这个世界拼的是“认知”!
比如,AI火了这么多年,很多人还是有个惯性认知:通用算力,CPU好使;搞AI、搞智算,CPU不灵!

这个观点可谓大错特错!
事情的真相是,一个AI工程通常都分为两个阶段的:训练阶段和推理阶段,这俩阶段对算力的要求,天差地别。
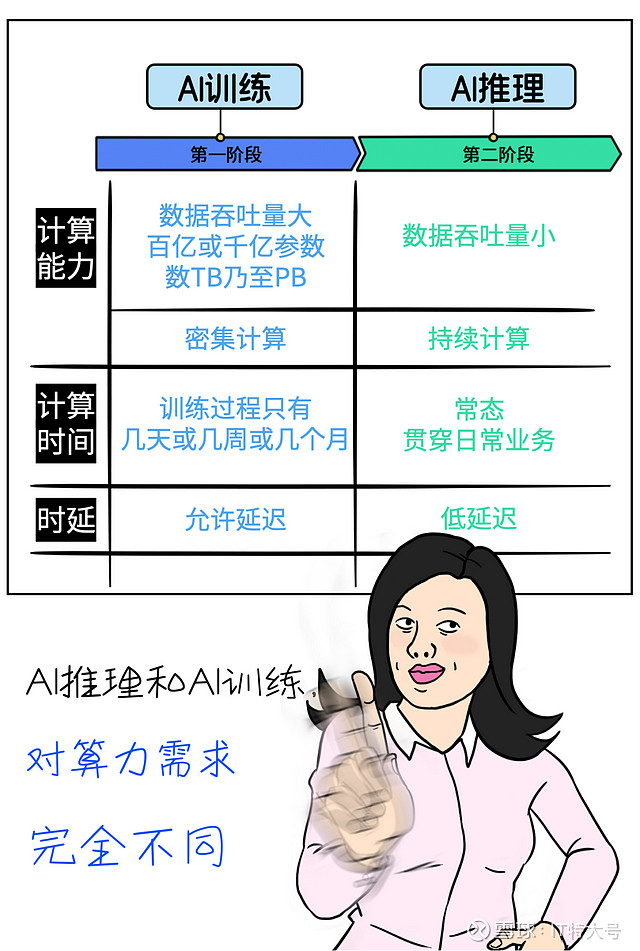
对于大多数企业级客户来讲,在通常情况下,很少训练,甚至不训练。
直接买一个标准的大模型或小模型回家,就像买标准软件一样,不需要训练,或者只是微调参数而已。

AI训练只是“一锤子买卖”,而AI推理直接贯穿业务全流程,是一种高频且长期的存在,业务运转的每分每秒都要发生。
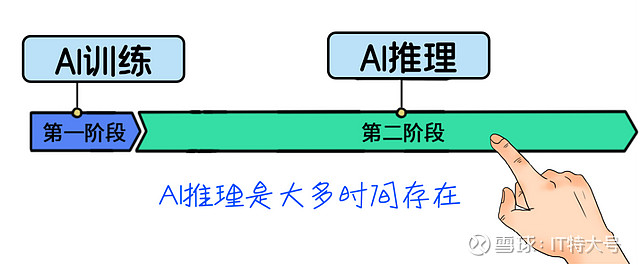
所以,懂行的客户会选择CPU来承担日常的AI推理工作。
只因为CPU的特性,完美契合推理需求。
好了,对齐基本的认知之后,我们再来详细探讨下,在AI推理业务中,应该如何选择CPU,才能取得最大收益↓

▼
要求1:能满足高速计算和低延迟?

推理过程需要高速读取和处理输入数据(如图像、视频、语音等),这要求CPU需具备高效数据吞吐能力和高速计算能力。
另一方面,对一些需要实时响应的应用(如自动驾驶等),需要在毫秒级别甚至更多时间完成推理过程,那么低延迟至关重要。
▼
要求2:是否已做了AI方面的优化?
比如,是否支持多种深度学习框架?是否有统一推理前端,不用担心底层硬件兼容问题?是否支持各种加速指令集?...
▼
要求3:TCO如何?能不能Hold住预算?

AI推理的吞吐量是否够大,综合TCO是否更好,成本是否更低?在相同的功耗下,是否能满足吞吐量的要求?
大家关注的问题,我都一一摆出来了,接下来就是捋捋业界有什么样的CPU能够搞定这些需求↓

选来选去,自然是AMD EPYC 处理器!
EPYC系列处理器是AMD推出的面向服务器和高性能计算(HPC)市场的CPU,在各大数据中心里,非常常见,大家都太熟了。

目前,AMD EPYC处理器已经“进化”到了第四代。
今天,就拿第四代的代表作—96 Core AMD EPYC 9654 CPU为例,讲讲为什么A厂的CPU在AI推理场景如此“能打”。

我们会从硬件、软件、成本、使用习惯、兼容性等几个方面来逐个拆解,带你深入了解这款AMD出品的AI推理神器↓

❶更多的核数,最多到128核,让AI推理算力满格
核数越多,通常意味着算力越强。
AMD EPYC 9654拥有超强96核,还有更夸张的,AMD EPYC 9754(bergamo ),拥有128核。
想象一下,这么多分身一起扛活,多带劲。

所以,AMD EPYC的搬砖能力(数据处理能力)相当牛掰,相对核数少的处理器,碾压优势很明显。
在AI推理时,96核CPU可以同时处理来自成千上万个源的数据推理请求,具备「高并发」能力和「低延迟」本领。
激发多核潜能,依赖于强大的CPU核心架构进行高效调度。
AMD采用了最新的ZEN 4核心技术架构,时钟速率提升14%,单核能力提升高达37%,每时钟周期执行指令数提升15%-24%。
这就好比,单个“小弟”能力更强,而且指挥每个“小弟”的效率又更高,那么组团打怪的本领自然提升了一大截。

如此一来,AMD EPYC就体现出更优的能效比,也就意味着更好的TCO。
比别人小弟多,小弟又个个超能打,而整体饭量(功耗)却不大,这样,同一台服务器可以承载更大的任务量。

❷更快的I/O,加速AI推理速度
前面讲的是“搬砖人多,搬砖劲儿大”,但搬砖还涉及到路程↓
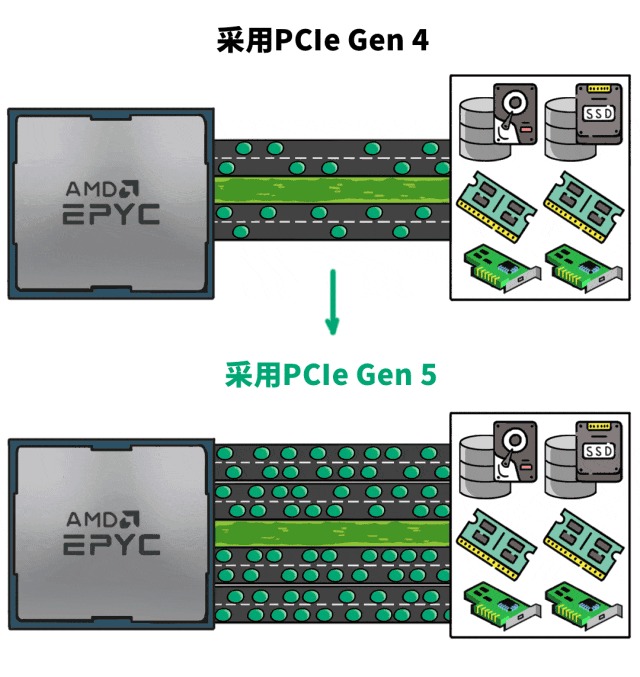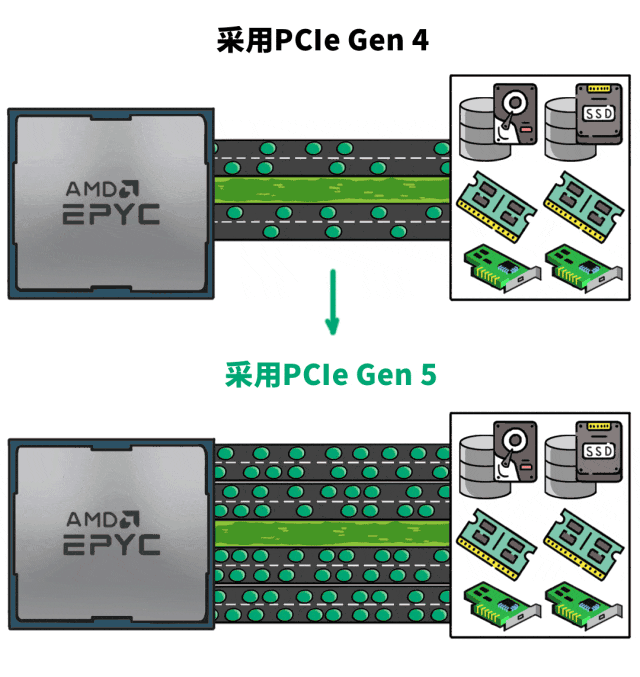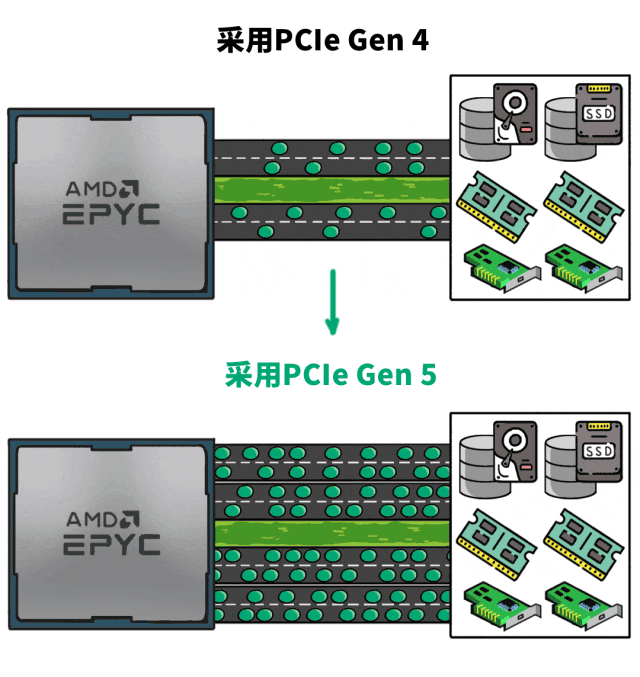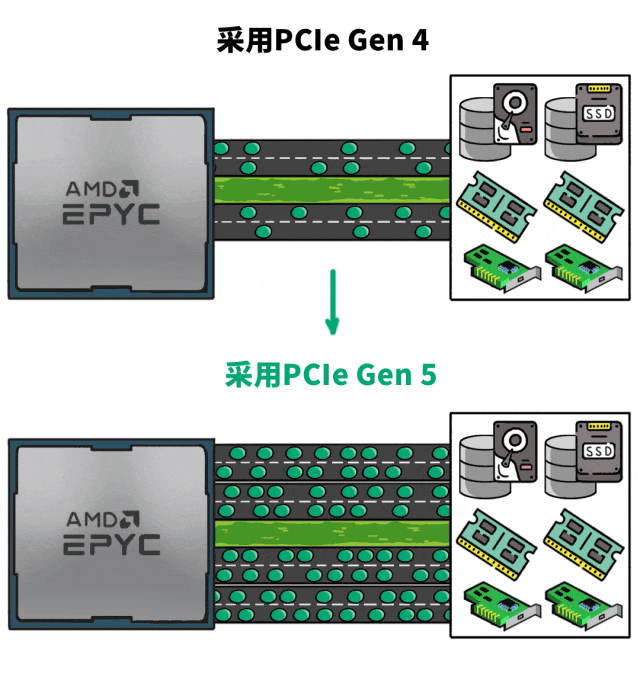
“正经”点儿说就是:在AI推理中,CPU需要与存储、网络以及其他硬件设备频繁交换数据,这要考量的就是CPU的I/O能力。
而单颗AMD EPYC 9654支持PCIe Gen 5 × 128,相当于大大拓宽了“高速路”,整成双向八车道。
这样,I/O吞吐就不会成为AI推理的瓶颈。
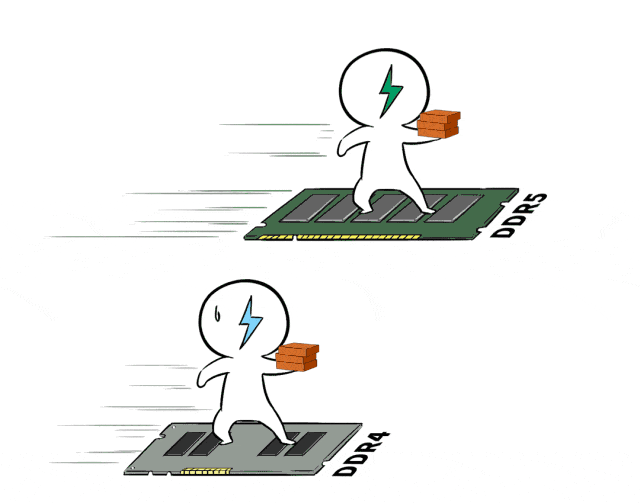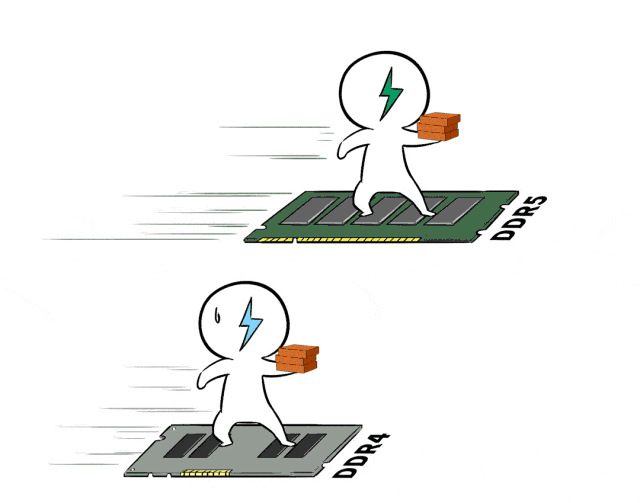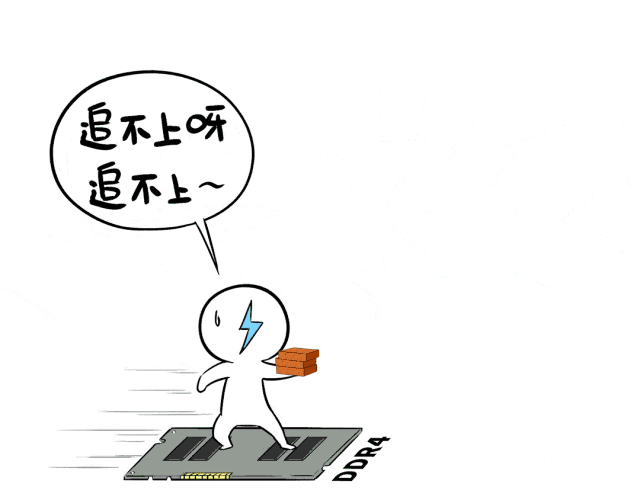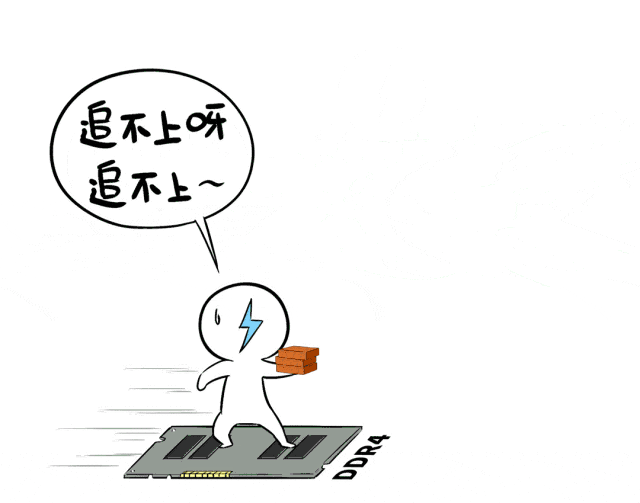
❸ 更快的内存,提升AI推理吞吐量
在执行AI推理任务时,内存的传输速率也是非常重要的指标。
AMD EPYC 9654支持最新一代的DDR5内存技术,单颗EPYC 9654处理器支持12个通道,遥遥领先。DDR5具备更高的数据传输速率,且每个DIMM的双通道设计,可以进一步提高内存访问效率,让“搬砖”延迟大大降低。
❹ 支持各种AI优化指令集,更加原生地支撑AI推理任务
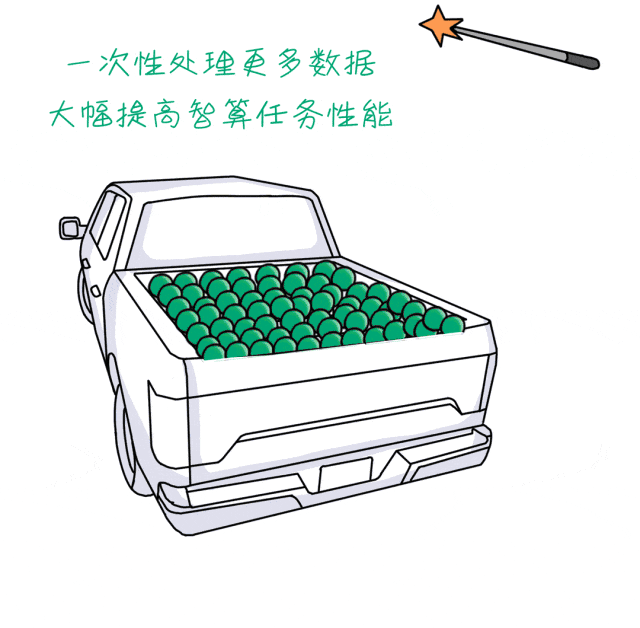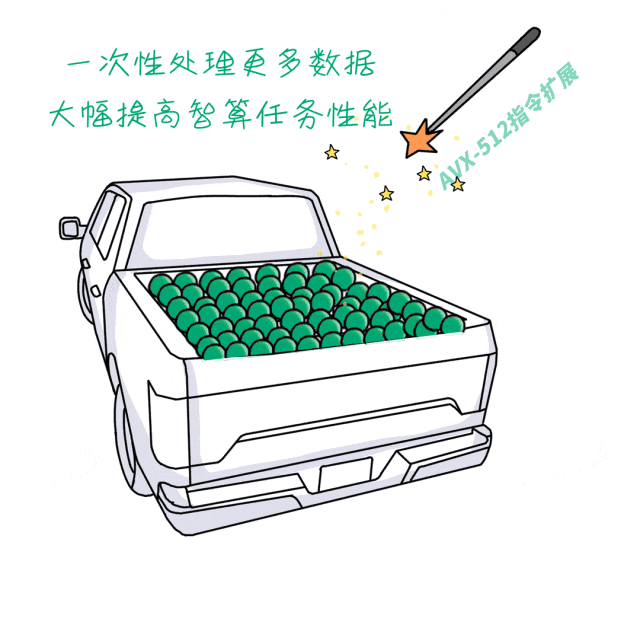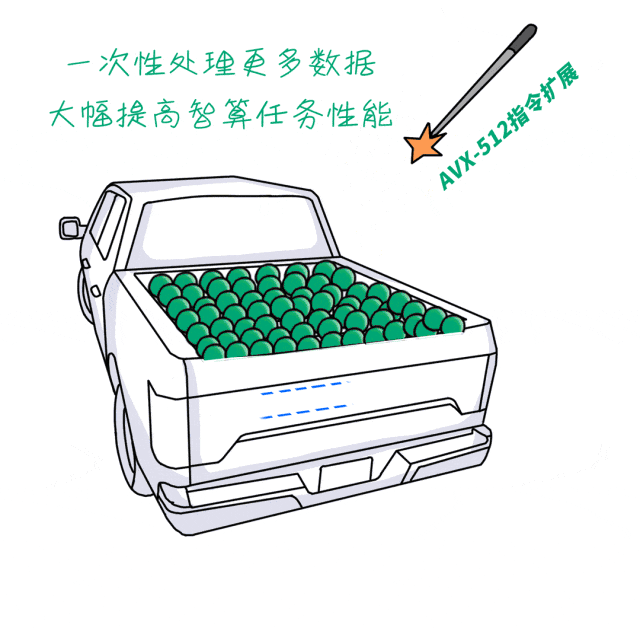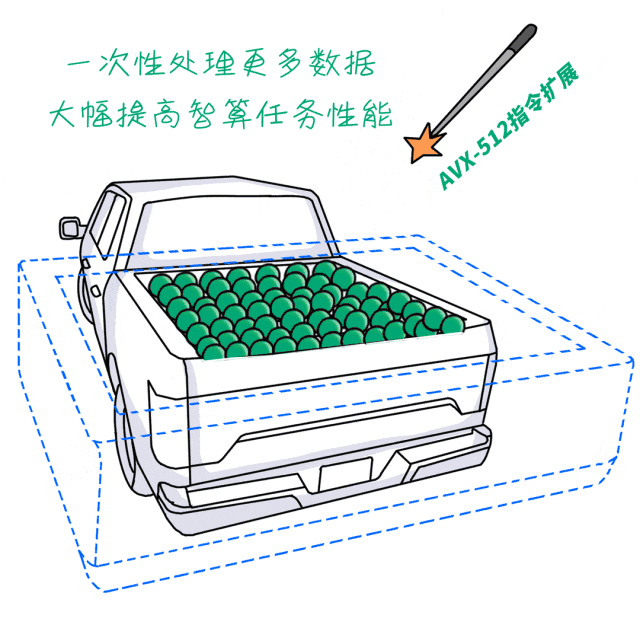
▌支持 AVX-512指令扩展:可以让CPU一次处理更多数据,允许更宽的向量操作。
这对加速AI推理中大量的矩阵和向量计算非常有用,可以显著提高执行卷积和矩阵乘法的速度。
▌提供VNNI组件:VNNI是一种特定的技术,专门用于加速AI计算。
VNNI则相当于改进了装卸货物的方法,让整个过程更有效率,这样在AI推理时,能够更快地得出结果。

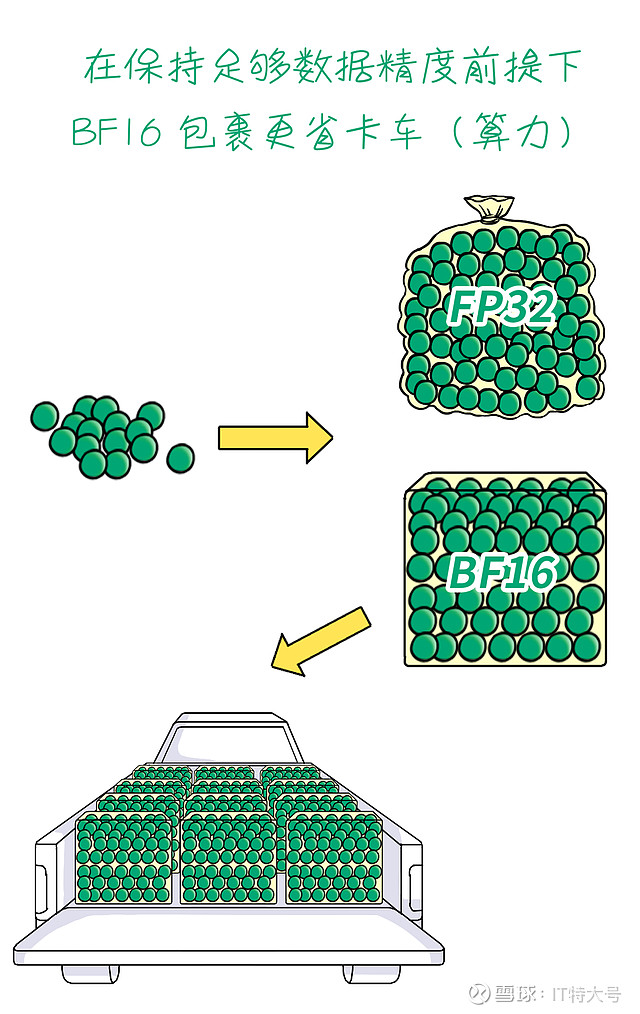
▌支持BF16数据类型:BF16是一种数据格式,用于深度学习或者其他AI计算,可以减少计算资源开销,同时保持足够的数值精度。
好比一种新的数据“打包”方法,在AI推理时,可在不牺牲结果质量的情况下加快推理速度。
为了能够帮助用户更容易地部署和执行深度学习模型的推理任务,AMD EPYC CPU还做了一系列的软件优化↓
❶ 提供机器学习图形编译器
能够识别和处理不同机器学习框架(TensorFlow、PyTorch、MXNet等)构建的模型和算法,开发者无需担心底层硬件的兼容性问题。

❷ 提供AMD优化的 CPU 库(AOCL)
AOCL涵盖了一组针对“Zen”核心架构优化的多个数值库,每个库都针对特定类型的计算任务进行了优化。
AOCL最腻害的地方,是能显著提高应用程序的计算速度。

❸ ZenDNN
这是AMD推出的一个优化的AI原语库,可以显著提高深度学习模型在这些处理器上的推理效率和性能。
ZenDNN非常适合大量数据和复杂计算的推理任务,比如:实时视频分析,进而监测交通流量、识别可疑行为等。
❹ Zen Software Studio
是AMD专为其Zen架构处理器设计的一套软件开发套件,用于支持高性能计算应用,如气候模拟、生物信息学分析等,提高大数据和复杂模型处理效率。
搞AI推理,更是小菜一碟。

❺ 兼容Windows和Linux上运行的软件
这种跨平台的兼容性让开发者省了不少事,不仅方便顺手,还不用担心任何性能损失。

说到兼容性,还有一点也很重要。
AMD EPYC处理器,完美兼容目前各种主流的CPU AI库,比如OneDNN和OpenVINO,还可以在不同的AI框架和库之间无缝切换。
企业开发者无需担心兼容性问题,确保了各种应用和解决方案的高效执行。


❶ 性价比更高:可利旧、可升级、可焕新
用户可以利旧原有CPU服务器,通过升级来获得性能提升。也可以购买基于AMD EPYC处理器的新服务器,其性价比相当感人。
❷ 更低的TCO成本:高能效比,永续服务
AI训练可能是“一顿操作猛如虎”,但AI推理任务一旦部署到生产环境,就是一个长期的投入,运维成本、能耗等都必须考虑周全。
AMD EPYC处理器能以较低的能耗完成高效的推理任务。

当然,还有最后一点,也是非常重要↓
跟各种偏门异构加速方案相比,x86 CPU服务器,大家太熟悉啦~

熟悉的架构、熟悉的界面、熟悉的环境、熟悉的运维...,这种熟悉,降低了技术门槛,降低了投入成本,也增强了掌控力!
所以,懂行、精明用户在AI推理时,当然是选择老朋友—AMD EPYC处理器!