
大模型的火爆,彻底带火了智算中心建设和升级。
现在稍有点规模的企业级客户,都想着让自家的数据中心或者机房,能贴上“智算”的标签。

毕竟,有了智算这个基本盘,后续大模型落地,无论训练、调优、推理,都能“搂住底浆”了。
而在这个建设过程当中,大家最热衷于搞的,是「异构智算」。

为啥?
因为「异构智算」可以更好地适应不同客户的IT基础设施现状,让他们多快好省地搭上智算快车,开启大模型“训调推”之旅~

我们先来讲讲,到底啥是「异构智算」
在构建算力集群的时候,所有的算力卡不仅品牌一致,连具体的型号系列也完全相同,这属于完全意义的“绝对同构”。
这种配置,适合不差钱且抢货能力强的顶流客户,一出手就是上万片。

如果把这个方案变通一下,A厂或者B厂自家相近系列的GPU,各自组成集群,但A厂和B厂之间不掺和。
虽然没那么理想,但也可以算作一种“同构智算”。


一般来讲,同构环境相对来讲更容易搭建和管理,不要考虑那么多兼容性、稳定性问题。
可是,在实际情况中,甲方为了成本、利旧升级、供应链等多种原因,往往需要把希望把多家的GPU混合使用,共同扛活。
我把这种情况,称为「异构智算1.0」

GPU算力卡的异构,可以很好地平衡建设成本,缓解供货不足的问题,让企业尽快拥有智算能力。
不过,还有很多企业不满足,他们希望不仅是GPU加速卡异构,还希望GPU和CPU异构,更灵活地适应各种训练、调优、推理负载。

甚至,CPU还是多种型号、不同指令集的(X86、ARM),各种规格掺和在一起,一旦搞不好,就是大型甩锅现场。
我把这种情况,称为「异构智算2.0」
目前来看,业界已经有供应商能够支持这样的方案,允许多样性算力混合编队(不同类型的GPU/加速卡,不同指令集的CPU)。
大家求同存异,团结起来,一起把锅背好↓

你以为这样就是终极方案了吗?不!
最近又出现了一种新需求:能不能把之前建设的HPC超算中心跟现在的智算中心融合一下,让超算干点智算的事儿,让智算也帮超算扛点活儿?

以前,大家都觉得没必要,因为智算和超算的工作负载有很大区别。
智算主要关注海量数据处理和模型训练,要进行大量的矩阵运算,侧重并行能力,对数据精度要求不高(单精度甚至半精度就够用)。

而超算属于计算密集型任务,需要大规模的数值计算和复杂的数据通信,对数据精度要求很高(通常需要双精度)。

但现在,随着两者硬件的趋同,算力卡短缺的智算领域萌生了“借鸡下蛋”的诉求,希望在HPC集群空闲时,共享GPU节点。
与此同时,大模型越来越牛,让AI for Science的需求日渐迫切,科研任务也需要智算加持一下。
So,「超智融合」的需求,突然变得紧迫起来~

于是,这就来到了“终极”异构智算方案↓
不仅是多种GPU、CPU异构,还要实现智算集群和超算集群的异构。
是不是有点难搞?but,真有人搞出来了。
就在上周,联想在TechWorld2024上,隆重发布「联想万全异构智算平台」。



通过一套“万全”,完全覆盖各种异构场景,为 AI 2.0时代提供高效、稳定的算力支持,实现高度自动化的AI全流程开发,提升应用部署速度,降低业务成本。
联想万全异构智算平台,都有哪些玄机?
先来看看联想万全异构智算平台的整体架构吧↓

在算力基础设施层,联想实现了各种协议和硬件的异构支持:
其中,计算同时支持海外和国产芯片(CPU、GPU、NPU、FPGA等),网络通信支持IB、RoCE以及各种私有协议,存储则实现了对各种主流并行文件系统、对象存储的兼容。

夯实这个异构底层之后,在上层,联想拿出了5大“绝技”,从不同层面帮助用户解决实际问题。
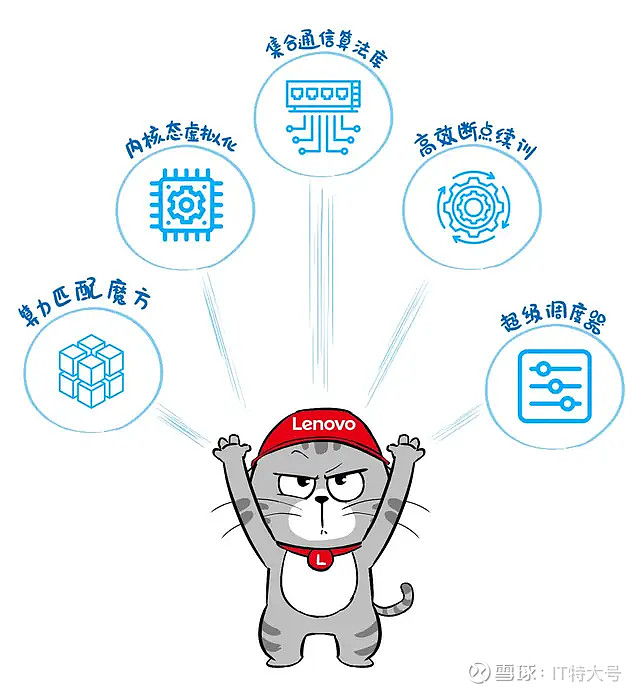
❶ AI与HPC集群超级调度器
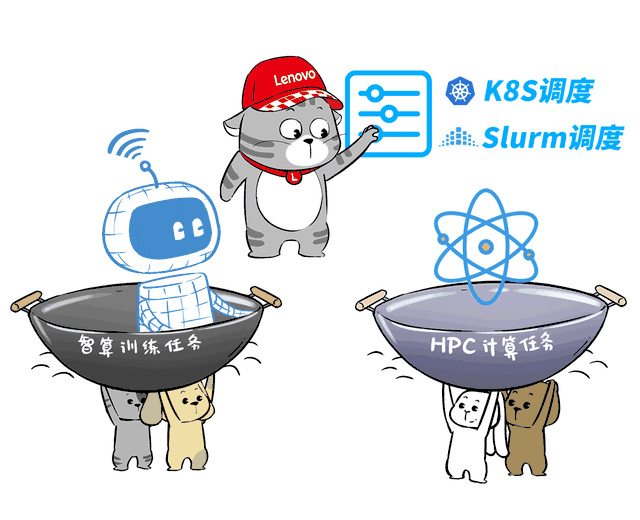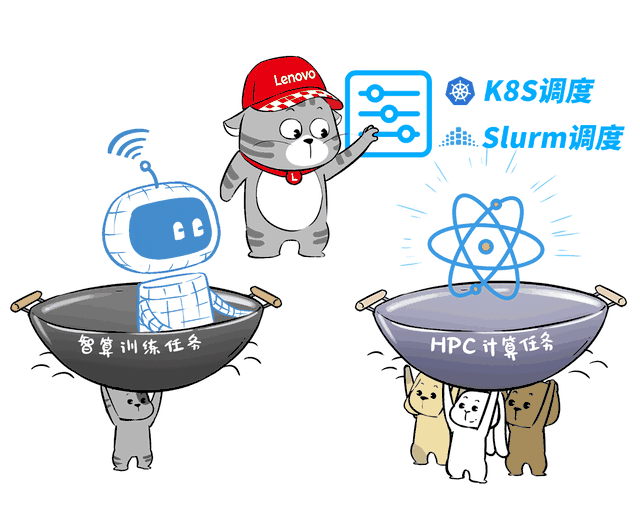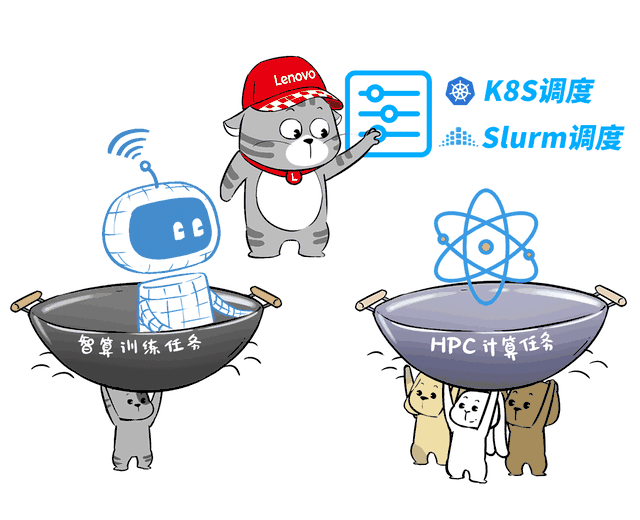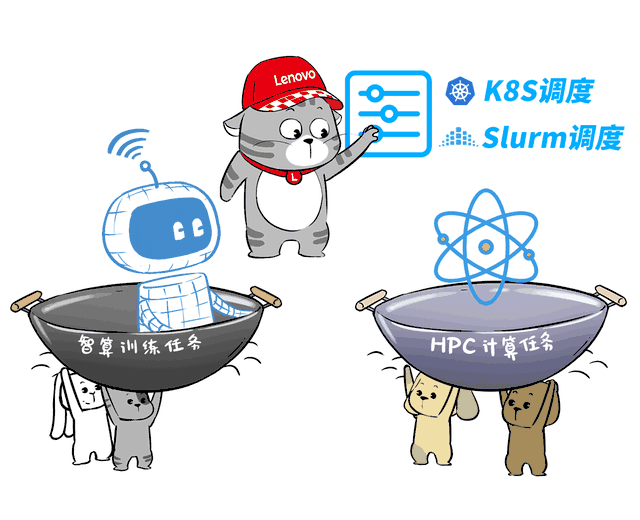
前面讲了半天异构智算、超智融合,这其中用到的一项核心能力,就是AI与HPC集群超级调度器。
智算集群与HPC集群的调度方式完全不同,前者通常基于K8S,而后者基于Slurm。

而联想超级调度器则可以完美操控这两套体系,切换AI和HPC的调度沟通,实现全局监控任务和动态共享资源。
这样,搞智算训推时,AI集群可以“借用”超算集群的空闲GPU节点,HPC业务也可以利用大模型技术来探索AI4S创新。
你可能觉得「超智融合」的需求很小众?对别人可能是这样,但对联想的客户来说却不一样。
联想是HPC TOP500份额十二连冠,拥有大量的高端超算客户。所以,联想深入场景实践,才能理解超智融合需求,并且搞定超智异构难题。

❷ 算力匹配魔方
基于海量的硬件评测和AI算子算法集成工作,联想构建了AI场景、算法、集群硬件三者匹配关系的「算力魔方知识库」。
基于这个“算力魔方”,可以标识AI场景、算法、集群配置这三者的匹配关系。

针对不同场景,实现全自动规划和调度。
实际使用时,用户只需输入场景和数据,即可自动加载最优算法和调度最佳集群配置。

❸ GPU内核态虚拟化
在AI推理和中小训练场景,为了避免大马拉小车,都会采用vGPU来扛活。
但业界通常在OS用户态对GPU进行虚拟化,算力损耗高达20%。

本次发布的万全异构平台,搭载了联想研究院开发的GPU内核态虚拟化算法。
对算力和显存的实现精准隔离(误差<3%),并在GPU驱动层完成资源调度,vGPU切分的颗粒度精细到1%。

❹ 联想集合通信算法库
在大规模智算集群中,如果网络通信慢,就会造成GPU闲置“摸鱼”,从而浪费昂贵的算力资源。

联想万全异构智算平台能自动感知集群网络拓扑,并选择和采用经联想增强的集合通信算法,使数据传输在最佳路径,提升吞吐,降低时延。
千卡规模集群下,网络通信效率提升超10%,集群规模越大,提升越显著。
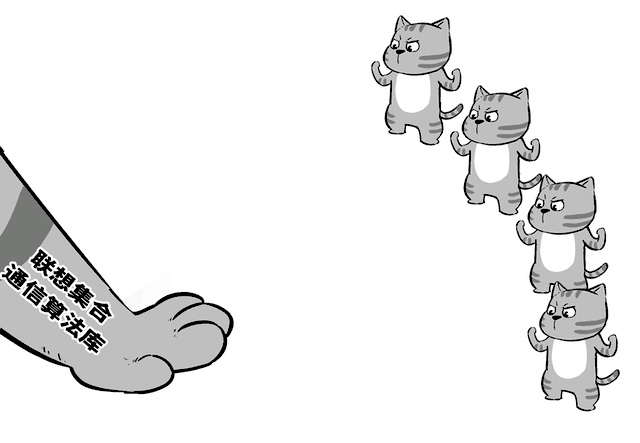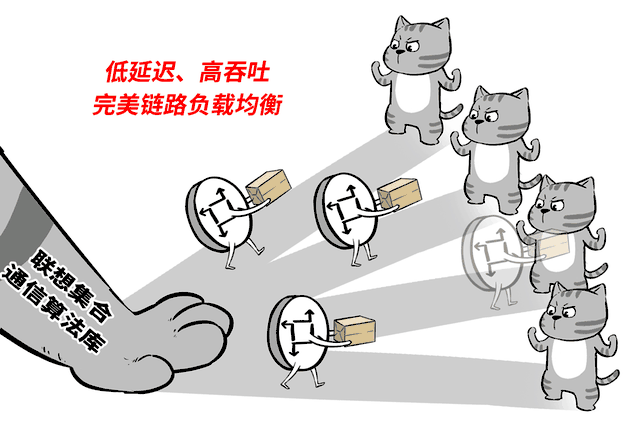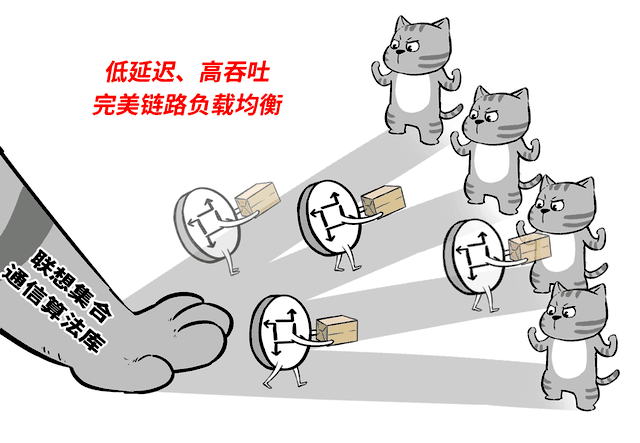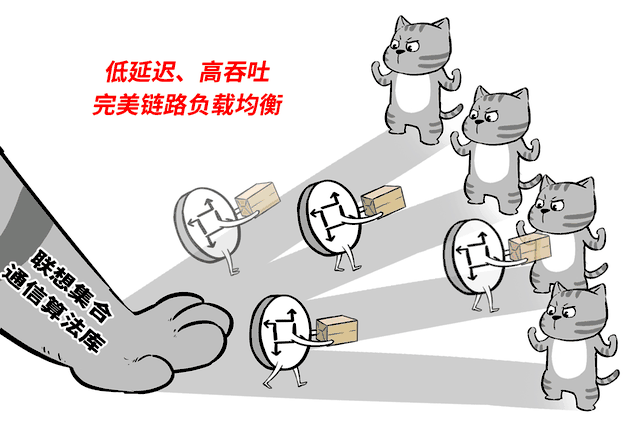
❺ AI断点续训技术
AI训练不怕断,就怕恢复时间长。
联想拿出了三招来改进断点续训效率,将恢复时间缩短到分钟级。
首先,针对故障特征来进行数据做多级备份,大幅精简备份数据量,同时令备份数据从最佳路径被提取。
第二,对大量AI训练故障进行特征采样,开发了预测AI训练故障的模型。

最后,联想万全异构智算平台集成了端到端的监控手段,对AI故障的抓取能够做到万无一失。

好了,读到这儿,你明白异构智算方案为啥会火了吧?因为不仅需求旺盛,而且业界的顶流玩家深度入局了。
作为“终极”异构智算方案,联想万全异构智算平台是 AI2.0时代一款神器,正在助力广大用户突破算效瓶颈,构筑智算基石。
