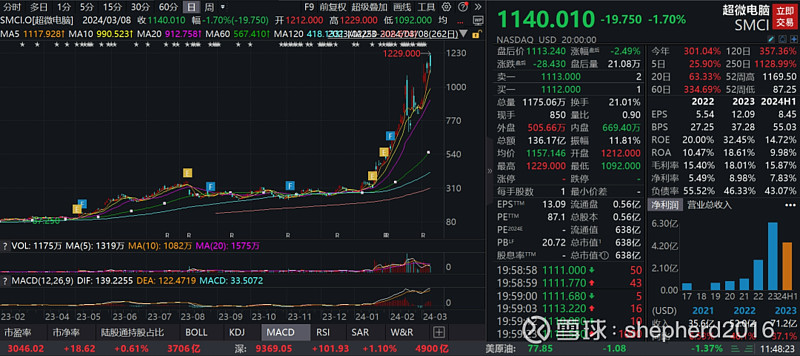
该AI服务搭载的GPU是AMD的MI300X,名叫:GPU A+ Server AS -8125GS-TNMR2。我们通过拆解它,来找出到底有哪类芯片才是AI半导体的主角?GPU大家都能想到,但有一类芯片很关键却不被广知,存在极大预期差。
为了探明究竟,我们先来看GPU A+ Server AS -8125GS-TNMR2的外部结构图,最新款AI服务器、具有典型代表性。


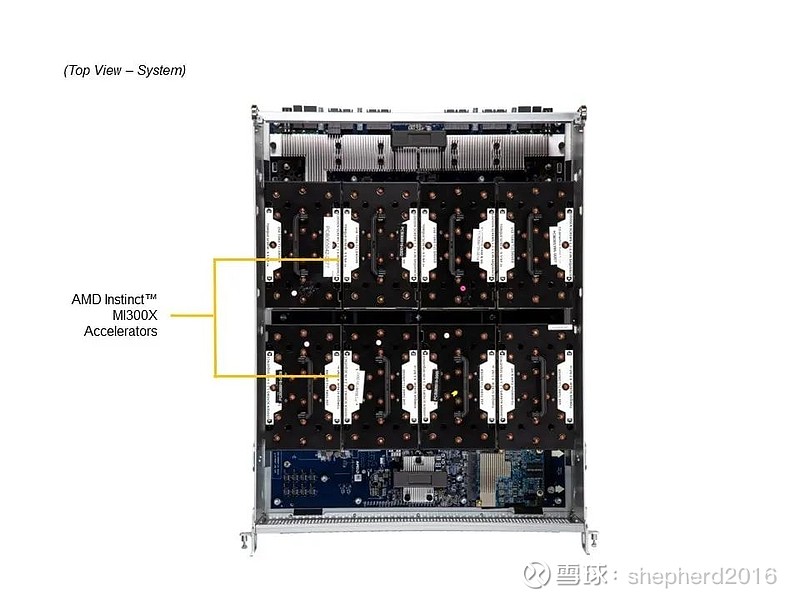


如上,外部结构大概也可以看出来:8个AMD MI300X加速卡(GPU)、2个AMD EYPC4代处理器(CPU)、4个PCIe Switch、24根可插拔内存条、18个可插拔硬盘。
真实的内部框架图应该如下:
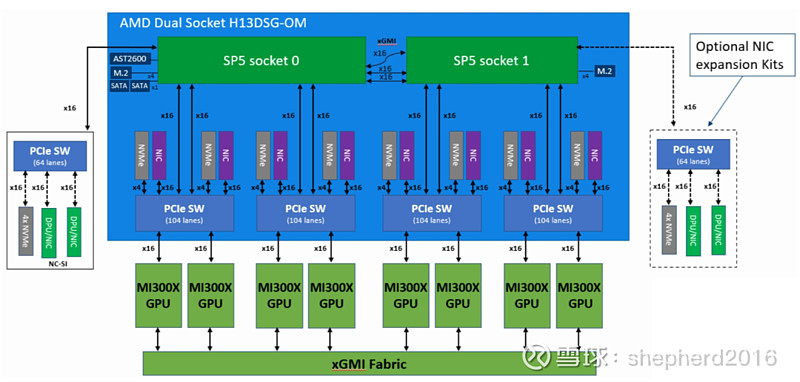
可以明显地发现:除了几个关键的逻辑功能模块(GPU、CPU)、存储模块(NVMe)之外,剩下的基本都是桥接模块(xGMI Fabric、PCIeSwitch、DPU、NIC)。
AMD家的xGMI Fabric相当于英伟达家的NV-Link。因为在单个服务器内有若干个GPU(一般是8个就像我们这个例子,最多16个),他们之间要协同计算需要数据互通。这个互通数据率还蛮大,PCIe的协议达不到。因为是内部互联,所以干脆关起门来,自己定一个协议,自家芯片能识别就行。所以不用兼容乱七八糟的玩意,也不用各种数据包的帧结构开销,传输的都是类型单一的数据,数据率自然就可以做很高。
NVLink的传输数据率,也就是经常说的带宽,可以达到900GB/s,远超PCIe。此外,NVSwitch交换芯片还可用于连接多个NVLink,进一步扩展NVIDIA GPU集群的规模。这种互联网络技术能够提升模型训练的规模和速度,并被认为是NVIDIA在AI浪潮中取得成功的重要基石。
所以,英伟达2023年单这一块收入据实现了130亿美元,同比增长4倍。这是一块高速增长、却不会广知的领域,值得重视!
英伟达家有NVlink,AMD家搞GPU也需要就搞了一个功能类似的。在AI领域AMD 推出了Infinity Fabric(XGMI)互连并将其命名为Accelerated Fabric Link互连。
3月9日,博通公司确认其即将推出的PCIe Gen7交换芯片Atlas 4将对来自AMD的Accelerated Fabric Link(AFL)互连技术提供支持。这一消息意味着,在去年年底的AMD Advancing AI发布会上,AMD向生态合作伙伴开放了Infinity Fabric(XGMI)IP后,博通也加入了这一阵营。博通作为全球数通芯片的龙头,他的动向要重视!
Fabric、NVLink、PCIeSwitch这类桥接芯片,也可以称为网络芯片,他们的性能也很大程度决定了整台服务器的能力。
事实就是如此,英伟达也好、AMD也罢,他们家的AI GPU系统不断迭代的过程,尤其最新的几款卖点就是带宽升级,包括内存带宽升级和网络带宽升级。
Fabric、NVLink、PCIeSwitch主要构成的基石就是PHY,他们底层的PHY其实都是类似的。PHY是啥?PHY是物理层,所谓物理层就是只关心电气连接的物理形式(电压、电流等),不关心它是一个什么样的数据结构(4x4的像素块还是一个语音包)。
如下图,NVlinkSwitch结构,可不要小看这颗芯片哦。首先他有251亿颗晶体管,什么概念?苹果最新的iPhone15用的主芯片A17也才190亿颗晶体管而已,差了他25%。这颗芯片面积有294平方毫米,接近300平方毫米。什么概念?昨天(3月8日)博通业绩说明会上,博通给meta、google定制的AI加速器也才800平方毫米。也就是说这颗芯片接近GPU面积的一半。这颗芯片还有2645个输入输出端口(用的BGA封装方式),几千颗管脚封装超级复杂,而且还是高速信号BGA形式。
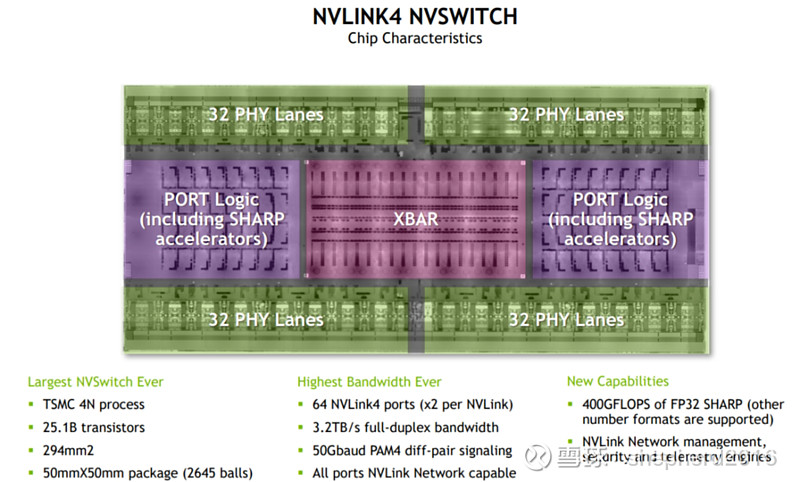
3.2TB/s的双向带宽,是因为有32*4条PHY。因为材料的物理极限限制,单条PHY的带宽是到不了T级别的。每条PHY的I/O输出信号是以对形式出现的差分信号,采用PAM4调制(就是这一对信号的电压差值组合有4个)。
不仅仅是Fabric、NVLink、PCIe,包括以太网、SATA,HDMI,USB,DisplayPort,他们的PHY原理都是类似的,因为这些高速信号的输入输出基本都是串行差分形式。
为什么是串行?因为数据率高了,单个baud(或者你理解为bit也行)的时长很短(纳秒级别)。如果采用并行,电路各种时延会导致原本并行的几队数据经过一段电路后,不再是齐头并进了,所谓的同步没法做了。因而要用串行方式。
为什么是差分?还是因为数据高,差分信号是成对出现,一正一负没有直流成分,具有很强的抗干扰能力,能有效抑制电磁干扰。所谓的EMI/EMC(电磁兼容性)好做。
也许是因为NV家的私有协议,我在网上找了很久也没有找到NVlink的PHY协议文本。不管哪种高速接口,其实底层都是类似的。为了更好地为读者说明,我找到PCIe的PHY协议。其发送端的结构框图如下,接收端就是发送端的逆结构。
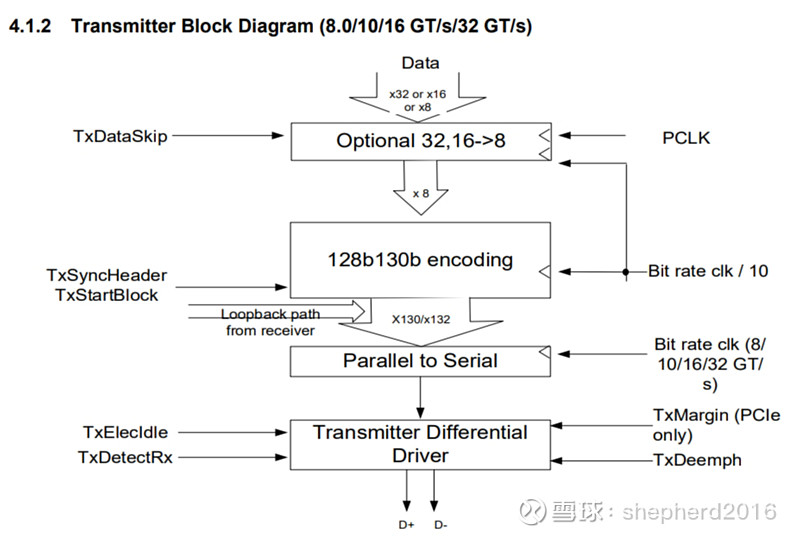
大致分为四步:
1.先把数据切成标准的8个或16个或32个一组;
2.在把一组数据编码(8b10b或128b130b),其实就是加几个校验位,当前面的数据出错的时候能判断出来,出错少还可以纠正出来。就像我们身份证后面几位一样,都是校验位。
3.编码后的一组组数据,变成一个个串行的bit序列。
4.bit序列调制变成一对对差分信号(比如网络双绞线),有的要调整,有的不用,比如NVlink就是PAM4调制,2bit变成一对差分电压信号。
这里面的sedes(Serial-DeSrial,串行解串)是关键能力,所以能做高速信号sedes的公司都值得重视。这一块本文作者是专家,十多年前就是全球领先高速接口龙头芯片公司的主要负责人。全球应该有数亿人受益于我的工作,成就感满满。但力求融会贯通的公众号不能太专业的态度,否则会很枯燥。
至于国内外有哪些值得关注的PHY公司,或者说具备高速sedes能力的公司有哪些?今天就不在这里讲诉了,知识星球里面会一一讲解。
回到主题:AI半导体除了GPU,还有一类特别关键却被忽视。这类就是NVlink、 Fabric、PCIe、DPU、NIC这种桥接芯片,价值量很大,门槛也很高。至于为什么价值量大、门槛高,我在上面已经做了部分解释了。
桥接芯片的核心公司:
华鹏飞,兆龙互联 龙讯